英伟达都一万亿市值了,国产GPU现在发展的怎么样了?万字长文,有兴趣的进来简单了解一下。
最近,与GPU有关的几个科技新闻:一是英伟达NVIDIA市值超过一万亿美元,成为全球第一家市值过万亿的芯片公司;二是字节跳动今年向NVIDIA订购了超过10亿美元的GPU。
同时还有一个新闻,美国将浪潮列入所谓「实体清单」。浪潮是人工智能服务器的重要供应商,其市占率多年位列全球前三、中国第一。列入实体清单,意味着无法获得美国的先进芯片,影响国内大量下游公司,对我国人工智能行业造成较大影响。而早在2022年8月31日,美国就已经禁止NVIDIA的A100、H100系列和AMD的MI 250系列及未来的高端GPU产品销往中国。美国对中国人工智能行业的打压是不遗余力的,我国虽然顶着一个「全球算力第二」的头衔,但算力的基础设施是很薄弱的。
上回聊过国产CPU,这次我们来简单了解一下国产GPU。内容太多,或有纰漏之处,希望小伙伴多多包涵。
术语表、缩写表
HPC: High Performance Computing,高性能计算。
PCIe: PCI-Express接口,可以简单理解为GPU和CPU之间的接口。
Ray Tracing: 光追。该技术是NVIDIA在2018年推出的,它利用实时光线追踪技术,可以更加真实地模拟光线在场景中的传播和反射,从而提高了游戏的视觉效果和真实感。
GPU: Graphics Processing Unit,图形处理单元,俗称显卡。
GPGPU: General-Purpose Graphics Processing Unit,通用图形处理单元。GPGPU主要对海量数据的并行计算做了优化,使其更适合AI模型训练等领域。
FPGA: Field Programmable Gate Array,现场可编程门阵列,对于这种芯片,用户可以用代码对物理电路进行修改(比如通过对部分线路加载超过负荷的电流使其熔断,当然现在有多种更先进的方法来达成对同一块硬件电路的多次编程)
ASIC: Application-Specific Integrated Circuit,专用集成电路,例如你可以设计一款ASIC芯片专门用于矩阵乘法。它和GPU的区别在于,GPU比它通用,例如可以进行图片渲染等等。它和FPGA的区别在于,其硬件电路在出厂后无法修改。
OpenGL: Open Graphics Library,是一个跨平台的图形API,允许开发者在不同操作系统和硬件上创建高性能的图形应用程序。
DirectX: 是微软开发的多媒体API,允许开发者在Windows平台上创建高性能的多媒体应用程序。
OpenCL: Open Computing Language,一种跨平台的并行计算框架,允许开发者基于OpenCL所提供的接口开发并行计算程序并运行与指定的设备(如GPU)上。
CUDA: Compute Unified Device Architecture,是NVIDIA的一种并行计算框架,与OpenCL类似,但OpenCL是跨平台,而CUDA只能用于NVIDIA GPU。
图像渲染、计算加速
GPGPU、通用GPU、全功能GPU、图形GPU、渲染GPU、GPU+、……,这几年,冒出很多云山雾罩的名词。这里我们简单点,把GPU按用途划分成两类:
- 图像渲染:这部分就是传统的显卡,主要服务于图形图像、游戏、视频等方面。全球主要玩家是NVIDIA、AMD、Intel。Intel凭借CPU优势占据集成显卡60%以上市场份额。而独立显卡部分,最新的数据,NVIDIA占据84%市场份额,AMD为12%。
- 计算加速:这部分相当于大算力芯片,主要服务于AI模型训练和推理等新兴的算力需求。全球主要玩家是NVIDIA、AMD。其中NVIDIA处于统治地位,市场份额超过97%。
图像渲染部分,经过了20年的演化,存在大量复杂算法和各种专利壁垒,同时它包含多种专用的硬件单元,如光栅处理单元、纹理单元、光线追踪核心等,硬件结构复杂。这使得图像渲染GPU自研难度是比较高的,因此,国内专注于图像渲染GPU,尤其是消费级桌面GPU的芯片公司比较少。
计算加速部分,简单解释一下,GPU最早被用于图像渲染,主要的工作说白了就是不停的计算每一个像素点的颜色和亮度等数值,这种类型的计算很适合并行处理,于是GPU就针对性地使用大量计算核心(现代CPU的核心数是4-16个,而GPU的核心数是数千个),使得它可以一次同时处理成百上千的像素点,提高图像渲染的效率。后来,随着AI模型训练和推理的兴起,人们发现这个过程中存在很多矩阵加法、乘法等可以并行处理的计算,也很适合使用GPU来计算,于是GPU开始被用于AI行业,并不断的对它的计算能力进行加强,事实上形成了广义GPU里的一个新分支,也就是我们说的「计算加速GPU」。较之图像渲染GPU,在计算加速GPU方面,国内的公司相对多一些,毕竟AI正当红。
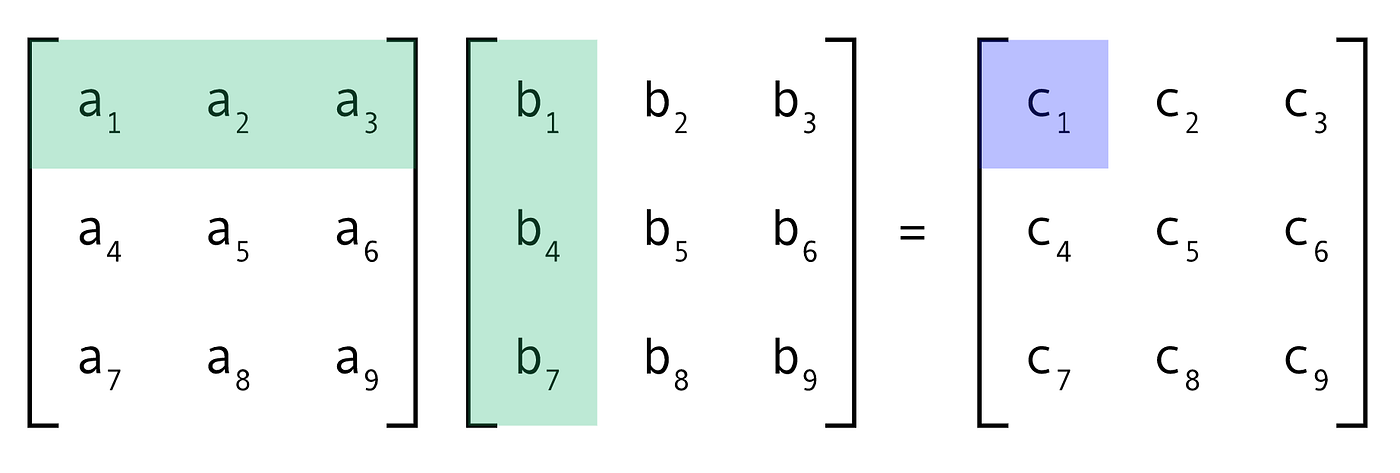
顺便帮大家简单复习一下矩阵运算,可以看到最终得到的结果中,每一个数值都是可以单独计算的(c1=a1*b1+a2*b4+a3*b7,c2=a1*b2+a2*b5+a3*b8,……),互相没有依赖,因此可以并行化处理。
图形接口、显卡驱动
常见的图形接口包括OpenGL、DirectX、Vulkan,其他的还有苹果的Metal、AMD的Mantle、英特尔的One等。图形接口,举个例子,市面上有大量不同型号的显卡,每个显得操作指令有可能都不一样,这个时候,如果有一款游戏需要创建一个2D或者3D的图形,如何适配不同的显卡将成为一个大问题。因此游戏和显卡之间的交互需要一个规范,而OpenGL、DirectX、Vulkan就是一种规范,有了这个规范,游戏开发者只需要调用这些规范库里定义好的接口就行,不需要关注底层是哪种显卡。
我们说OpenGL、DirectX、Vulkan是一种规范,意味着它们并没有提供真正的实现,真正功能的实现,则是在显卡厂商提供给你的驱动程序中。用程序员的话来比喻则是:OpenGL、DirectX、Vulkan相当于一个定义了一些接口,而显卡厂商提供驱动程序是对这些接口的实现,因此不同的显卡,才需要不同的驱动程序。
由于GPU除了传统的图像渲染之外,还被用于计算加速,因此,除了图形接口,我们还有计算加速相关的编程接口(或者说「框架」),比较有名的有OpenCL(Open Computing Language),一种跨平台的并行计算框架,允许开发者基于OpenCL所提供的接口开发并行计算程序并运行与指定的设备(如GPU)上。
另外一个是CUDA(Compute Unified Device Architecture),NVIDIA 2006年提出的一种并行计算框架,与OpenCL类似,但OpenCL是跨平台,而CUDA只能用于NVIDIA GPU。CUDA是目前最广泛使用的并行计算框架,毕竟NVIDIA在计算加速GPU上占据绝对的霸主地位。下面的伪代码演示如何使用CUDA库将某些特定的任务指定给GPU来完成。
t = troch.tensor([1,2,3]) // 该tensor是在CPU上创建的,对它的操作都将在CPU上进行
t = t.cuda() // 该tensor被转移到GPU上,后续的操作都将在GPU上进行
同样的,OpenCL、CUDA只是一个并行计算框架,真正与显卡的交互仍然需要借助显卡驱动,所以,现代的显卡驱动,不仅要对OpenGL、DirectX、Vulkan这些图像相关的接口进行支持,还需要对OpenCL、CUDA这些与计算加速相关的接口的支持。可以看到,工作量转移到了显卡驱动的开发了,所以显卡驱动的开发就越来越复杂困难,不信你问问隔壁英特尔。
不论CPU还是GPU,生态都很重要,二者的生态建设都是顶级难度,如果硬要比较的话,因为有现成的接口或者说框架,我个人觉得GPU的生态建设难度还是稍微的低一丢丢。图像渲染方面,基本上把主流的几个图像相关的编程接口支持好就不错了。计算加速方面,可以用OpenCL,但是目前AI领域基本上是NVIDIA CUDA所垄断,也就是说各大厂在AI模型训练上基本都是使用的CUDA库,如果国产GPU想要这些大厂用你的显卡,通常有两种方案,一种就是兼容CUDA接口,这个是不容易的,尤其CUDA还在不断更新中;还有一种是提供工具以便客户可以直接将代码迁移到你的计算加速接口上,摩尔线程走的就是这个路子。
英伟达显卡
NVIDIA的显卡主要分为3类:
- GeForce:面向3D游戏以及其他普通消费领域。主要品牌号有GTX、RTX。
- Quadro:面向专业图形设计,如CAD等
- Tesla:面向计算加速,主要是AI领域
通常我们说NVIDIA的消费级显卡,是指的GeForce系列。先简单介绍一下英伟达GeForce显卡的命名,这里只说10系及之后的,更早的显卡型号挺混乱的,而且现在也很少有人提及了,这里就不说了(主要是我也搞不清楚)。
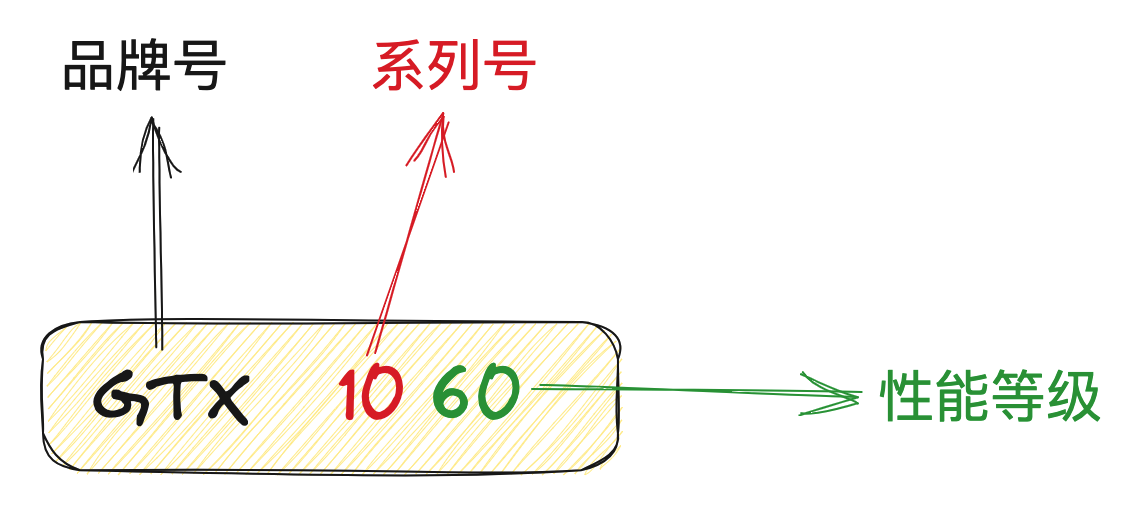
首先,10系和16系品牌号都是GTX,而20系及以后都是RTX,因为从20系开始,NVIDIA给显卡增加了「光追 Ray Tracing」的特性,于是便以「R」打头。
其次,在GTX/RTX之后,是4位数字,比如 GTX 1060,这4位数中前两位是系列号,10就表示「10系」;后两位表示性能等级,数字越大,表示性能越强。
- 10-40:低性能显卡,满足基本的日常需求,俗称「亮机卡」。
- 50 :中性能显卡,可以基本满足当年主流游戏以及主流应用。
- 60-90:高性能显卡,其中60俗称「甜品卡」,也就是性能不错,价格也不是太高,通常60卖的都比较好。
有些型号还在4位数之后带「Ti」或者「Super」标志,可以看做是原来型号的加强版。
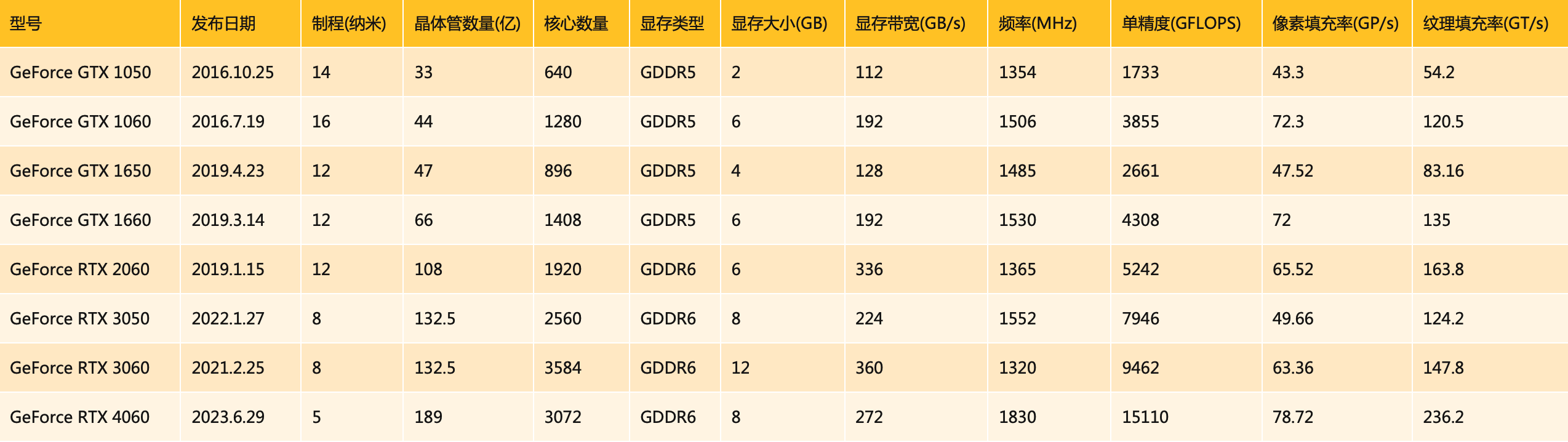
由于英伟达的消费级显卡常常被用来作为横向比较的标杆,我整理了一个简单的表格,列了一些GTX/RTX 10系及以后的显卡(主要是中性能卡和甜品卡),这样大家对这些耳熟能详的显卡的重要性能指标有一个整体的印象。主要数据来源是维基,一些型号有不同的版本,比如GTX 1050就有两三个版本,没办法不一一列出,挑选了最早发布的版本。
这里的核心数量是指GPU芯片内集成的处理器数量,核心数量越多,处理性能越强。另外,单精度是指单精度浮点运算的性能,这是显卡计算性能的重要指标。其他像像素填充率、纹理填充率则是与图像渲染性能相关的指标。
另外需要知道,像GTX 1650这样的显卡,就已经能够流畅地运行眼下几乎所有的主流网络游戏了。如果有哪一款国产GPU能在实测中达到与GTX 1650相当的水平,那绝对是了不起的成绩。
国产GPU
相对于国产CPU,国内对GPU的重视程度相对较低,国产GPU起步更晚,与国际大厂差距很大。不过,最近几年由AI以及高性能计算HPC带来的算力需求增长,加上资本的投入,使得国内出现GPU的创业热潮,不少GPU初创公司融资高达数10亿元,同时也吸引了英伟达和AMD等国际厂商技术人才的加盟,进入了相对较快的发展期。当然,另外一个大家都知道的原因就是美国的科技打压,导致许多硬件的供应链被切断,其中当然也包括GPU,使得国内企业不得不走上了自主化道路。
景嘉微
景嘉微的技术核心团队来自于国防科技大学,依靠军工业务图形显控模块芯片起家,后来转型民用市场,2016年上市,是国内涉足GPU行业的老牌厂商,也是国内首家成功研制国产GPU芯片并实现大规模工程应用的企业。最早推出的JM5系列帮助我们国家的军队替换下了大量古老的ATI显卡,后续又推出了JM7系列、JM9系列。
其中JM9系的像素填充率为32GP/s,单精度浮点性能为1.5TFLOPS,对照前面给出的NVIDIA显卡,硬件指标勉强可对标GTX 1050。关于景嘉微GPU的指标官网上都没有给出,前面的是网上的资料,可能有不准确的地方,另外,我看京东上卖的JM9230,单精度性能只有1.2TFLOPS?
JM9系,这个显卡玩主流游戏估计暂时是别想了,AI训练相关的计算加速也不行(毕竟主要还是侧重图像渲染),不过看网上实测视屏播放看着还可以,普遍反映是比JM7系好很多,处于亮机卡水平,对于一款纯自主研发的GPU来说,还是需要鼓励一下的。对了,景嘉微目前也已被美国商务部列入「实体清单」,可以看做是一种肯定吧。
芯动科技
芯动科技是采用Imagination GPU授权,Imagination之前还给苹果提供过GPU授权,该公司目前是中国资金控股。
芯动目前主要发布了两款显卡:
- 风华一号:「国内第一款4K高性能数据中心显卡GPU」(发布会标题),分A型卡(单芯)、B型卡(双芯)两款,旗舰款B型卡单精度浮点性能为10TFLOPS、像素填充率320GP/s。这个字面性能达到了RTX 2080的水平了。
- 风华二号:「国内第一款4K高性能数据中心显卡GPU」(发布会标题),单精度浮点性能1.5TFLOPS、像素填充率为48GP/s,单精度性能接近GTX 1050。
不过,风华二号的功耗是4~15瓦,再对比NVIDIA GTX动辄一两百瓦的功耗,估计实测性能与GTX 1050的差距会比较大。据说风华三号也已经设计完成,届时会增加光追Ray Tracing特性。
沐曦
沐曦于2020年9月成立于上海,其GPU团队很多是前AMD的工程师,该公司的GPU主要面向的是计算加速。2023年,旗下曦思N100实现量产,这是一款面向云端数据中心应用的人工智能推理GPU,单卡算力达80TFLOPS(FP16)、160TOPS(INT8),对比一下,NVIDIA A100(目前全球主流的计算加速GPU)是312TFLOPS(FP16)和624TOPS(INT8)。
海光
海光在之前介绍CPU的时候也介绍过,除了CPU,海光也有GPU业务,主要是面向计算加速。旗下的深算一号DCU(Deep Computing Unit 深度计算器)据说可以达到NVIDIA A100 70%的性能水平。
前面说到了在计算加速方面,下游用户主要就是围绕这NVIDIA的CUDA来开发的,这也形成了生态壁垒。由于海光的很多授权(包括CPU指令集架构授权)都来自AMD,因此海光GPU采取了兼容ROCm(ADM GPU的计算接口)的方式,不过ROCm与CUDA相似,CUDA用户可以以较低代价进行迁移,在一定程度上克服CUDA的生态壁垒。
摩尔线程
摩尔线程无疑是目前国产显卡里最火的一家,没有之一。它成立于2020年10月,创始人是原NVIDIA全球副总裁、中国区总经理张建中,核心创建团队基本都来自NVIDIA。摩尔线程在图像渲染和计算加速两个方向都有布局。
到目前为止,摩尔线程发布了面向数字办公的桌面显卡MTT S10/S30/S50、第一款国产游戏显卡MTT S80、针对数据中心的全功能MTT S2000/S3000。就在最近(2023.5.31),摩尔线程还发布了S70游戏显卡,相当于是S80的弱化版。
S80显卡核心数量4096个,单精度浮点性能14.4TFLOPS,纸面指标可以说是相当不错了,实测的话,在《CS:GO》《英雄联盟》等主流网游可以流畅运行(这两天看新驱动上实测米哈游的《星穹铁道》也能流畅运行。话说这有一个
摩尔线程MTT S80测试合集,有兴趣的小伙伴可以看看)。目前其主要问题是在驱动的优化上,导致硬件的潜力没有发挥出来,部分主流游戏和一下基准测试还跑不了。摩尔线程的驱动也保持着较快的更新速度,不过驱动的优化工作不可能一蹴而就,需要时间。
计算加速部分,针对NVIDIA围绕自家显卡的CUDA生态壁垒,摩尔线程开发了一套迁移工具,可以将使用CUDA语言开发的代码经过重新编译之后运行在自己的MUSA的GPU上,也可以在一定程度上克服CUDA的生态壁垒。
壁仞科技
壁仞科技成立于2019年9月,主要面向计算加速,截至目前该公司总融资额超50亿元。
2022年8月,壁仞科技正式发布首款通用GPU芯片BR100,创下全球算力纪录,16位浮点算力达到1000T以上、8位定点算力达到2000T以上,单芯片峰值算力达到PFLOPS级别。甚至与英伟达最新发布的 4nm 旗舰 H100 相比,BR100 的纸面性能数据也毫不逊色。2022年9月9日,全球权威AI基准评测MLPerf V2.1推理最新评测成绩公布,浪潮AI服务器成功搭载国产GPU芯片厂商壁仞科技自研的高端通用GPU,在BERT和ResNet50两项重要任务中取得了8卡和4卡整机的全球最佳性能。
不过在今年(2023)二月份,网传壁仞裁员,普遍认为是壁仞使用的7纳米高端制程受到台积电断供的重创。这个后续会如何发展还得再观察,目前只能给壁仞说一句加油。
格兰菲
格兰菲早期是兆芯(兆芯,这个上一回介绍CPU的时候说过了)的子公司,后来独立出来,专注GPU业务。格兰菲目前最新的GPU型号是Arise-GT10C0,单精度性能1.5TFlops,像素填充率48GP/s,主频500Mhz,工艺28nm。单看单精度计算性能和像素填充率接近GTX 1050的水准,纹理填充还高一些。不过实测据说只有GT 630的水平,那时NVIDIA 2012年的产品了。
Arise-GT10C0在网上也是被许多「懂王」斥为电子垃圾,不过我个人是觉得,有多少能力办多少事,只要是踏实在做事就好,况且,3个馒头能吃饱,前两个就可以不吃?
天数智芯
天数智芯成立于2015年12月,面向计算加速,是国内首家GPGPU高端芯片及超级算力提供商。2021年3月,公司发布了国内首款通用GPU——天垓100,单精度浮点计算性能37TFLOPS、半精度浮点计算性能147TFLOPS、整型计算性能295TOPS(NVIDIA A100分别为19.5TFLOPS、312TFLOPS、624TOPS)。
结语
对于图像渲染GPU,虽然国内有个别厂家的硬件参数看起来已经相当不错了,但是需要指出的就是,硬件参数很重要,但不是唯一重要的,软件生态尤其是显卡驱动,还需要一段时间好好打磨。目前从各类实测视屏看来,摩尔线程是进展比较快的,部分主流游戏可以流畅运行了,驱动程序也在不断更新中。
对于计算加速GPU,个人觉得其研发和生态建设难度要比消费级显卡要相对小一些(只是相对)。这个方向的GPU面临的比较大的问题是美国对芯片制程的制裁,例如壁仞的计算加速芯片就受到了台积电7纳米断供的影响,这属于真正的卡脖子了。关于制程,目前官方的消息是,2023年第一季,中芯国际14纳米的良率达到80%以上,虽然距离台积电的90%+还有差距,但是能达到80%以上的良率就意味着可以进行商业量产了,所以14纳米的国产替代会比较展开。下一步是10纳米,难度是比较高的,14纳米的良率从60%提高到80%,中芯国际花了5-6年,10纳米不知道要花多长时间,更不用说7纳米及以下了。
有人肯定要说光刻机了,这个要分开看,首先是荷兰ASML的EUV肯定是拿不到了,不过DUV目前还是卖的,我们可以先用着,且走且看。至于国产替代,目前消息是90纳米的光刻机已经过验收了(?),这个还有比较长的路需要走。
眼下,作为一名科技爱好者,我抱持的是在比较充分了解一件事情的前提下,做到既不妄自尊大,避免每天被各种「震惊」、「突破」、「厉害了」所污染;也不妄自菲薄,就好比贸易战刚开始的时候,网上好多人就说美国别的不用,只要切断我们和互联网的几个根服务器我们就完蛋了,其实了解过DNS原理的小伙伴就知道这种说法很可笑。对于芯片,花点时间了解它,就会知道我们面临的是工程问题,而不是底层物理原理的问题,就好比对方是一个30年经验的老师傅,我们是个新人,他打磨的工件就是比我们打磨的好,这个没有办法,我们需要时间,加班加点练呗。
(欢迎扫描上图二维码关注公众号,可自动获得ChatGPT访问地址(本人自己搭建的跳板,可免费使用))
- [转帖]双剑合璧:CPU+GPU异构计算完全解析
引用自:http://tech.sina.com.cn/mobile/n/2011-06-20/18371792199.shtml 这篇文章写的深入浅出,把异构计算的思想和行业趋势描述的非常清楚,难得 ...
- OpenCL入门:(二:用GPU计算两个数组和)
本文编写一个计算两个数组和的程序,用CPU和GPU分别运算,计算运算时间,并且校验最后的运算结果.文中代码偏多,原理建议阅读下面文章,文中介绍了OpenCL相关名词概念. http://opencl. ...
- CPU与GPU区别大揭秘
http://blog.csdn.net/xiaolang85/article/details/51500340 有网友在网上提问:“为什么现在更多需要用的是 GPU 而不是 CPU,比如挖矿甚至破解 ...
- CPU与GPU区别 通俗易懂
转:https://blog.csdn.net/xiaolang85/article/details/51500340 有网友在网上提问:“为什么现在更多需要用的是 GPU 而不是 CPU,比如挖矿甚 ...
- 构建可扩展的GPU加速应用程序(NVIDIA HPC)
构建可扩展的GPU加速应用程序(NVIDIA HPC) 研究人员.科学家和开发人员正在通过加速NVIDIA GPU上的高性能计算(HPC)应用来推进科学发展,NVIDIA GPU具有处理当今最具挑战性 ...
- 企业实践 | 国产操作系统之光? 银河麒麟KylinOS-V10(SP3)高级服务器操作系统基础安装篇
[点击 关注「 全栈工程师修炼指南」公众号 ] 设为「️ 星标」带你从基础入门 到 全栈实践 再到 放弃学习! 涉及 网络安全运维.应用开发.物联网IOT.学习路径 .个人感悟 等知识分享. 希望各位 ...
- CPU发展史和相关品牌介绍
CPU发展史和相关品牌介绍 CPU发展已经有40多年的历史了.我们通常将其分成 六个阶段. (1)第一阶段 (1971年-1973年) .这是4位和8位低档微处理器时代,代表产品是Intel 4004 ...
- thinkPHP入门
什么是框架 框架就是一定结构的代码,框架提供一个开发web程序的基础架构以及常用的功能 代码,PHP框架的web程序开发拜倒了流水线上. php框架就是一定要按别人规定好的架构编写. php开发框架有 ...
- Thinkphp:有你真好
ThinkPHP是为了简化企业级应用开发和敏捷WEB应用开发而诞生的.最早诞生于2006年初,2007年元旦正式更名为ThinkPHP,并且遵循Apache2开源协议发布.ThinkPHP从诞生以来一 ...
- 对于syncedmen类的代码分析
对于数据在cpu与GPU之间同步的问题,caffe中用syncedMemory这个类来解 决:在GPU模式下,并且使用CUDA时,可以用CaffeMallocHost函数与CaffeFreeHost函 ...
随机推荐
- [BUUCTF]Pwn刷题记录
本部分内容长期更新,不再创建新文章影响阅读 rip 根据IDA加载入main函数声明发现s数组距离rbp的距离为F,即为15,这里的运行环境是64位,所以应当将Caller's rbp的数据填满,在这 ...
- [ElasticSearch]#解决问题#修改Search Guard密码时 报错:ERR: Seems there is no Elasticsearch running on localhost:9300 - Will exit
问题复现 [root@es2 tools]# ps -ef | grep elasticsearch 9200 22693 1 1 09:31 ? 00:04:54 /usr/bin/java -Xm ...
- [Chrome]插件的导出与导入[转载]
1 文由 毕竟是在墙内,暂时又没有有效的FQ工具,换设备了,但需要使用原先旧设备下载的插件.只能出此下策liao~ 2 导出插件 step1 Chrome: 进入插件管理界面 Chrome: 更多工具 ...
- python:selenium爬取boss网站被关小黑屋
问题描述:使用selenium访问次数过多,被boss反爬封掉IP,这种方式有什么好一点的解决方法,首次可以用图形验证解封,今天访问次数过多,被关进了小黑屋 首次让我用图形界面解封 不过还好,手动解封 ...
- Semantic Kernel 入门系列:📅 Planner 计划管理
Semantic Kernel 的一个核心能力就是实现"目标导向"的AI应用. 目标导向 "目标导向"听起来是一个比较高大的词,但是却是实际生活中我们处理问题的 ...
- DRF的限流组件(源码分析)
DRF限流组件(源码分析) 限流,限制用户访问频率,例如:用户1分钟最多访问100次 或者 短信验证码一天每天可以发送50次, 防止盗刷. 对于匿名用户,使用用户IP作为唯一标识. 对于登录用户,使用 ...
- 小程序TS报错 "无法重新声明块范围变量。此处也声明了xx "
初学者简单的方法,目前还没有遇到问题 想法很简单,当export导出,骗eslint认为是一个模块. 如果有新的问题欢迎留言,我也在学习 1 import utilsApi from '../util ...
- 考前必备fa宝——对拍
2022.11.24:晚上zxs学长发来了他的博客,所以我仿照写一篇. https://www.cnblogs.com/Dita/p/duipai.html 对拍 对拍这个东西,就是可以比较两份代码跑 ...
- C++ Primer 5th 阅读笔记:前言
机器效率和编程效率 Its focus, and that of its programming community, has widened from looking mostly at machi ...
- SpringBoot 使用 Sa-Token 完成注解鉴权功能
注解鉴权 -- 优雅的将鉴权与业务代码分离.本篇我们将介绍在 Sa-Token 中如何通过注解完成权限校验. Sa-Token 是一个轻量级 java 权限认证框架,主要解决登录认证.权限认证.单点登 ...