python:selenium爬取boss网站被关小黑屋
问题描述:使用selenium访问次数过多,被boss反爬封掉IP,这种方式有什么好一点的解决方法,首次可以用图形验证解封,今天访问次数过多,被关进了小黑屋
首次让我用图形界面解封
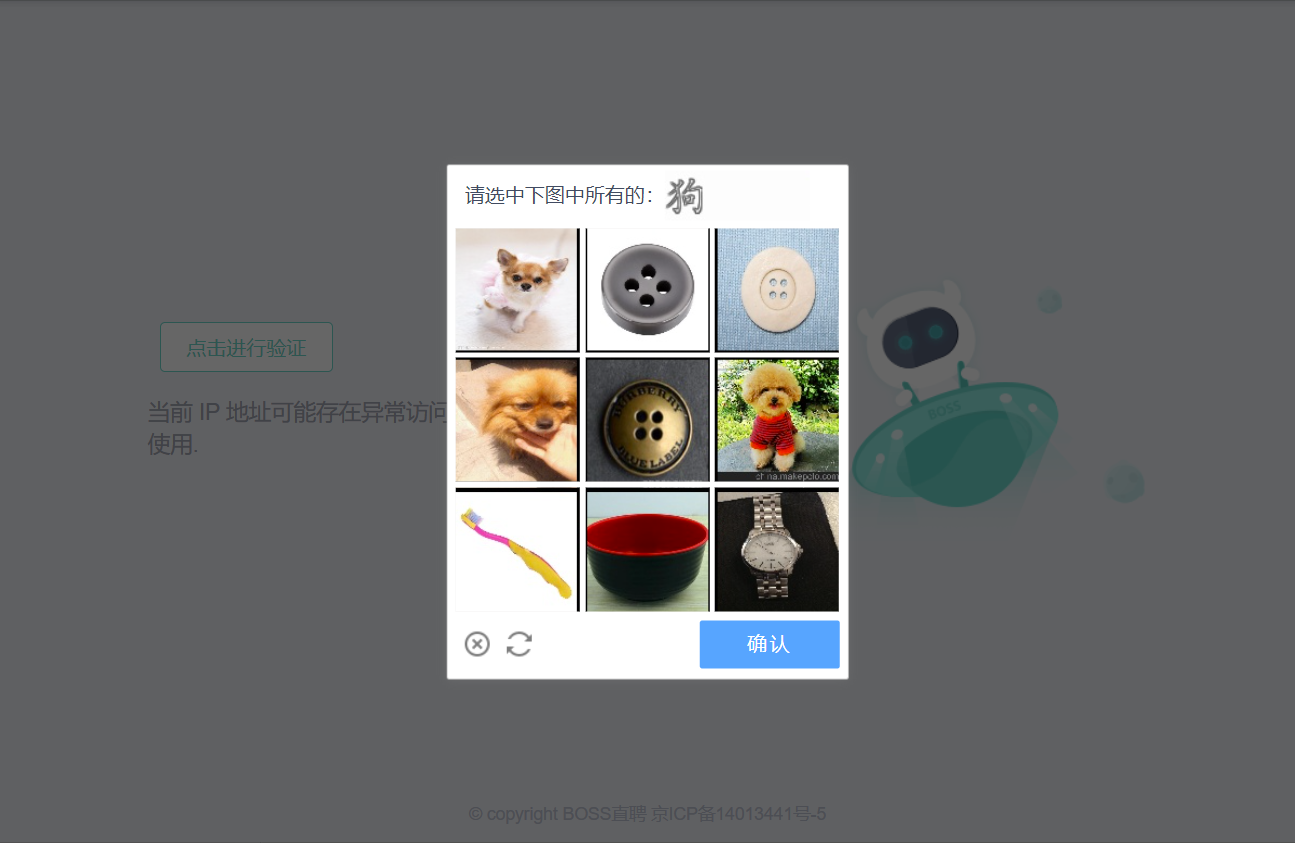
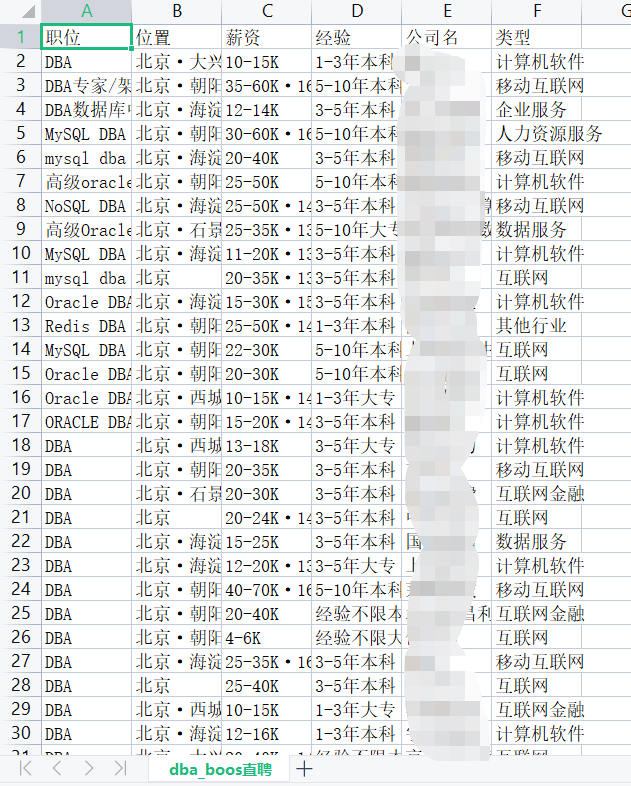
不过还好,手动解封,第一次只是个警告,后边还是顺利爬到了数据。获取北京地区有关DBA的招聘信息,使用的是selenium库来解析网页,也使用了request的方式来解析网页,但是得不到网页的真实源代码。
python:selenium爬取boss网站被关小黑屋的更多相关文章
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- Python+selenium爬取智联招聘的职位信息
整个爬虫是基于selenium和Python来运行的,运行需要的包 mysql,matplotlib,selenium 需要安装selenium火狐浏览器驱动,百度的搜寻. 整个爬虫是模块化组织的,不 ...
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- [原创]python+beautifulsoup爬取整个网站的仓库列表与仓库详情
from bs4 import BeautifulSoup import requests import os def getdepotdetailcontent(title,url):#爬取每个仓库 ...
- Python多线程爬取某网站表情包
# 爬取网络图片import requestsfrom lxml import etreefrom urllib import requestfrom queue import Queue # 导入队 ...
- python selenium 爬取淘宝
# -*- coding:utf-8 -*- # author : yesehngbao # time:2018/3/29 import re import pymongo from lxml imp ...
- python selenium爬取QQ空间方法
from selenium import webdriver import time # 打开浏览器 dr = webdriver.Chrome() # 打开某个网址 dr.get('https:// ...
随机推荐
- 三级菜单python编码及高级编码
# -*- coding: utf-8 -*- # @Time : 2020/7/31 0:13 # @Author : Breeze # @FileName: 三级菜单.py menu = { '北 ...
- 第一章 对程序员来说CPU是什么
章节标题下方有几个问题,看完后便对第一章的内容有了大概的了解. 第一章观后感想: 第一章解释了CPU是什么,CPU相当于计算机的大脑,它的内部由数百万至数亿个晶体管构成. CPU所负责的就是解释和运行 ...
- Honeywell安卓版手持机设置广播方式
设置>Honeywell设置>扫描设置>Internal Scanner>Default profile>Data Processing Settings>Data ...
- Q:带宽检测 iperf工具
一.下载 iperf的下载地址为:https://iperf.fr/iperf-download.php,选择相应的版本 linux安装 rpm -qa|grep -i rperf rpm -ivh ...
- nacos启停脚本
nacosServer.sh #!/bin/bash #auther by wangxp PWD=`pwd` #配置java环境变量 JAVA_HOME=/u01/java_home/jdk1.8.0 ...
- Delphi注解(不是注释)
开发环境Delphi XE10 1 unit Unit1; 2 3 interface 4 5 uses 6 Winapi.Windows, Winapi.Messages, System.SysUt ...
- cerebro简单使用 , ES界面化工具 , 网页查看 , 操作索引
下载安装 下载地址 https://github.com/lmenezes/cerebro/releases 解压即用 , 目录中不能有空格和中文 需要jdk11及以上(实际我本机只有jdk8也能用) ...
- java学习笔记(四)变量
局部变量,必须声明和初始化值: 实列变量,从属于对象:如果不自行初始化,这个类型的默认值,数值类型,0,0.0 布尔值 默认为false 除了基本类型下,其余的默认值都是null 如 变量类型 ...
- 使用阿里云镜像安装tensorflow
pip --default-timeout=1000 install --index-url https://mirrors.aliyun.com/pypi/simple tensorflow pip ...
- 备份linux系统日志脚本
#!/bin/bash#script_name bkup_log.sh#7 0 * * 1 cd /home/tools/;./bkup_log.sh >& /dev/nullproce ...