Spark学习笔记(一)
概念:
Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架。
支持用scala、java和Python等语言编写应用程序。相较于Hdoop,往往有更好的运行效率。
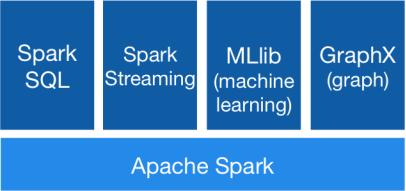
Spark包括了Spark Core, Spark SQL, SparkStreaming,MLlib和Graphx等组件。
- Spark Core:内存计算框架
- Spark SQL:及时查询
- SparkStreaming:实时应用的处理
- MLlib:机器学习
- Graphx:图形处理
Spark运行模式:
|
Local |
本地模式 |
用于本地开发测试,本地还分为local单线程和local-cluster多线程。 |
|
On yarn |
集群模式 |
运行在yarn框架之上,由yarn负责资源管理,Spark负责任务调度和计算。 |
|
Standalone |
集群模式 |
典型的Mater-slave模式,Spark自带的模式。 |
On yarn模式需要配置hadoop环境。
RDD:
众所周知,Spark的核心是RDD。RDD(Resilent Distributed Dataset)弹性分布式数据集,是一个容错的,并行的数据结构。可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。
RDD实现了基于Lineage的容错机制。RDD的转换关系,构成了compute chain,可以把这个compute chain认为是RDD之间演化的Lineage。
当一个RDD的数据丢失之后,可以从其父RDD重新计算得到。如果父RDD也不可用,则再从上一级开始计算。
简单的介绍下RDD的依赖关系:
- 窄依赖(narrow dependcies):一个子RDD只依赖一个父RDD。
- 宽依赖(wide dependcies):一个子RDD依赖于多个父RDD。
当一个RDD需要依据一个lineage进行重算时,由于窄依赖的关系更为简单,因而回复该RDD的效率更高。相反,对于宽依赖的RDD而言需要更多的时间用于恢复。
虽然lineage可用于错误后RDD的恢复,但对于很长的lineage的RDD来说,这样的恢复耗时较长。因此,将某些RDD进行检查点操作(Checkpoint)保存到稳定存储上,是有帮助的。
Transformation和Action:
算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作。
RDD有两种操作算子:
- Transformation(转换)
- Action(执行)
Transformation:结果是得到一个新的RDD。比如从数据源生成一个RDD,或是由一个RDD生成另一个RDD。
Action:得到一个值或者是一个计算结果(结果也可以是一个RDD,例如使用col lec算子)。
所有的Transfomation采用的均为懒策略。即当一个Transfomation被提交时,不会立即进行计算。计算只有在action被提交时才触发。
下图描述了Spark在运行转换中通过算子对RDD进行转换:

Spark学习笔记(一)的更多相关文章
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- Spark学习笔记——读写Hbase
1.首先在Hbase中建立一张表,名字为student 参考 Hbase学习笔记——基本CRUD操作 一个cell的值,取决于Row,Column family,Column Qualifier和Ti ...
随机推荐
- PTA数据结构与算法题目集(中文) 7-8
PTA数据结构与算法题目集(中文) 7-8 7-8 哈利·波特的考试 (25 分) 哈利·波特要考试了,他需要你的帮助.这门课学的是用魔咒将一种动物变成另一种动物的本事.例如将猫变成老鼠的魔咒是 ...
- CSS制作小旗子与小箭头
CSS制作小旗子与小箭头 效果图如下: 小旗子效果图 小箭头效果图 小旗子效果 以下是具体实现代码: <div class="container"> <div c ...
- 【redis】redis
一.redis简介: 1. reids 也是一个 key-value 存储系统,更加确切地说,它已经是一个非关系型数据库. 2. 关系型. SQL语言. 3. 非关系型. key - value. 4 ...
- Aactivity跳转到Bactivity之后再返回Aactivity的几种操作
一个主界面(主Activity)通过意图跳转至多个不同子Activity上去,当子模块的代码执行完毕后再次返回主页面,将子activity中得到的数据显示在主界面/完成的数据交给主Activity处理 ...
- "字母全变大写"组件:<uppercase> —— 快应用组件库H-UI
 <import name="uppercase" src="../Common/ui/h-ui/text/c_text_uppercase">& ...
- 项目中你不得不知的11个Java第三方类库
项目中你不得不知的11个Java第三方类库 博客分类: Java综合 JavaGoogle框架单元测试Hibernate Java第三方library ecosystem是一个很广阔的范畴.不久前有人 ...
- L26 使用卷积及循环神经网络进行文本分类
文本情感分类 文本分类是自然语言处理的一个常见任务,它把一段不定长的文本序列变换为文本的类别.本节关注它的一个子问题:使用文本情感分类来分析文本作者的情绪.这个问题也叫情感分析,并有着广泛的应用. 同 ...
- 原创Hbase1.2.1集群安装
[hadoop@Hmaster install]$ tar -zxvf hbase-1.2.1-bin.tar.gz -C ~ [hadoop@Hmaster install]$vi ~/.bash_ ...
- 【论文研读】强化学习入门之DQN
最近在学习斯坦福2017年秋季学期的<强化学习>课程,感兴趣的同学可以follow一下,Sergey大神的,有英文字幕,语速有点快,适合有一些基础的入门生. 今天主要总结上午看的有关DQN ...
- 玩转控件:Fucking ERP之流程图
前言 首先,跟守护在作者公众号和私信作者催更的朋友们道个歉.疫情的原因,公司从年初到现在一直处于996+的高压模式,导致公众号更新频率较低.而且作者每更新一篇原创公众号,既要对自己沉淀知识负责,也要对 ...