二十五、Hadoop学记笔记————Hive复习与深入
Hive主要为了简化MapReduce流程,使非编程人员也能进行数据的梳理,即直接使用sql语句代替MapReduce程序
Hive建表的时候元数据(表明,字段信息等)存于关系型数据库中,数据存于HDFS中。
此元数据与HDFS中的元数据需要区分清楚,HDFS中元数据(文件名,文件长度等)存于Namenode中,数据存于Datanode中。
本次使用的是hive1.2.2版本

下载完毕之后解压:
将default文件复制一份成site文件,然后打开site文件,清空其内容,然后配置如下参数:
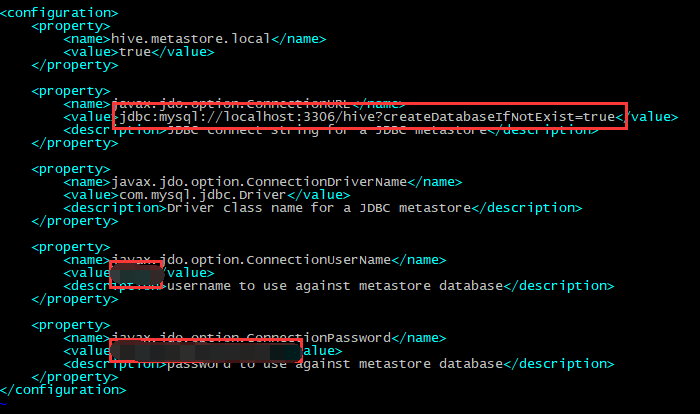
hive.metastore.local表示元数据存于本地
其中jdbc的hive是mysql中,提供给hive的database的名称,可自行修改,后续是登录的账号和密码,可以使用root,也可以新建一个hive用户,本机采用的是新建一个hive用户。
之后将mysql的jdbc驱动放入hive的lib目录下:

之后安装mysql,并在mysql下create名为hive的数据库,本机使用mysql5.7,数据库安装不做描述:
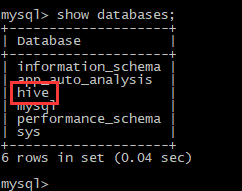
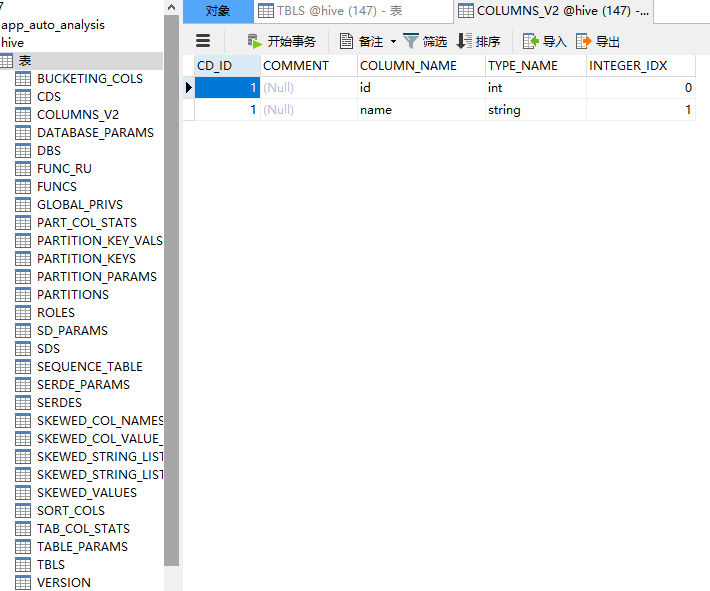
在hive中新建的表的表结构会在mysql中相应的databse内存储:

之后在例举一个复杂点的数据表,主要包含了数组型字段和map型字段,并且附带partition分区,例子来源于hive官网:
CREATE TABLE user_info(
id INT,
name STRING,
hobby ARRAY < STRING >,
goodatlol MAP < STRING, STRING >
)
PARTITIONED BY(dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
STORED AS TEXTFILE;
先新建一个user_info表:
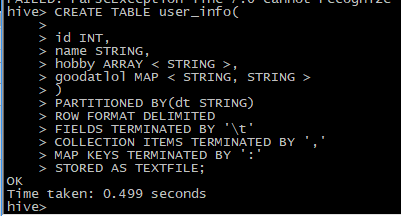
其中hobby为数组型字段,goodatlol为map型字段。fields的分隔符'\t'表示文件每一行的分隔符,collection的分隔符','表示数组型字段的分隔符,map的分隔符':'表示map字段的分隔符。
这时候在hdfs的该路径下回出现一个文件夹user_info:

由此可见,hive中的数据表,表结构的元数据存在所连接的关系型数据库中,而数据信息存于hdfs。
之后录入信息,新建文件,名字不限,内容如下:

load data local inpath '/home/tyx/temp/userinfo' into table user_info;

可用查询语句得出ttt同学喜欢上单风男:

之后在hdfs的user_info路径下还会出现分区:

前面讲述的是建表和查询,现在说一个插入比较常用的方法,由于Hive是数据仓库,主要作用是用来存放、查询和统计数据,因此插入一般是直接覆盖,而不会像Mysql那样经常一条一条的插入。在Hive中,Insert into默认是关闭的,需要做一些配置才能开启,感兴趣的朋友可以自行查询,此处只介绍insert overwrite方法,标准语法如下(源自官方文档):
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
意思就是从一个语句中读取所有数据并覆盖原数据。前面也提到Hive一般用来做统计查询,通常情况下统计所需要的字段可能分布在好几张数据表上。就算只存在于一张数据表,那统计所需要的字段也只有2到3个,新建一个表专门用来查询也可以提高查询效率。
新建一个user_test表:
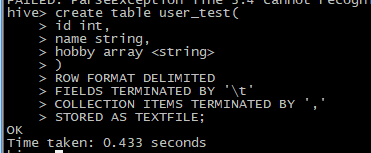
这个表相较于user_info表没有goodatlol字段和partition分区。
然后使用insert overwrite语句,将user_info中的id,name和hobby插入到user_test中来。
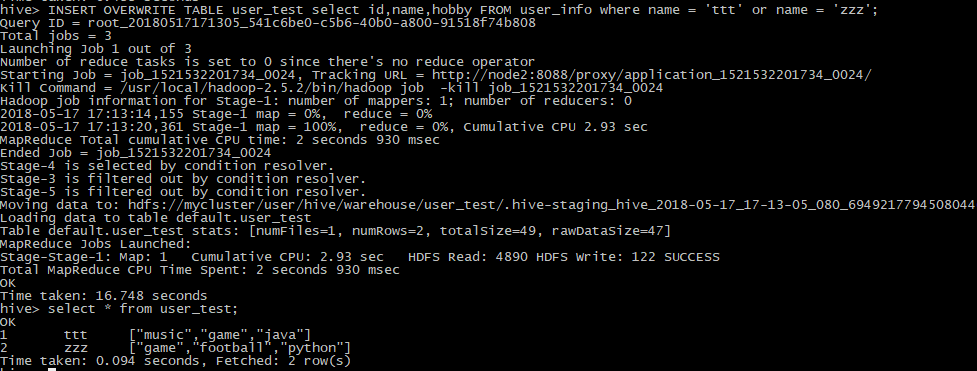
可以看到这时user_info中的name为ttt和zzz的数据都已经插入到了表user_info中,这时在该表中进行统计查询效率会比在user_info中快。
该语句在下面场景会非常实用,比如一个表A很很多字段,其中1号程序员需要用到A中的1、2、3字段做统计分析,程序员2号需要用到A中的3、6、8字段做统计分析,那么1号和2号分别都键自己的统计表会更加有效率
二十五、Hadoop学记笔记————Hive复习与深入的更多相关文章
- 二十、Hadoop学记笔记————Hive On Hbase
Hive架构图: 一般用户接口采用命令行操作, hive与hbase整合之后架构图: 使用场景 场景一:通过insert语句,将文件或者table中的内容加入到hive中,由于hive和hbase已经 ...
- 二十三、Hadoop学记笔记————Spark简介与计算模型
spark优势在于基于内存计算,速度很快,计算的中间结果也缓存在内存,同时spark也支持streaming流运算和sql运算 Mesos是资源管理框架,作为资源管理和任务调度,类似Hadoop中的Y ...
- 二十一、Hadoop学记笔记————kafka的初识
这些场景的共同点就是数据由上层框架产生,需要由下层框架计算,其中间层就需要有一个消息队列传输系统 Apache flume系统,用于日志收集 Apache storm系统,用于实时数据处理 Spark ...
- 二十四、Hadoop学记笔记————Spark的架构
master为主节点 一个集群中可能运行多个application,因此也可能会有多个driver DAG Scheduler就是讲RDD Graph拆分成一个个stage 一个Task对应一个Spa ...
- 二十二、Hadoop学记笔记————Kafka 基础实战 :消费者和生产者实例
kafka的客户端也支持其他语言,这里主要介绍python和java的实现,这两门语言比较主流和热门 图中有四个分区,每个图形对应一个consumer,任意一对一即可 获取topic的分区数,每个分区 ...
- 十九、Hadoop学记笔记————Hbase和MapReduce
概要: hadoop和hbase导入环境变量: 要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到: 如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问 ...
- 十八、Hadoop学记笔记————Hbase架构
Hbase结构图: Client,Zookeeper,Hmaster和HRegionServer相互交互协调,各个组件作用如下: 这几个组件在实际使用过程中操作如下所示: Region定位,先读取zo ...
- 十七、Hadoop学记笔记————Hbase入门
简而言之,Hbase就是一个建立在Hdfs文件系统上的数据库(mysql,orecle等),不同的是Hbase是针对列的数据库 Hbase和普通的关系型数据库区别如下: Hbase有一些基本的术语,主 ...
- python3.4学习笔记(二十五) Python 调用mysql redis实例代码
python3.4学习笔记(二十五) Python 调用mysql redis实例代码 #coding: utf-8 __author__ = 'zdz8207' #python2.7 import ...
随机推荐
- windows的服务中的登录身份本地系统账户、本地服务账户和网络服务账户修改
以一个redis服务为例: 一个redis注册服务后一般是网络服务账户,但是当系统不存在网络服务账户时,就会导致redis服务无法正常启动.接下来修改redis服务的登录身份. cmd下输入如下命令: ...
- MFC中char*,string和CString之间的转换
MFC中char*,string和CString之间的转换 一. 将CString类转换成char*(LPSTR)类型 方法一,使用强制转换.例如: CString theString( &q ...
- 初探linux子系统集之led子系统(一)
就像学编程第一个范例helloworld一样,学嵌入式,单片机.fpga之类的第一个范例就是点亮一盏灯.对于庞大的linux系统,当然可以编写一个字符设备驱动来实现我们需要的led灯,也可以直接利用g ...
- ruby创建某些“关键字”方法别名的语法
begin和end是ruby的关键字,但是Range中也有名称为begin和end的实例方法.现在问题来了:怎么创建它们的别名方法? 如果用class Range;alias begin_x begi ...
- ASP.NET Core 使用UrlFirewall对请求进行过滤
一. 前言 UrlFirewall 是一个开源.轻便的对http请求进行过滤的中间件,可使用在webapi或者网关(比如Ocelot),由我本人编写,并且开源在github:https://githu ...
- 视频博文结合的教程:用nodejs实现简单的爬虫
教学视频地址: https://v.qq.com/x/page/b0643tut4ze.html 前言 本喵最近工作中需要使用node,并也想晋升为全栈工程师,所以开始了node学习之旅,在学习过 ...
- redis+twemproxy实现redis集群
Redis+TwemProxy(nutcracker)集群方案部署记录 转自: http://www.cnblogs.com/kevingrace/p/5685401.html Twemproxy 又 ...
- hadoop_eclipse及HDT插件的使用
Hadoop Development Tools (HDT)是开发hadoop应用的eclipse插件,http://hdt.incubator.apache.org/介绍了其特点,安装,使用等,针对 ...
- FFPLAY的原理(四)
意外情况 你们将会注意到我们有一个全局变量quit,我们用它来保证还没有设置程序退出的信号(SDL会自动处理TERM类似的信号).否则,这个线程将不停地运 行直到我们使用kill -9来结束程序.FF ...
- Sending forms through JavaScript
https://developer.mozilla.org/en-US/docs/Learn/HTML/Forms/Sending_forms_through_JavaScript As in the ...