二十一、Hadoop学记笔记————kafka的初识

这些场景的共同点就是数据由上层框架产生,需要由下层框架计算,其中间层就需要有一个消息队列传输系统

Apache flume系统,用于日志收集
Apache storm系统,用于实时数据处理
Spark系统,用于内存数据处理
elasticsearch系统,用于全文检索
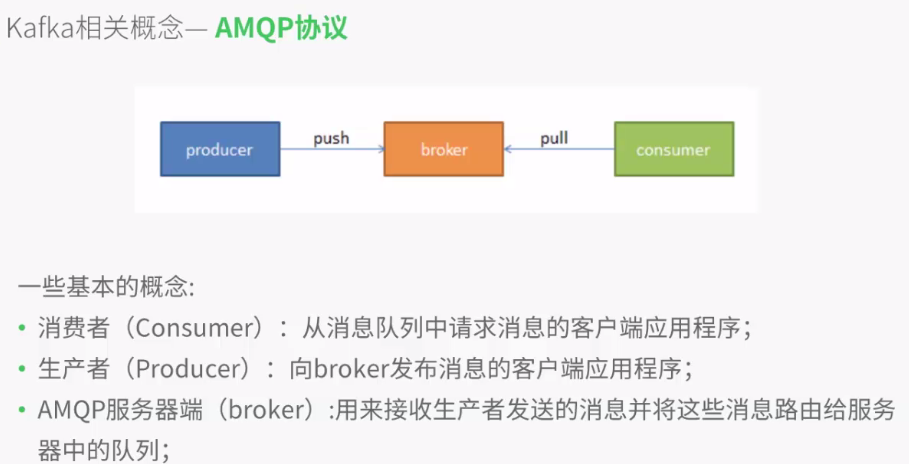
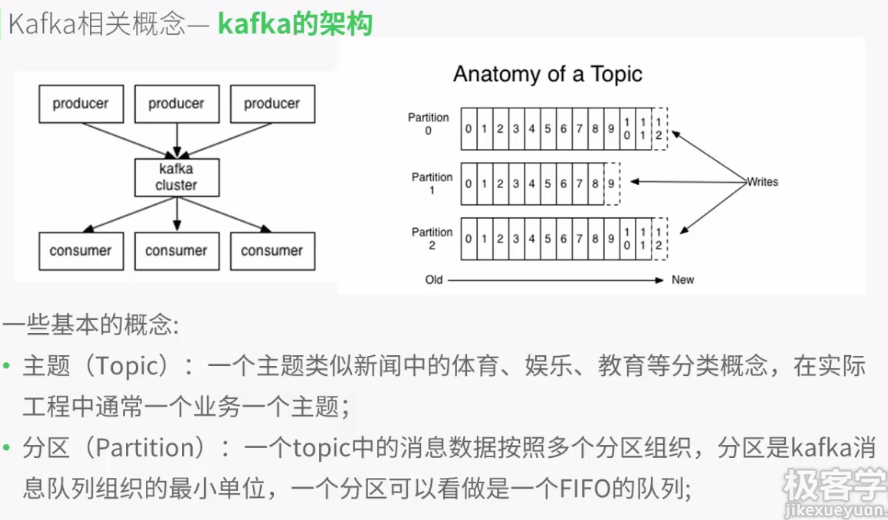

broker中每个partition都会有备份,可自行设置,前端程序和读取数据的程序都可以是自己写的程序或者是各类框架,例如hadoop,flume
搭建集群:

kafka的包需要事先下载好,zookeeper环境搭建之前已经做过介绍:
新建一个目录专门给kafka使用,这样方便管理,先解压每个服务器的kafka,然后在kafka目录下新建一个Log文件夹,用于存放kafka的消息

进入kafka的配置目录,发现还有zookeeper配置文件,kafka集群可以通过zookeeper启动,但是一般通过自己独立的启动方式启动
首先关注server.properties配置文件
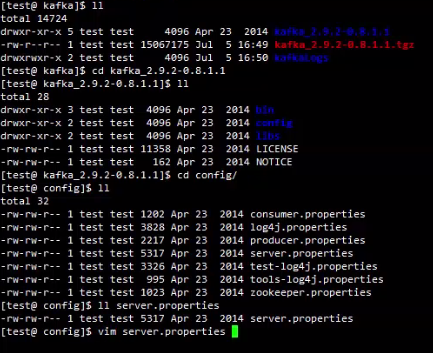
当前服务器集群ip分别为10.206.216.13,10.206.212.14,10.46.189.18
id为每个服务器的唯一参数,默认端口9092,为了防止会发生冲突,可以将端口设置比较大一点
hostname为服务器ip地址,一般该参数是关闭的,在0.8.1中有bug,默认参数是localhost,kafka在解析dns的时候会解析成ip,会有失败率,因此打开,之后的版本已经修复该bug。若修改了hosts名称也可以直接写名称:
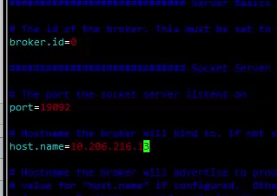
之后配置如下三项:分别为消息put字节数组大小,消息备份数和消息pull字节数组大小,图中两个字节数组大小都为5M

之后配置zookeeper集群地址,zookeeper集群默认端口为2181,为了防止端口冲突,可以改为12181,该操作可有可无:

配置log路径,若有多个可用逗号分隔,如果有多个的话,那num.io.threads参数的值必须大于配置路径的个数:

在每台服务器都配置完毕后,分别启动kafka集群:
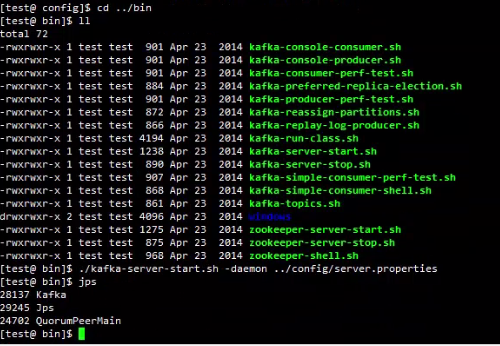
之后验证有没有错误:
先在集群上建立topic,即消息发送方,然后设置一台服务器为消息发送方producer,设置另一台服务器为consumer订阅该服务器:



在producer中发送hello消息,然后在consumer中可立即收到:


之后还有list指令和descrip指令,分别用于列出所有的topic和某个topic的描述,之后还有许多指令,需要查看官方文档:

进入zookeeper命令行之后,发现有如下目录被创建:


二十一、Hadoop学记笔记————kafka的初识的更多相关文章
- 二十二、Hadoop学记笔记————Kafka 基础实战 :消费者和生产者实例
kafka的客户端也支持其他语言,这里主要介绍python和java的实现,这两门语言比较主流和热门 图中有四个分区,每个图形对应一个consumer,任意一对一即可 获取topic的分区数,每个分区 ...
- 二十三、Hadoop学记笔记————Spark简介与计算模型
spark优势在于基于内存计算,速度很快,计算的中间结果也缓存在内存,同时spark也支持streaming流运算和sql运算 Mesos是资源管理框架,作为资源管理和任务调度,类似Hadoop中的Y ...
- 二十、Hadoop学记笔记————Hive On Hbase
Hive架构图: 一般用户接口采用命令行操作, hive与hbase整合之后架构图: 使用场景 场景一:通过insert语句,将文件或者table中的内容加入到hive中,由于hive和hbase已经 ...
- 二十五、Hadoop学记笔记————Hive复习与深入
Hive主要为了简化MapReduce流程,使非编程人员也能进行数据的梳理,即直接使用sql语句代替MapReduce程序 Hive建表的时候元数据(表明,字段信息等)存于关系型数据库中,数据存于HD ...
- 二十四、Hadoop学记笔记————Spark的架构
master为主节点 一个集群中可能运行多个application,因此也可能会有多个driver DAG Scheduler就是讲RDD Graph拆分成一个个stage 一个Task对应一个Spa ...
- 十九、Hadoop学记笔记————Hbase和MapReduce
概要: hadoop和hbase导入环境变量: 要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到: 如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问 ...
- 十七、Hadoop学记笔记————Hbase入门
简而言之,Hbase就是一个建立在Hdfs文件系统上的数据库(mysql,orecle等),不同的是Hbase是针对列的数据库 Hbase和普通的关系型数据库区别如下: Hbase有一些基本的术语,主 ...
- 十八、Hadoop学记笔记————Hbase架构
Hbase结构图: Client,Zookeeper,Hmaster和HRegionServer相互交互协调,各个组件作用如下: 这几个组件在实际使用过程中操作如下所示: Region定位,先读取zo ...
- 学记笔记 $\times$ 巩固 · 期望泛做$Junior$
最近泛做了期望的相关题目,大概\(Luogu\)上提供的比较简单的题都做了吧\(233\) 好吧其实是好几天之前做的了,不过因为太颓废一直没有整理-- \(Task1\) 期望的定义 在概率论和统计学 ...
随机推荐
- 【Visual C++】游戏编程学习笔记之八:鼠标输入消息(小demo)
本系列文章由@二货梦想家张程 所写,转载请注明出处. 作者:ZeeCoder 微博链接:http://weibo.com/zc463717263 我的邮箱:michealfloyd@126.c ...
- 集群增量会话管理器——DeltaManager
DeltaManager会话管理器是tomcat默认的集群会话管理器,它主要用于集群中各个节点之间会话状态的同步维护,由于相关内容涉及到集群,可能会需要一些集群通信相关知识,如果有疑问可结合集群相关章 ...
- 和菜鸟一起学产品之用户体验设计UED
ps:参考产品经理深入浅出ppt
- ZeroMQ 教程 001 : 基本概览
介绍性的话我这里就不翻译了, 总结起来就是zmq很cool, 你应该尝试一下. 如何安装与使用zmq 在Linux和Mac OS上, 请通过随机附带的包管理软件, 或者home brew安装zmq. ...
- 关于在vim中的查找和替换
1,查找 在normal模式下按下/即可进入查找模式,输入要查找的字符串并按下回车. Vim会跳转到第一个匹配.按下n查找下一个,按下N查找上一个. Vim查找支持正则表达式,例如/vim$匹配行尾的 ...
- HTMLConverter使用实例(转)
---- 本来,Applet的概念相当简单——只要在Web页面中加入一个< APPLET >标记就可以了.浏览器一遇到这个标记,就会下载对应的 Applet类文件,并启动自己的解释器运行这 ...
- Ubuntu 下命令安装 Java
1. 使用 java -version 查看系统是否存在 jdk. 2. ubuntu使用的是openjdk,所以我们需要先找到合适的jdk版本.在命令行中输入命令:apt-cache search ...
- 微信小程序之获取用户位置权限(拒绝后提醒)
微信小程序获取用户当前位置有三个方式: 1. wx.getLocation(多与wx.openLocation一起用) 获取当前的精度.纬度.速度.不需要授权.当type设置为gcj02 返回可用于w ...
- Hadoop生态圈初识
一.简介 Hadoop是一个由Apache基金会所开发的分布式系统基础架构.Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,则MapReduce为海量 ...
- 实现MyArrayList类深入理解ArrayList
ArrayList简介 ArrayList是一个动态数组,Array的复杂版本,它提供了动态的增加和减少元素,实现了ICollection和IList接口,灵活的设置数组的大小等好处. MyArray ...