二十三、Hadoop学记笔记————Spark简介与计算模型
spark优势在于基于内存计算,速度很快,计算的中间结果也缓存在内存,同时spark也支持streaming流运算和sql运算



Mesos是资源管理框架,作为资源管理和任务调度,类似Hadoop中的Yran
Tachyon是分布式内存文件系统
Spark是核心计算引擎,能够将数据并行大规模计算
Spark Streaming是流式计算引擎,将每个数据切分成小块采用spark运算范式进行运算
Spark SQL是Spark的SQL ON Hadoop,能够用sql来对数据进行查询等功能
GraphX是图计算引擎
MLlib是机器学习库,提供聚类,分类以及推荐等基本的机器学习算法,并且社区中不断开发新的算法

Spark解决了哪些之前专有系统的局限性
重复开发,可能用使用storm来进行流式计算,有用别的框架进行机器学习
系统组合,不同系统之间数据需要约定格式
专有系统适用范围局限,storm适用于流计算,graphX适用于图计算
资源分配与管理,每个系统都有各自的资源管理,不方便协调




弹性分布式数据集RDD:分布式数组,将整个数据切分成不同的块,然后存到不同的节点通过一个统一的元数据RDD进行管理
partition,存储所有数据块的列表
compute函数,支持不同的RDD完成不同的运算(在不同节点上对这些数据块进行不同的运算)
dependencies维持每次RDD的顺序,比如一部分数据首先要进行去重,然后排序,分组,每次一运算数据都要用到上一次RDD的结果,这就需要dependencies来进行管理
partitioner,重新分区,
preferredLocations,优先读取本地数据

transformations,转换数据



编写程序实例:
进入spark官网,下载并解压spark程序包,此处用最新的:


解压之后在IDE中新建Scala项目,此处使用IntelliJ作为IDE:
new一个project并选择Scala,然后选择object:

讲Spark中jar文件下的jar包全部导入project:
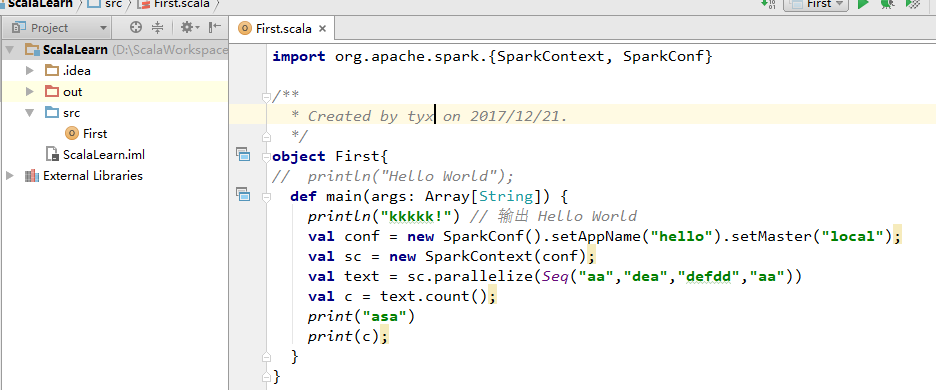
编写如上代码运行,先建立连接spark实例,然后命名,之后选择地址,目前用本地环境
之后编写数据,用parallelize将数据写入RDD,然后可以开始统计count,或者take数据等操作
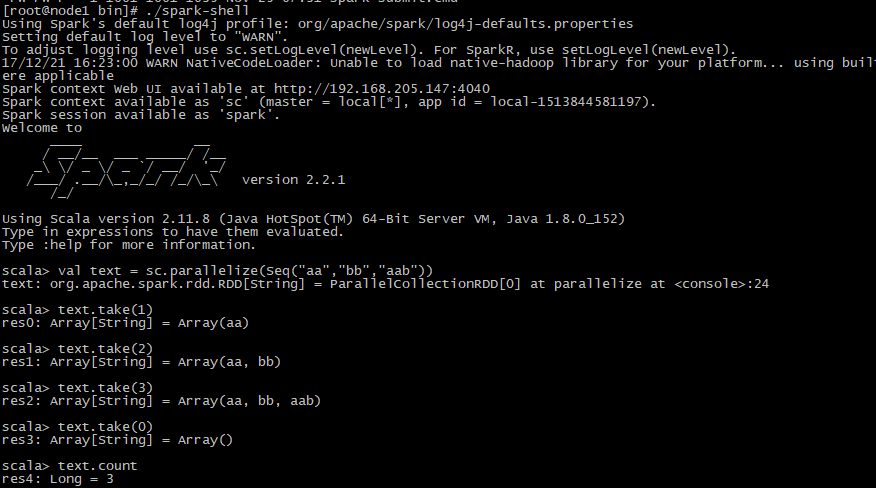
还可以在服务器上用spark-shell执行代码,还是先解压下载好的scala包,然后进入bin目录,执行./spark-shell,由于是内环境操作,不需要实例化链接,然后与上述操作一样:
二十三、Hadoop学记笔记————Spark简介与计算模型的更多相关文章
- 二十四、Hadoop学记笔记————Spark的架构
master为主节点 一个集群中可能运行多个application,因此也可能会有多个driver DAG Scheduler就是讲RDD Graph拆分成一个个stage 一个Task对应一个Spa ...
- 二十二、Hadoop学记笔记————Kafka 基础实战 :消费者和生产者实例
kafka的客户端也支持其他语言,这里主要介绍python和java的实现,这两门语言比较主流和热门 图中有四个分区,每个图形对应一个consumer,任意一对一即可 获取topic的分区数,每个分区 ...
- 二十一、Hadoop学记笔记————kafka的初识
这些场景的共同点就是数据由上层框架产生,需要由下层框架计算,其中间层就需要有一个消息队列传输系统 Apache flume系统,用于日志收集 Apache storm系统,用于实时数据处理 Spark ...
- 二十、Hadoop学记笔记————Hive On Hbase
Hive架构图: 一般用户接口采用命令行操作, hive与hbase整合之后架构图: 使用场景 场景一:通过insert语句,将文件或者table中的内容加入到hive中,由于hive和hbase已经 ...
- 二十五、Hadoop学记笔记————Hive复习与深入
Hive主要为了简化MapReduce流程,使非编程人员也能进行数据的梳理,即直接使用sql语句代替MapReduce程序 Hive建表的时候元数据(表明,字段信息等)存于关系型数据库中,数据存于HD ...
- 十九、Hadoop学记笔记————Hbase和MapReduce
概要: hadoop和hbase导入环境变量: 要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到: 如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问 ...
- 十七、Hadoop学记笔记————Hbase入门
简而言之,Hbase就是一个建立在Hdfs文件系统上的数据库(mysql,orecle等),不同的是Hbase是针对列的数据库 Hbase和普通的关系型数据库区别如下: Hbase有一些基本的术语,主 ...
- 十八、Hadoop学记笔记————Hbase架构
Hbase结构图: Client,Zookeeper,Hmaster和HRegionServer相互交互协调,各个组件作用如下: 这几个组件在实际使用过程中操作如下所示: Region定位,先读取zo ...
- 笔记:Spark简介
Spark简介 [TOC] Spark是什么 Spark是基于内存计算的大数据并行计算框架 Spark是MapReduce的替代方案 Spark与Hadoop Spark是一个计算框架,而Hadoop ...
随机推荐
- Unity3D学习笔记(一)GUI控件的调用
GUI控件:1.在Start中初始化,在OnGUI中调整.2.公有变量才会出现在Inspector面板.3.GUI控件的初始化和处理在OnGUI内完成.4.JavaScript的中文为UTF-8编码可 ...
- 如何修改新建脚本模板-ScriptTemplates(Unity3D开发之十五)
猴子原创,欢迎转载.转载请注明: 转载自Cocos2Der-CSDN,谢谢! 原文地址: http://blog.csdn.net/cocos2der/article/details/44957631 ...
- Bookmarkable Pages
Build a Bookmarkable Edit Page with JDeveloper 11g Purpose In this tutorial, you use Oracle JDevel ...
- SpriteBuilder全屏弹出菜单的特殊效果
但是等一下!这里可以有更多.对于全屏的弹出菜单,你可以在显示弹出全屏菜单时朦胧化背景的level视图. 通过修改SpriteBuilder中的color节点的Color属性(比如修改为black)和O ...
- 一个简单的基于 DirectShow 的播放器 1(封装类)
DirectShow最主要的功能就是播放视频,在这里介绍一个简单的基于DirectShow的播放器的例子,是用MFC做的,今后有机会可以基于该播放器开发更复杂的播放器软件. 注:该例子取自于<D ...
- C# DataTable,DataSet,IList,IEnumerable 互转扩展属性
using System; using System.Collections.Generic; using System.Data; using System.Linq; using System.R ...
- 最新App Store审核10大被拒理由
最近,苹果在官网给出了截至2015年2月份应用被拒绝的十大理由,其中50%以上的应用被拒绝都是因为这10个原因,其中7个理由和2014年相同,其中排名前三的原因分别是:需要补充更多信息.存在明显的bu ...
- Android绘图机制(一)——自定义View的基础属性和方法
Android绘图机制(一)--自定义View的基础属性和方法 自定义View看起来,确实看起来高深莫测,很多Android开发都不是特别在行这一块,这里面的逻辑以及一些绘画都是有一点难的,说一下我目 ...
- Win7笔记本电脑启用虚拟WIFI共享上网
今天看了一个帖子,win7系统通过笔记本的无线网卡,启用虚拟Wifi功能共享上网,自己尝试了一下,感觉很好用,至少没有无线路由的自己,手机可以上wifi了,更新软件玩微信等等,都方便多了,好了,废话不 ...
- opencv基本图像操作
// Basic_OpenCV_2.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <iostream> #i ...