Hadoop: 单词计数(Word Count)的MapReduce实现
1.Map与Reduce过程
1.1 Map过程
首先,Hadoop会把输入数据划分成等长的输入分片(input split) 或分片发送到MapReduce。Hadoop为每个分片创建一个map任务,由它来运行用户自定义的map函数以分析每个分片中的记录。在我们的单词计数例子中,输入是多个文件,一般一个文件对应一个分片,如果文件太大则会划分为多个分片。map函数的输入以<key, value>形式做为输入,value为文件的每一行,key为该行在文件中的偏移量(一般我们会忽视)。这里map函数起到的作用为将每一行进行分词为多个word,并在context中写入<word, 1>以代表该单词出现一次。
map过程的示意图如下:

mapper代码编写如下:
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//每次处理一行,一个mapper里的value为一行,key为该行在文件中的偏移量
StringTokenizer iter = new StringTokenizer(value.toString());
while (iter.hasMoreTokens()) {
word.set(iter.nextToken());
// 向context中写入<word, 1>
context.write(word, one);
System.out.println(word);
}
}
}
如果我们能够并行处理分片(不一定是完全并行),且分片是小块的数据,那么处理过程将会有一个好的负载平衡。但是如果分片太小,那么管理分片与map任务创建将会耗费太多时间。对于大多数作业,理想分片大小为一个HDFS块的大小,默认是64MB。
map任务的执行节点和输入数据的存储节点相同时,Hadoop的性能能达到最佳,这就是计算机系统中所谓的data locality optimization(数据局部性优化)。而最佳分片大小与块大小相同的原因就在于,它能够保证一个分片存储在单个节点上,再大就不能了。
1.2 Reduce过程
接下来我们看reducer的编写。reduce任务的多少并不是由输入大小来决定,而是需要人工单独指定的(默认为1个)。和上面map不同的是,reduce任务不再具有本地读取的优势————一个reduce任务的输入往往来自于所有mapper的输出,因此map和reduce之间的数据流被称为 shuffle(洗牌) 。Hadoop会先按照key-value对进行排序,然后将排序好的map的输出通过网络传输到reduce任务运行的节点,并在那里进行合并,然后传递到用户定义的reduce函数中。
reduce 函数示意图如下:
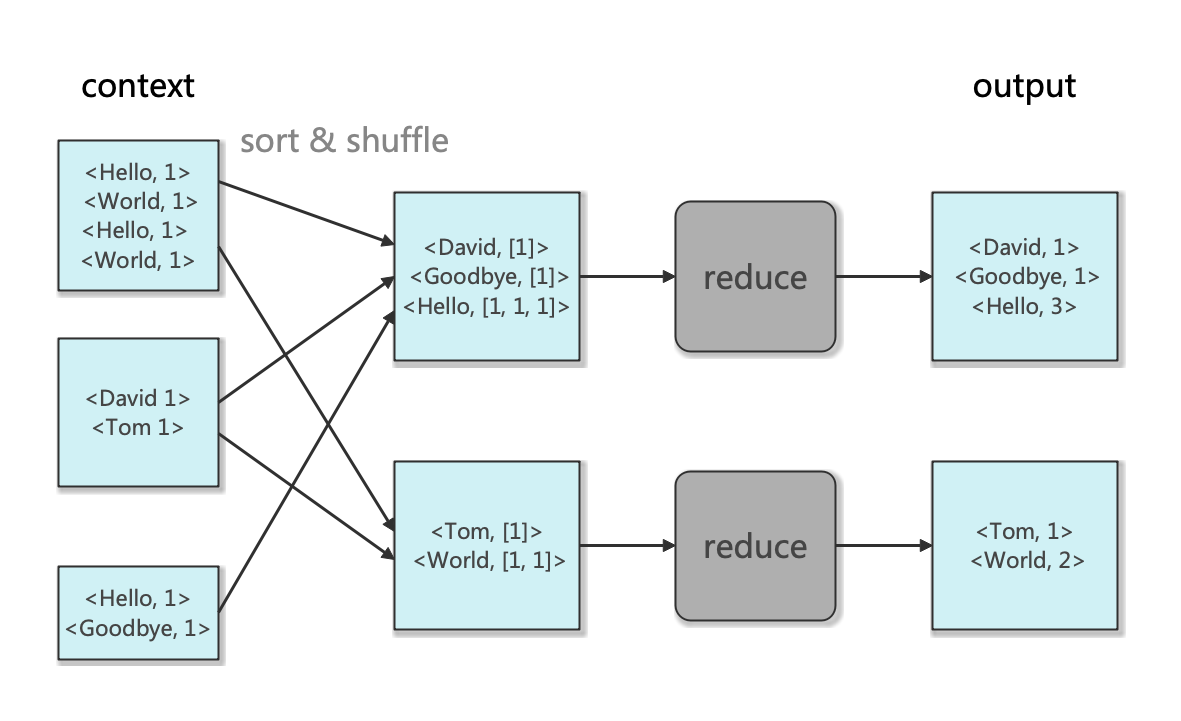
reducer代码编写如下:
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
2.完整代码
2.1 项目架构
关于VSCode+Java+Maven+Hadoop开发环境搭建,可以参见我的博客《VSCode+Maven+Hadoop开发环境搭建》,此处不再赘述。这里展示我们的项目架构图:
Word-Count-Hadoop
├─ input
│ ├─ file1
│ ├─ file2
│ └─ file3
├─ output
├─ pom.xml
├─ src
│ └─ main
│ └─ java
│ └─ WordCount.java
└─ target
WordCount.java代码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount{
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//每次处理一行,一个mapper里的value为一行,key为该行在文件中的偏移量
StringTokenizer iter = new StringTokenizer(value.toString());
while (iter.hasMoreTokens()) {
word.set(iter.nextToken());
// 向context中写入<word, 1>
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word_count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
//此处的Combine操作意为即第每个mapper工作完了先局部reduce一下,最后再全局reduce
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//第0个参数是输入目录,第1个参数是输出目录
//先判断output path是否存在,如果存在则删除
Path path = new Path(args[1]);//
FileSystem fileSystem = path.getFileSystem(conf);
if (fileSystem.exists(path)) {
fileSystem.delete(path, true);
}
//设置输入目录和输出目录
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
pom.xml中记得配置Hadoop的依赖环境:
...
<!-- 集中定义版本号 -->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<hadoop.version>3.3.1</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- 导入hadoop依赖环境 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
...
</project>
此外,因为我们的程序自带输入参数,我们还需要在VSCode的launch.json中配置输入参数intput(代表输入目录)和output(代表输出目录):
...
"args": [
"input",
"output"
],
...
编译运行完毕后,可以查看output文件夹下的part-r-00000文件:
David 1
Goodbye 1
Hello 3
Tom 1
World 2
可见我们的程序正确地完成了单词计数的功能。
参考
- [1] Hadoop官方文档:MapReduce Tutorial
- [2] White T. Hadoop: The definitive guide[M]. " O'Reilly Media, Inc.", 2012.
- [3] Stack Overflow: What is the purpose of shuffling and sorting phase in the reducer in Map Reduce Programming?
Hadoop: 单词计数(Word Count)的MapReduce实现的更多相关文章
- Spark: 单词计数(Word Count)的MapReduce实现(Java/Python)
1 导引 我们在博客<Hadoop: 单词计数(Word Count)的MapReduce实现 >中学习了如何用Hadoop-MapReduce实现单词计数,现在我们来看如何用Spark来 ...
- 基于 MapReduce 的单词计数(Word Count)的实现
完整代码: // 导入必要的包 import java.io.IOException; import java.util.StringTokenizer; import org.apache.hado ...
- hadoop笔记之MapReduce的应用案例(WordCount单词计数)
MapReduce的应用案例(WordCount单词计数) MapReduce的应用案例(WordCount单词计数) 1. WordCount单词计数 作用: 计算文件中出现每个单词的频数 输入结果 ...
- Hadoop分布环境搭建步骤,及自带MapReduce单词计数程序实现
Hadoop分布环境搭建步骤: 1.软硬件环境 CentOS 7.2 64 位 JDK- 1.8 Hadoo p- 2.7.4 2.安装SSH sudo yum install openssh-cli ...
- MapReduce之单词计数
最近在看google那篇经典的MapReduce论文,中文版可以参考孟岩推荐的 mapreduce 中文版 中文翻译 论文中提到,MapReduce的编程模型就是: 计算利用一个输入key/value ...
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- Mac下hadoop运行word count的坑
Mac下hadoop运行word count的坑 Word count体现了Map Reduce的经典思想,是分布式计算中中的hello world.然而博主很幸运地遇到了Mac下特有的问题Mkdir ...
- 大数据【四】MapReduce(单词计数;二次排序;计数器;join;分布式缓存)
前言: 根据前面的几篇博客学习,现在可以进行MapReduce学习了.本篇博客首先阐述了MapReduce的概念及使用原理,其次直接从五个实验中实践学习(单词计数,二次排序,计数器,join,分 ...
- HDFS 手写mapreduce单词计数框架
一.数据处理类 package com.css.hdfs; import java.io.BufferedReader; import java.io.IOException; import java ...
随机推荐
- 【译】HTML表单高级样式
系列文章说明 原文 在本文中,我们将了解如何在HTML表单上使用CSS,为那些难于自定义的表单组件加以样式.如前文所述,文本框和按钮很适合使用CSS,而现在我们得来探索HTML表单样式的那些坑了. 在 ...
- 在小程序Canvas中使用measureText
有时候我们在使用Canvas绘制一段文本时,会需要通过measureText()方法获取文本的宽度,例如: 创建canvas标签 <canvas id="canvas"> ...
- video标签学习使用
video标签学习使用 学习前的理解 video是HTML5中的新标签,可以用来播放视频.对于不同的浏览器支持的视频格式不一样,但是具体浏览器支持的类型并不清楚. 支持的类型 视频的格式分为编码格式和 ...
- ES6-11学习笔记--代理Proxy
Proxy代理 常用拦截方法 ES5拦截: let obj = {} let newVal = '' Object.defineProperty(obj, 'name', { get() { cons ...
- web开发者踏入人工智能的利器_Tensorflow.js
前言 最近公司向员工搜集公司杂志的文章,刚好最近学习了机器学习相关课程.为了赚取购买课程的费用,所以写了如下文章投稿赚取稿费. 如下文章可能涉及一些我所购买课程的内容,所以不便将所有资源进行展示. 当 ...
- 手绘模型图带你认识Kafka服务端网络模型
摘要:Kafka中的网络模型就是基于主从Reactor多线程进行设计的. 本文分享自华为云社区<图解Kafka服务端网络模型>,作者:石臻臻的杂货铺 . Kafka中的网络模型就是基于主从 ...
- sring框架的jdbc应用
xml配置 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http: ...
- 使用localStorage缓存消息(聊天页面)
可以在聊天页面的created生命周期里面写如下代码,使得刷新后的页面和之前的是一样的 created(){ alert(11) //在页面加载时读取localStorage里的状态 ...
- 基于Spring接口,集成Caffeine+Redis两级缓存
原创:微信公众号 码农参上,欢迎分享,转载请保留出处. 在上一篇文章Redis+Caffeine两级缓存,让访问速度纵享丝滑中,我们介绍了3种整合Caffeine和Redis作为两级缓存使用的方法,虽 ...
- Linux磁盘之inode
什么是 inode ? 文件储存在硬盘上,硬盘的最小存储单位叫作"扇区"(Sector).每一个扇区储存512字节(至关于0.5KB).操作系统读取硬盘的时候,不会一个个扇区地读取 ...