Elasticsearch: Ngrams, edge ngrams, and shingles
Ngrams和edge ngrams是在Elasticsearch中标记文本的两种更独特的方式。 Ngrams是一种将一个标记分成一个单词的每个部分的多个子字符的方法。 ngram和edge ngram过滤器都允许您指定min_gram以及max_gram设置。 这些设置控制单词被分割成的标记的大小。 这可能令人困惑,让我们看一个例子。 假设你想用ngram分析仪分析“spaghetti”这个词,让我们从最简单的情况开始,1-gams(也称为unigrams)。
在实际的搜索例子中,比如谷歌搜索:
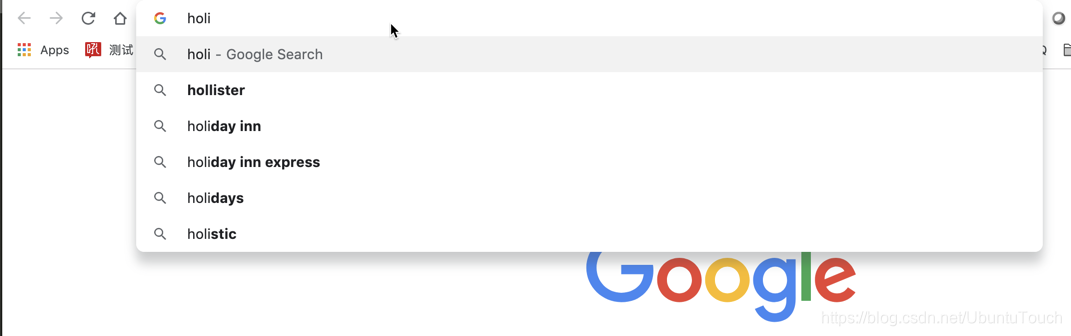
每当我们打入前面的几个字母时,就会出现相应的很多的候选名单。这个就是autocomplete功能。在Elasticsearch中,我们可以通过Edge ngram来实现这个目的。
1-grams
“spaghetti”的1-grams是s,p,a,g,h,e,t,t,i。 根据ngram的大小将字符串拆分为较小的token。 在这种情况下,每个token都是一个字符,因为我们谈论的是unigrams。
Bigrams
如果你要将字符串拆分为双字母组(这意味着大小为2),你将获得以下较小的token:sp,pa,ag,gh,he,et,tt,ti。
Trigrams
再说一次,如果你要使用三个大小,你将得到token为spa,pag,agh,ghe,het,ett,tti。
设置min_gram和max_gram
使用此分析器时,需要设置两种不同的大小:一种指定要生成的最小ngrams(min_gram设置),另一种指定要生成的最大ngrams。 使用前面的示例,如果您指定min_gram为2且max_gram为3,则您将获得前两个示例中的组合标记:
sp, spa, pa, pag, ag, agh, gh, ghe, he, het, et, ett, tt, tti, ti
如果你要将min_gram设置为1并将max_gram设置为3,那么你将得到更多的标记,从s,sp,spa,p,pa,pag,a,....开始。
以这种方式分析文本具有一个有趣的优点。 当你查询文本时,你的查询将以相同的方式被分割成文本,所以说你正在寻找拼写错误的单词“spaghety”。搜索这个的一种方法是做一个fuzzy query,它允许你 指定单词的编辑距离以检查匹配。 但是你可以通过使用ngrams来获得类似的行为。 让我们将原始单词(“spaghetti”)生成的bigrams与拼写错误的单词(“spaghety”)进行比较:
- “spaghetti”的bigrams:sp,pa,ag,gh,he,et,tt,ti
- “spaghety”的bigrams:sp,pa,ag,gh,he,et,ty
您可以看到六个token重叠,因此当查询包含“spaghety”时,其中带有“spaghetti”的单词仍然匹配。请记住,这意味着您可能不打算使用的原始“spaghetti”单词更多的单词 ,所以请务必测试您的查询相关性!
ngrams做的另一个有用的事情是允许您在事先不了解语言时或者当您使用与其他欧洲语言不同的方式组合单词的语言时分析文本。 这还有一个优点,即能够使用单个分析器处理多种语言,而不必指定。
Edge ngrams
常规ngram拆分的变体称为edge ngrams,仅从前沿构建ngram。 在“spaghetti”示例中,如果将min_gram设置为2并将max_gram设置为6,则会获得以下标记:
sp, spa, spag, spagh, spaghe
您可以看到每个标记都是从边缘构建的。 这有助于搜索共享相同前缀的单词而无需实际执行前缀查询。 如果你需要从一个单词的后面构建ngrams,你可以使用side属性从后面而不是默认前面获取边缘。
Ngram 设置
当你不知道语言是什么时,Ngrams是分析文本的好方法,因为它们可以分析单词之间没有空格的语言。 使用min和max grams配置edge ngram analyzer的示例如下所示:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 10,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
}
我们可以用刚才创建的my_tokenizer来分析我们的字符串:
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "2 Quick Foxes."
}
显示的结果是:
{
"tokens" : [
{
"token" : "Qu",
"start_offset" : 2,
"end_offset" : 4,
"type" : "word",
"position" : 0
},
{
"token" : "Qui",
"start_offset" : 2,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "Quic",
"start_offset" : 2,
"end_offset" : 6,
"type" : "word",
"position" : 2
},
{
"token" : "Quick",
"start_offset" : 2,
"end_offset" : 7,
"type" : "word",
"position" : 3
},
{
"token" : "Fo",
"start_offset" : 8,
"end_offset" : 10,
"type" : "word",
"position" : 4
},
{
"token" : "Fox",
"start_offset" : 8,
"end_offset" : 11,
"type" : "word",
"position" : 5
},
{
"token" : "Foxe",
"start_offset" : 8,
"end_offset" : 12,
"type" : "word",
"position" : 6
},
{
"token" : "Foxes",
"start_offset" : 8,
"end_offset" : 13,
"type" : "word",
"position" : 7
}
]
}
因为我们定义的min_gram是2,所以生成的token的长度是从2开始的。
通常我们建议在索引时和搜索时使用相同的分析器。 在edge_ngram tokenizer的情况下,建议是不同的。 仅在索引时使用edge_ngram标记生成器才有意义,以确保部分单词可用于索引中的匹配。 在搜索时,只需搜索用户输入的术语,例如:Quick Fo。
下面是如何为搜索类型设置字段的示例:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"autocomplete": {
"tokenizer": "autocomplete",
"filter": [
"lowercase"
]
},
"autocomplete_search": {
"tokenizer": "lowercase"
}
},
"tokenizer": {
"autocomplete": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 10,
"token_chars": [
"letter"
]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "autocomplete",
"search_analyzer": "autocomplete_search"
}
}
}
}
在我们的例子中,我们索引时和搜索时时用了两个不同的analyzer:autocomplete及autocomplete_search。
PUT my_index/_doc/1
{
"title": "Quick Foxes"
}
POST my_index/_refresh
上面我们加入一个文档。下面我们来进行搜索:
GET my_index/_search
{
"query": {
"match": {
"title": {
"query": "Quick Fo",
"operator": "and"
}
}
}
}
显示结果:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.5753642,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.5753642,
"_source" : {
"title" : "Quick Foxes"
}
}
]
}
}
在这里autocomplete analyzer可以把字符串“Quick Foxes”分解为[qu, qui, quic, quick, fo, fox, foxe, foxes]。而自autocomplete_search analyzer搜索条目[quick,fo],两者都出现在索引中。
当然我们也可以做如下的搜索:
GET my_index/_search
{
"query": {
"match": {
"title": {
"query": "Fo"
}
}
}
}
显示的和上面一样的结果。
Shingles
与ngrams和edge ngrams一样,有一个称为shingle的过滤器(不,不是疾病的那个shingle!)。 Shingle token过滤器基本上是token级别的ngrams而不是字符级别。
想想我们最喜欢的单词“spaghetti”。使用最小和最大设置为1和3的ngrams,Elasticsearch将生成标记s,sp,spa,p,pa,pag,a,ag等。 一个shingle过滤器在token级别执行此操作,因此如果您有文本“foo bar baz”并再次使用in_shingle_size为2且max_shingle_size为3,则您将生成以下token:
foo, foo bar, foo bar baz, bar, bar baz, baz
为什么仍然包含单token输出? 这是因为默认情况下,shingle过滤器包含原始token,因此原始标记生成令牌foo,bar和baz,然后将其传递给shingle token过滤器,生成标记foo bar,foo bar baz和bar baz。 所有这些token组合在一起形成最终token流。 您可以通过将output_unigrams选项设置为false来禁用此行为,也即不需要最原始的token:foo, bar及baz
下一个清单显示了shingle token过滤器的示例; 请注意,min_shingle_size选项必须大于或等于2。
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"shingle": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"shingle-filter"
]
}
},
"filter": {
"shingle-filter": {
"type": "shingle",
"min_shingle_size": 2,
"max_shingle_size": 3,
"output_unigrams": false
}
}
}
}
}
在这里,我们定义了一个叫做shingle-filter的过滤器。最小的shangle大小是2,最大的shingle大小是3。同时我们设置output_unigrams为false,这样最初的那些token将不被包含在最终的结果之中。
下面我们来做一个例子,看看显示的结果:
GET /my_index/_analyze
{
"text": "foo bar baz",
"analyzer": "shingle"
}
显示的结果为:
{
"tokens" : [
{
"token" : "foo bar",
"start_offset" : 0,
"end_offset" : 7,
"type" : "shingle",
"position" : 0
},
{
"token" : "foo bar baz",
"start_offset" : 0,
"end_offset" : 11,
"type" : "shingle",
"position" : 0,
"positionLength" : 2
},
{
"token" : "bar baz",
"start_offset" : 4,
"end_offset" : 11,
"type" : "shingle",
"position" : 1
}
]
}
参考:
【1】 https://www.elastic.co/guide/en/elasticsearch/reference/7.3/analysis-edgengram-tokenizer.html
Elasticsearch: Ngrams, edge ngrams, and shingles的更多相关文章
- elasticsearch 关联单词查询以及Shingles
Shingle Token Filter A token filter of type shingle that constructs shingles (token n-grams) from a ...
- [Elasticsearch] 部分匹配 (四) - 索引期间优化ngrams及索引期间的即时搜索
本章翻译自Elasticsearch官方指南的Partial Matching一章. 索引期间的优化(Index-time Optimizations) 眼下我们讨论的全部方案都是在查询期间的.它们不 ...
- Elasticsearch:定制分词器(analyzer)及相关性
转载自:https://elasticstack.blog.csdn.net/article/details/114278163 在许多的情况下,我们使用现有的分词器已经足够满足我们许多的业务需求,但 ...
- ElasticSearch 2 (10) - 在ElasticSearch之下(深入理解Shard和Lucene Index)
摘要 从底层介绍ElasticSearch Shard的内部原理,以及回答为什么使用ElasticSearch有必要了解Lucene的内部工作方式? 了解ElasticSearch API的代价 构建 ...
- ElasticSearch 2 (17) - 深入搜索系列之部分匹配
ElasticSearch 2 (17) - 深入搜索系列之部分匹配 摘要 到目前为止,我们介绍的所有查询都是基于完整术语的,为了匹配,最小的单元为单个术语,我们只能查找反向索引中存在的术语. 但是, ...
- N-Gram
N-Gram是大词汇连续语音识别中常用的一种语言模型,对中文而言,我们称之为汉语语言模型(CLM, Chinese Language Model). 中文名 汉语语言模型 外文名 N-Gram 定 ...
- 笔记之Python网络数据采集
笔记之Python网络数据采集 非原创即采集 一念清净, 烈焰成池, 一念觉醒, 方登彼岸 网络数据采集, 无非就是写一个自动化程序向网络服务器请求数据, 再对数据进行解析, 提取需要的信息 通常, ...
- FastText 分析与实践
一. 前言 自然语言处理(NLP)是机器学习,人工智能中的一个重要领域.文本表达是 NLP中的基础技术,文本分类则是 NLP 的重要应用.在 2016 年, Facebook Research 开源了 ...
- NLP(二十三)使用LSTM进行语言建模以预测最优词
N元模型 预测要输入的连续词,比如 如果抽取两个连续的词汇,则称之为二元模型 准备工作 数据集使用 Alice in Wonderland 将初始数据提取N-grams import nltk imp ...
随机推荐
- CTCLoss如何使用
CTCLoss如何使用 目录 CTCLoss如何使用 什么是CTC 架构介绍 一个简单的例子 CTC计算的推导 总概率\(p(z|x)\) 路径的含义 路径概率\(p(\pi|x)\) 什么是\(\m ...
- Python 中的"self"是什么
在使用 pycharm 编写 Python 时,自动补全总会把函数定义的第一个参数定义为 self .遂查,总结如下: self 大体上和静态语言如 Java 中的 this 关键字类似,用于指代实例 ...
- 1.JS中变量的重新声明和提升
重新声明 1.允许在程序的任何位置使用 var 重新声明 JavaScript 变量: 实例 var x = 10; // 现在,x 为 10 var x = 6; // 现在,x 为 6 2.在相同 ...
- ROS机械臂 Movelt 学习笔记3 | kinect360相机(v1)相关配置
目标是做一个机械臂视觉抓取的demo,在基地里翻箱倒柜,没有找到学长所说的 d435,倒是找到了一个老古董 kinect 360. 前几天就已经在旧电脑上配置好了,现在记录在新电脑上的配置过程. 1. ...
- 从零开始Blazor Server(6)--基于策略的权限验证
写这个的原因 现在BootstrapBlazor处于大更新时期,Menu组件要改为泛型模式. 本来我们的这一篇应该是把Layout改了,但是改Layout肯定要涉及到菜单,如果现在写了呢,就进入一个发 ...
- JS 字符串转 GBK 编码超精简实现
前言 JS 中 GBK 编码转字符串是非常简单的,直接调用 TextDecoder 即可: const gbkBuf = new Uint8Array([196, 227, 186, 195, 49, ...
- 技术分享 | 为什么MGR一致性模式不推荐AFTER
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 1.引子 2.AFTER 的写一致性 3.AFTER 的读一致性 4.AFTER 执行流程 5.BEFORE 执行流程 6 ...
- Hi3516开发笔记(十):Qt从VPSS中获取通道图像数据存储为jpg文件
前言 上一篇已经将himpp套入qt的基础上进行开发.那么qt中拿到frame则是很关键的交互,这是qt与海思可能编解码交叉开发的关键步骤. 受限制 因为直接配置sample的vi比较麻烦 ...
- React生命周期和响应式原理(Fiber架构)
注意:只有类组件才有生命周期钩子函数,函数组件没有生命周期钩子函数. 生命周期 装载阶段:constructor() render() componentDidMount() 更新阶段:render( ...
- MyBatis 01 概述
官网 http://www.mybatis.org/mybatis-3/zh/index.html GitHub https://github.com/mybatis/mybatis-3 简介 MyB ...