06 Spark SQL 及其DataFrame的基本操作
1.Spark SQL出现的 原因是什么?
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个叫作Data Frame的编程抽象结构数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrame API和Dataset API三种方式实现对结构化数据的处理。但无论是哪种API或者是编程语言,都是基于同样的执行引擎,因此可以在不同的API之间随意切换。
Spark SQL的前身是 Shark,Shark最初是美国加州大学伯克利分校的实验室开发的Spark生态系统的组件之一,它运行在Spark系统之上,Shark重用了Hive的工作机制,并直接继承了Hive的各个组件, Shark将SQL语句的转换从MapReduce作业替换成了Spark作业,虽然这样提高了计算效率,但由于 Shark过于依赖Hive,因此在版本迭代时很难添加新的优化策略,从而限制了Spak的发展,在2014年,伯克利实验室停止了对Shark的维护,转向Spark SQL的开发。
Shark Hive on Spark Hive即作为存储又负责sql的解析优化,Spark负责执行
SparkSQL Spark on Hive Hive只作为储存角色,Spark负责sql解析优化,执行
SparkSQL产生的根本原因是为了完全脱离Hive限制(解耦)
2.用spark.read 创建DataFrame
3.观察从不同类型文件创建DataFrame有什么异同?
txt文件:创建的DataFrame数据没有结构
json文件:创建的DataFrame数据有结构
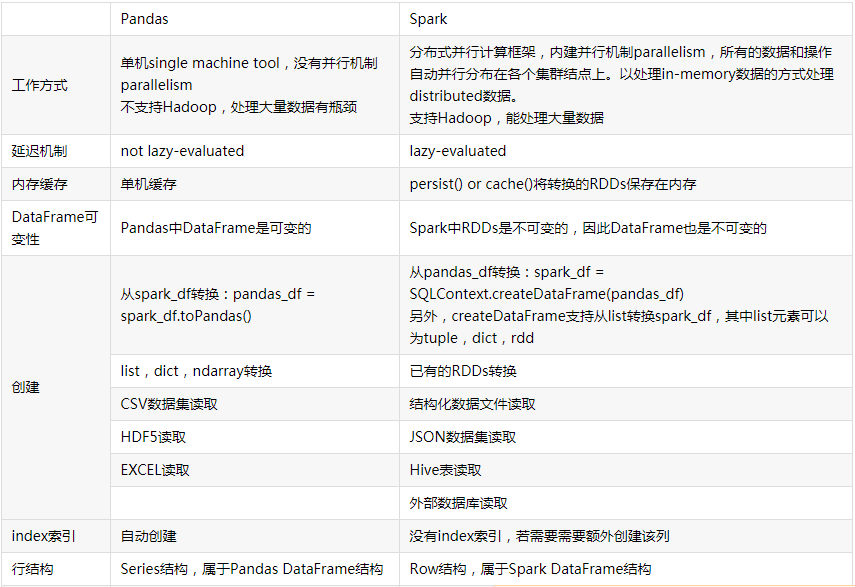
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?
Spark SQL DataFrame的基本操作
spark.read.text()
file='file:///usr/local/spark/examples/src/main/resources/people.txt'
df=spark.read.text(file)

spark.read.json()
file='file:///usr/local/spark/examples/src/main/resources/people.json'
df1=spark.read.json(file)

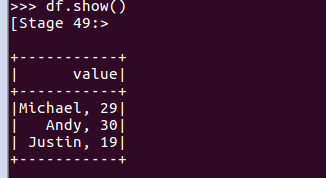
打印数据
df.show()默认打印前20条数据,df.show(n)

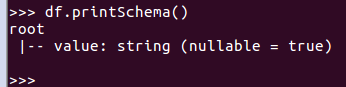
打印概要
df.printSchema()
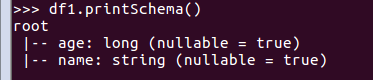
df1.printSchema()
查询总行数
df.count()
df1.count()

df.head(3) #list类型,list中每个元素是Row类
df.head(3)
df1.head(3)

输出全部行
df.collect() #list类型,list中每个元素是Row类
df.collect()
df1.collect()

查询概况
df.describe().show()

df1.describe().show()

取列
df[‘name’]
df1['name']
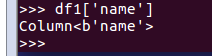
df.name
df1.name

df.select()
df1.select(df1.name).show()

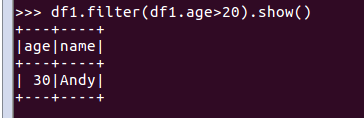
df.filter()
df1.filter(df1.age>20).show()
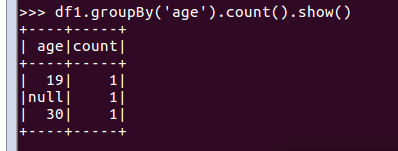
df.groupBy()
df1.groupBy('age').count().show()
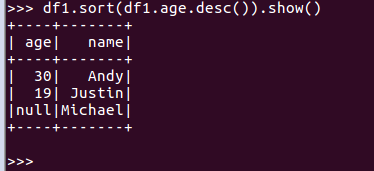
df.sort()
df1.sort(df1.age.desc()).show()
06 Spark SQL 及其DataFrame的基本操作的更多相关文章
- Spark SQL 之 DataFrame
Spark SQL 之 DataFrame 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述(Overview) Spark SQL是Spark的一个组件,用于结构化 ...
- spark结构化数据处理:Spark SQL、DataFrame和Dataset
本文讲解Spark的结构化数据处理,主要包括:Spark SQL.DataFrame.Dataset以及Spark SQL服务等相关内容.本文主要讲解Spark 1.6.x的结构化数据处理相关东东,但 ...
- Spark SQL、DataFrame和Dataset——转载
转载自: Spark SQL.DataFrame和Datase
- 转】Spark SQL 之 DataFrame
原博文出自于: http://www.cnblogs.com/BYRans/p/5003029.html 感谢! Spark SQL 之 DataFrame 转载请注明出处:http://www.cn ...
- Spark官方1 ---------Spark SQL和DataFrame指南(1.5.0)
概述 Spark SQL是用于结构化数据处理的Spark模块.它提供了一个称为DataFrames的编程抽象,也可以作为分布式SQL查询引擎. Spark SQL也可用于从现有的Hive安装中读取数据 ...
- Spark SQL and DataFrame Guide(1.4.1)——之DataFrames
Spark SQL是处理结构化数据的Spark模块.它提供了DataFrames这样的编程抽象.同一时候也能够作为分布式SQL查询引擎使用. DataFrames DataFrame是一个带有列名的分 ...
- Spark学习之路(八)—— Spark SQL 之 DataFrame和Dataset
一.Spark SQL简介 Spark SQL是Spark中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将SQL查询与Spark程序无缝混合,允许您使用SQL或DataFrame AP ...
- Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
一.Spark SQL简介 Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 Da ...
- spark sql 创建DataFrame
SQLContext是创建DataFrame和执行SQL语句的入口 通过RDD结合case class转换为DataFrame 1.准备:hdfs上提交一个文件,schema为id name age, ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
随机推荐
- Metasploit渗透测试框架一
Metasploit简介 Metasploit是一个渗透测试平台,使您能够查找,利用和验证漏洞.该平台还有Metasploit Pro. Metasploit是一个免费的.可下载的框架,本身自带数百已 ...
- pyspark 结构化数据开发实例
什么是SPARK? 1. 先进的大数据分布式编程和计算框架 2. 替换Hadoop 中的MR计算引擎. 3. 内存分布式计算:运行数度快 4. 可以使用不同的语言编程(java,scala,r 和py ...
- kafka 常见命令以及增加topic的分区数
基础命令 1.创建topic kafka-topics.sh --bootstrap-server ${kafkaAddress} --create --topic ${topicName} --pa ...
- MySQL 学习(四)并集查询
联合查询,它是用 union 关键字把多条 select 语句的查询结果合并为一个结果集.纵向合并的前提是被合并的结果集的字段数量.顺序和数据类型必须完全一致.字段名不一样的情况下,会将第一个结果集的 ...
- 关于DVWA踩坑
部署好DVWA开始欢天喜地用起来,结果有个问题,不管怎么设置这个安全等级,都显示为Impossible 原因也很显然 其实我并不太理解为什么这里要放在cookie里面,而且还放了两条. 处理方式也很明 ...
- docker之安装tomcat
国内Image仓库地址:https://hub.docker.com/search?q=tomcat 安装tomcat docker pull tomcat 查看Image docker images ...
- 简易Map模板
非红黑树,排序+二分搜索,查找修改O(logN),插入删除O(N) #ifndef MAP_H #define MAP_H #include "main.h" /*-------- ...
- 【git】3.5 git分支-远程分支
资料来源 (1) https://git-scm.com/book/zh/v2/Git-%E5%88%86%E6%94%AF-%E8%BF%9C%E7%A8%8B%E5%88%86%E6%94%AF ...
- 关系型数据库,基表Guid 主键设值
在我们开发过程,为了自动适应新增修改,可以对基表,Guid 类型进行如下设置: public bool IsTransient() { return this.Id == Guid.Emp ...
- awk引用外部变量
test]# cat tmp.tmp120.4987 12.717858119.801948 13.38588119.424529 14.024871119.337438 15.070484119.2 ...