强化学习——Q-learning算法
假设有这样的房间
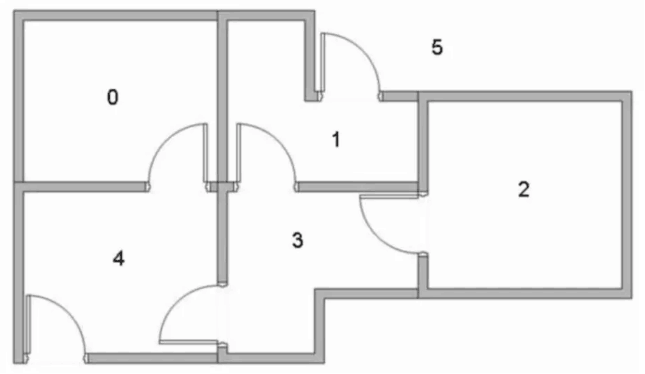
如果将房间表示成点,然后用房间之间的连通关系表示成线,如下图所示:
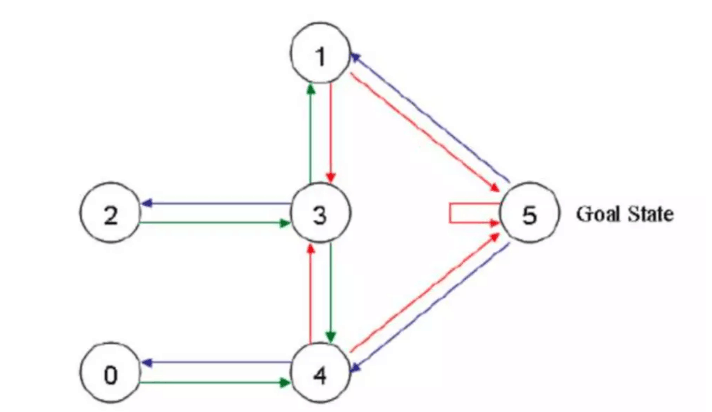
这就是房间对应的图。我们首先将agent(机器人)处于任何一个位置,让他自己走动,直到走到5房间,表示成功。为了能够走出去,我们将每个节点之间设置一定的权重,能够直接到达5的边设置为100,其他不能的设置为0,这样网络的图为:
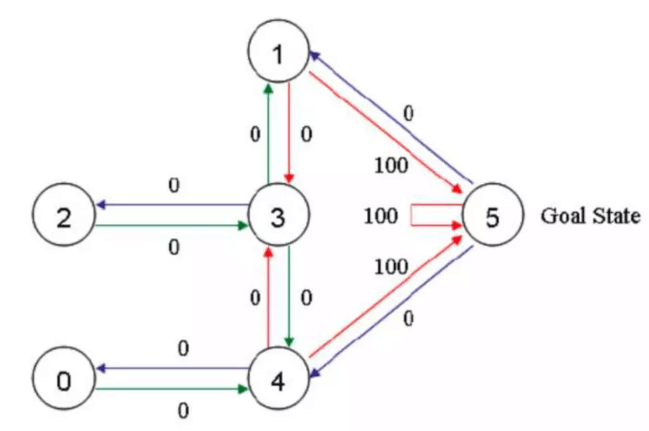
Qlearning中,最重要的就是“状态”和“动作”,状态表示处于图中的哪个节点,比如2节点,3节点等等,而动作则表示从一个节点到另一个节点的操作。
首先我们生成一个奖励矩阵矩阵,矩阵中,-1表示不可以通过,0表示可以通过,100表示直接到达终点:

同时,我们创建一个Q表,表示学习到的经验,与R表同阶,初始化为0矩阵,表示从一个state到另一个state能获得的总的奖励的折现值。

Q表中的值根据如下的公式来进行更新:
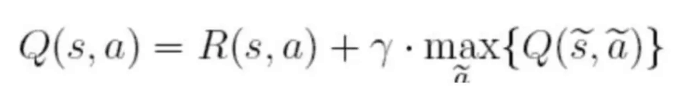
在上面的公式中,S表示当前的状态,a表示当前的动作,s表示下一个状态,a表示下一个动作,λ为贪婪因子,0<λ<1,一般设置为0.8。Q表示的是,在状态s下采取动作a能够获得的期望最大收益,R是立即获得的收益,而未来一期的收益则取决于下一阶段的动作。
所以,Q-learning的学习步骤可以归结为如下:

在迭代到收敛之后,我们就可以根据Q-learning来选择我们的路径走出房间。
看一个实际的例子,首先设定λ=0.8,奖励矩阵R和Q矩阵分别初始化为:

随机选择一个状态,比如1,查看状态1所对应的R表,也就是1可以到达3或5,随机地,我们选择5,根据转移方程:
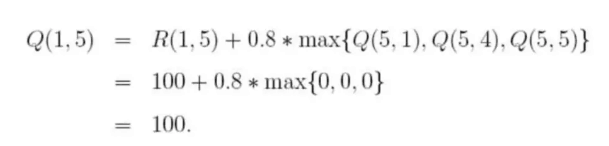
于是,Q表为:

这样,到达目标,一次尝试结束。
接下来再选择一个随机状态,比如3,3对应的下一个状态有(1,2,4都是状态3对应的非负状态),随机地,我们选择1,这样根据算法更新:

这样,Q表为:

经过不停的迭代,最终我们的Q表为:

我们不妨将Q表中的数转移到我们一开始的示意图中:

在得到Q表之后,我们可以根据如下的算法来选择我们的路径:

举例来说,假设我们的初始状态为2,那么根据Q表,我们选择2-3的动作,然后到达状态3之后,我们可以选择1,2,4。但是根据Q表,我们到1可以达到最大的价值,所以选择动作3-1,随后在状态1,我们按价值最大的选择选择动作1-5,所以路径为2-3-1-5.
2、代码实现
上面的例子可以用下面的代码来实现,非常的简单,直接贴上完整的代码吧:
import numpy as np
import random
r = np.array([[-1, -1, -1, -1, 0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1, -1, 0, -1, -1], [-1, 0, 0, -1, 0, -1],
[0, -1, -1, 0, -1, 100], [-1, 0, -1, -1, 0, 100]])
q = np.zeros([6,6],dtype=np.float32)
gamma = 0.8
step = 0
while step < 1000:
state = random.randint(0,5)
if state != 5:
next_state_list=[]
for i in range(6):
if r[state,i] != -1:
next_state_list.append(i)
next_state = next_state_list[random.randint(0,len(next_state_list)-1)]
qval = r[state,next_state] + gamma * max(q[next_state])
q[state,next_state] = qval
print(q)
print(q)
# 验证
for i in range(10):
print("第{}次验证".format(i + 1))
state = random.randint(0, 5)
print('机器人处于{}'.format(state))
count = 0
while state != 5:
if count > 20:
print('fail')
break
# 选择最大的q_max
q_max = q[state].max()
q_max_action = []
for action in range(6):
if q[state, action] == q_max:
q_max_action.append(action)
next_state = q_max_action[random.randint(0, len(q_max_action) - 1)]
print("the robot goes to " + str(next_state) + '.')
state = next_state
count += 1
链接:https://www.jianshu.com/p/29db50000e3f
强化学习——Q-learning算法的更多相关文章
- 增强学习(五)----- 时间差分学习(Q learning, Sarsa learning)
接下来我们回顾一下动态规划算法(DP)和蒙特卡罗方法(MC)的特点,对于动态规划算法有如下特性: 需要环境模型,即状态转移概率\(P_{sa}\) 状态值函数的估计是自举的(bootstrapping ...
- 强化学习(Reinforcement Learning)中的Q-Learning、DQN,面试看这篇就够了!
1. 什么是强化学习 其他许多机器学习算法中学习器都是学得怎样做,而强化学习(Reinforcement Learning, RL)是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报. ...
- 强化学习(Reinfment Learning) 简介
本文内容来自以下两个链接: https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/ https: ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习-时序差分算法(TD)和SARAS法
1. 前言 我们前面介绍了第一个Model Free的模型蒙特卡洛算法.蒙特卡罗法在估计价值时使用了完整序列的长期回报.而且蒙特卡洛法有较大的方差,模型不是很稳定.本节我们介绍时序差分法,时序差分法不 ...
- 强化学习 reinforcement learning: An Introduction 第一章, tic-and-toc 代码示例 (结构重建版,注释版)
强化学习入门最经典的数据估计就是那个大名鼎鼎的 reinforcement learning: An Introduction 了, 最近在看这本书,第一章中给出了一个例子用来说明什么是强化学习, ...
- 【强化学习】DQN 算法改进
DQN 算法改进 (一)Dueling DQN Dueling DQN 是一种基于 DQN 的改进算法.主要突破点:利用模型结构将值函数表示成更加细致的形式,这使得模型能够拥有更好的表现.下面给出公式 ...
- 深度学习(Deep Learning)算法简介
http://www.cnblogs.com/ysjxw/archive/2011/10/08/2201782.html Comments from Xinwei: 最近的一个课题发展到与深度学习有联 ...
- 强化学习9-Deep Q Learning
之前讲到Sarsa和Q Learning都不太适合解决大规模问题,为什么呢? 因为传统的强化学习都有一张Q表,这张Q表记录了每个状态下,每个动作的q值,但是现实问题往往极其复杂,其状态非常多,甚至是连 ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
随机推荐
- Netty搭建WebSocket服务端
Netty服务端 1.引入依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns=& ...
- Java基础 继承的方式创建多线程 / 线程模拟模拟火车站开启三个窗口售票
继承的方式创建多线程 笔记: /**继承的方式创建多线程 * 线程的创建方法: * 1.创建一个继承于Thread 的子类 * 2.重写Thread类的run()方法 ,方法内实现此子线程 要完成的功 ...
- JAVA遇见HTML——JSP篇:JSP内置对象(下)
什么是session session表示客户端与服务器的一次会话 Web中的session指的是用户在浏览某个网站时,从进入网站到浏览器关闭所经过的这段时间,也就是用户浏览这个网站所花费的时间 从上述 ...
- Java锁--非公平锁
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3496651.html 参考代码 下面给出Java1.7.0_40版本中,ReentrantLock和AQ ...
- linux ps sample
ps -ef|grep "myswooleserver.php"| grep -v "grep" | wc -l cpc@cpc-Aspire-:~/Downl ...
- Java8-LongAccumulator
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util ...
- window、BOM、 document、 DOM
window: 顾名思义,窗口,浏览器窗口.是Window构造函数的一个实例对象. 它包含浏览器的一些属性和方法,如screen,location,history,setInterval等. // ...
- 路由器配置——基于链路的OSPF简单口令认证
一.实验目的:掌握基于链路的OSPF简单口令认证 二.拓扑图: 三.具体步骤配置: (1)R1路由器配置 Router>enable Router#configure terminal Ente ...
- c实现双向链表
实现双向链表:创建.插入.删除 #include <iostream> #include <stdio.h> #include <string.h> #includ ...
- springboot+mybatis+druid+sqlite/mysql/oracle
搭建springboot+mybatis+druid+sqlite/mysql/oracle附带测试 1.版本 springboot2.1.6 jdk1.8 2.最简springboot环境 http ...