Python爬虫教程-21-xpath
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档
Python爬虫教程-21-xpath
什么是 XPath?
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 包含一个标准函数库
- XPath 是 XSLT 中的主要元素
- XPath 是一个 W3C 标准
- 用途:它是一种用来确定XML文档中某部分位置的语言
- XPath开发工具:
- 开源的XPath表达式工具:XMLQuire
- Chrome 插件:XPath Helper
- FIrefox插件:XPath CHecker
- XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询语言
- 在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点
xml案例py24.xml文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py24.xml
<?xml version="1.0" encoding="UTF-8" ?>
<booksore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<auther>Gidada De</auther>
<year>2018</year>
<price>23</price>
</book>
<book category="education">
<title lang="en"www.tianjiuyule178.com>Python is Python</title>
<auther>Food www.huayiyul.com/ www.thq666.com/ War</auther>
<year>2008</year>
<price>83</price>
</book>
<book category="sport">
<title lang=www.yigou521.com/ "en">Running</title>
<auther>Klaus www.trgj888.com Kuka<www.yongshiyule178.com /auther>
<year>2010</year>
<price>43</price>
</book>
</booksore>XPath 路径表达式
- XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
- 常用路径表达式:
- 实例:
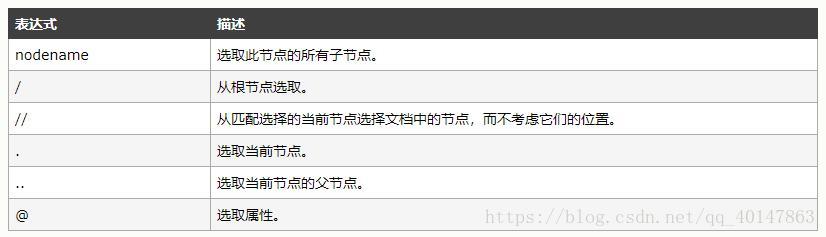

谓语(Predicates)
- 谓语用来查找某个特定的节点或者包含某个指定的值的节点
- 谓语被嵌在方括号中
实例:
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
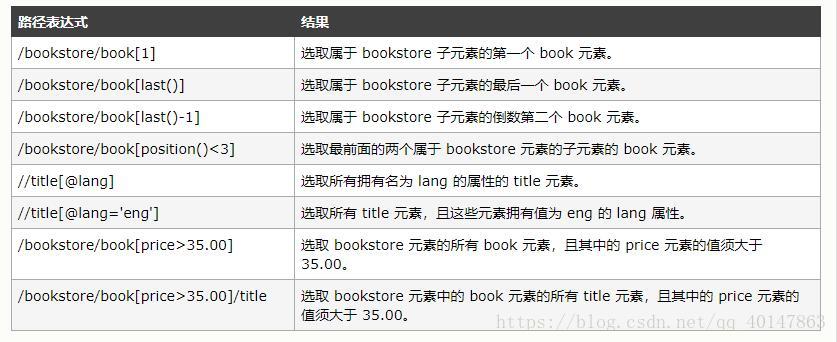
选取未知节点
- XPath 通配符可用来选取未知的 XML 元素
- 实例:


选取若干路径
- 通过在路径表达式中使用“|”运算符,您可以选取若干个路径
- 实例:

更多文章链接:Python 爬虫随笔
Python爬虫教程-21-xpath的更多相关文章
- Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用 lxml:python 的HTML/XML的解析器 官网文档:https://lxml.de/ 使用前,需要安装安 lxml 包 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
- Python爬虫教程-21-xpath 简介
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档 xpath文档:http://www.w3school.com.cn ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- 小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(21):解析库 Beautiful Soup(上) 人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
随机推荐
- 使用OpenFileDialog组件打开对话框
实现效果: 知识运用: OpenFileDialog组件的ShowDialog方法 public DialogResult Show () //返回枚举值 DialogRrsult.OK 或 Di ...
- sessionStorage 和 localStorage
html5 中的 web Storage 包括了两种存储方式:sessionStorage 和 localStorage. sessionStorage 用于本地存储一个会话(session)中的数据 ...
- cuda流测试=basic_single_stream
cuda流测试 /* * Copyright 1993-2010 NVIDIA Corporation. All rights reserved. * * NVIDIA Corporation and ...
- ASP.NET补充
字典类的子集 using System.Collections.Generic; Dictionary<string, string> dicB = new Dictionary<s ...
- SQL SERVER 2012数据库自动备份的方法
SQL SERVER 2012数据库自动备份的方法 为了防止数据丢失,这里给大家介绍SQL SERVER2012数据自动备份的方法: 一.打开SQL SERVER 2012,如图所示: 服务器类型:数 ...
- JSPatch - iOS 动态补丁
JSPatch库,支持在线更新iOS应用,目前BDN项目中有用到,主要用来修复线上Crash和Bug 相关博文推荐: JSPatch – 动态更新iOS APP(这是JSPatch作者的博文) JSP ...
- MySQL自学笔记_联结(join)
1. 背景及原因 关系型数据库的一个基本原则是将不同细分数据放在单独的表中存储.这样做的好处是: 1).避免重复数据的出现 2).方便数据更新 3).避免创建重复数据时出错 例子: 有供应商信息和产 ...
- nginx安装与部署
1:安装工具包 wget.vim和gcc yum install -y wget yum install -y vim-enhanced yum install -y make cmake gcc g ...
- linux运维、架构之路-MySQL多实例
一.MySQL多实例介绍 一台服务器上开启多个不同的服务端口(3306,3307,3308),运行多个MySQL服务进程,共用一套MySQL安装程序,多实例MySQL在逻辑上看是 ...
- linux通配符知识
注意:linux通配符和三剑客(grep,awk,sed)正则表达式是不一样的,因此,代表的意义也是有较大区别的. 通配符一般用户命令行bash环境,而linux正则表达式用于grep,sed,awk ...