python3通过Beautif和XPath分别爬取“小猪短租-北京”租房信息,并对比时间效率(附源代码)
爬虫思路分析:
1. 观察小猪短租(北京)的网页
首页:http://www.xiaozhu.com/?utm_source=baidu&utm_medium=cpc&utm_term=PC%E6%A0%87%E9%A2%98&utm_content=pinzhuan&utm_campaign=BDPZ
选择“北京”,然后点“搜索小猪”,获取北京市的首页url:http://bj.xiaozhu.com/
观察右侧详情,页面最下面有分页,点击第2、第3页观察url的变化
http://bj.xiaozhu.com/search-duanzufang-p2-0/
http://bj.xiaozhu.com/search-duanzufang-p3-0/
验证首页是否可以写作:http://bj.xiaozhu.com/search-duanzufang-p1-0/(答案是ok的,大部分分页行的网站首页都是可以与其他分页统一化的)
因此,分页的URL可以这么构造:http://bj.xiaozhu.com/search-duanzufang-p{}-0/.format(number),其中number是几就是第几页
2. 观察右侧的信息,发现每个房源的信息不全,需要手动点击进去才能看到详情
因此需要获取每个房源的详情页面的URL
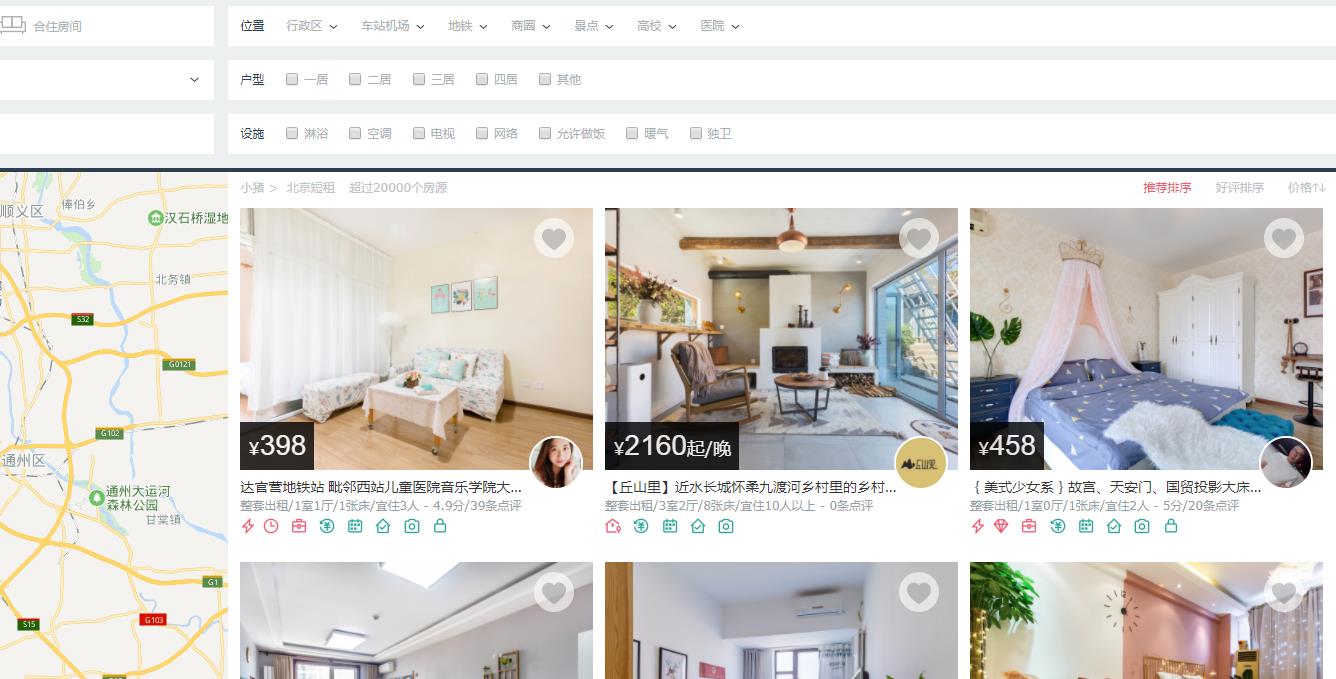
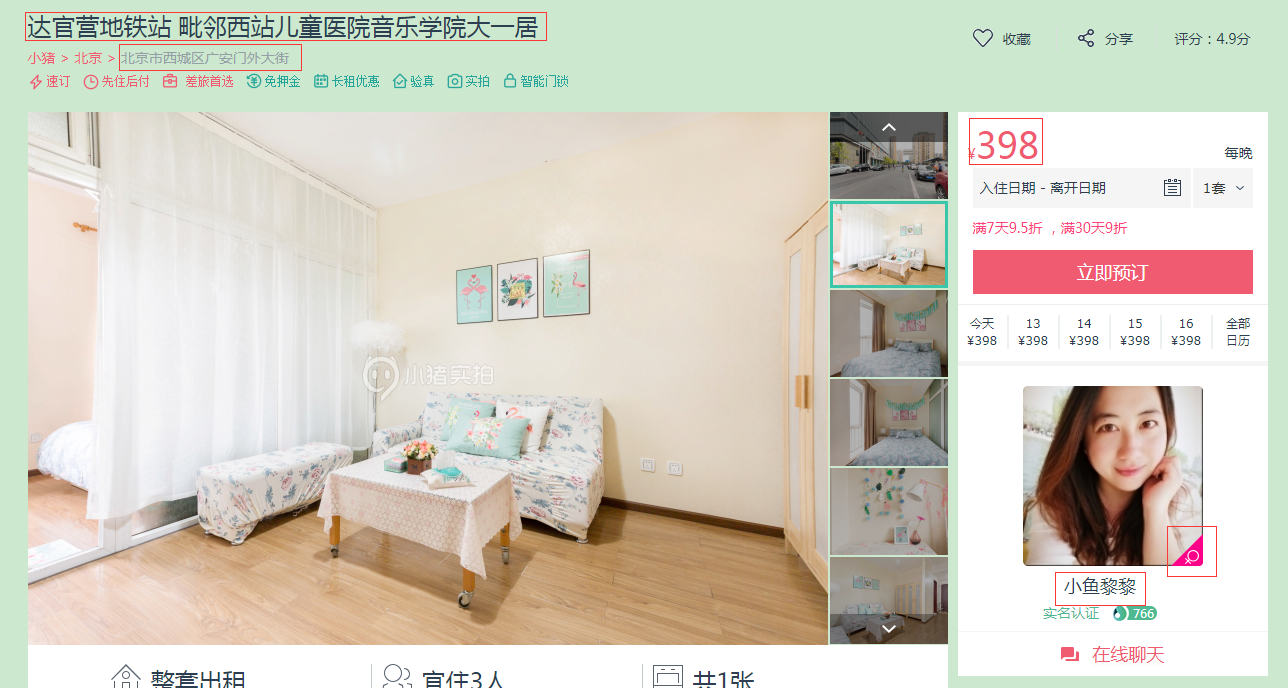
3. 观察某一房源的详细信息,这里我们提取“标题、地址、价格、房东名字、性别”等
使用BeautifulSoup实现
"""
典型的分页型网站——小猪短租
使用Beautifulsoup解析网页,并对比时间效率 """ import requests
from bs4 import BeautifulSoup as bs
import time headers = {
'User-Agent':'User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
} #--Beautifulsoup-- """获取每一个房源的网址,参数是分页url"""
def get_link(url):
html_data = requests.get(url, headers = headers)
soup = bs(html_data.text, 'lxml')#bs4推荐使用的的解析库
#print(soup.prettify()) #标准化输出url中的源代码(有可能跟网页查看中的不一致,网页中有可能标签书写不规范)以此为基础抓取,如果抓取失败,用此命令查看源代码
links = soup.select('#page_list > ul > li > a')#注意循环点!!!直接粘贴过来的是“#page_list > ul > li:nth-child(1) > a > img”,需要去掉:nth-child(1),注意每个标签前后有空格
#print(links)
for link in links:
link = link.get('href')
#print(link)
get_info(link) """判断房东性别"""
def sex_is(member):
if member == 'member_ico':
return "男"
else:
return "女" """获取每一个房源的详细信息,参数url是每个房源的网址"""
def get_info(url):
html_data = requests.get(url, headers = headers)
soup = bs(html_data.text, 'lxml')#bs4推荐使用的的解析库
# print(soup.prettify()) #标准化输出url中的源代码(有可能跟网页查看中的不一致,网页中有可能标签书写不规范)以此为基础抓取,如果抓取失败,用此命令查看源代码
title = soup.select('div.wrap.clearfix.con_bg > div.con_l > div.pho_info > h4 > em')[0].string
# 用网页copy过来的全部是“body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > h4 > em”,但是使用这个爬不出来数据(我也不知道why),把body去掉或者用下面最简短的方式(只使用最近的且唯一的div)
# title = soup.select('div.pho_info > h4 > em ')
# 查询结果title格式是一维列表,需要继续提取列表元素(一般就是[0]),列表元素是前后有标签需要继续提取标签内容,使用get_text()或者string address = soup.select('div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span')[0].string.strip()
price = soup.select('#pricePart > div.day_l > span')[0].string.strip() # div中的id=pricePart是唯一性的,因此不用写前面的div
name = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a')[0].string.strip()
img = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img')[0].get('src').strip() # 获取标签的属性值
sex = sex_is(soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div')[0].get('class')[0].strip()) # 获取标签的属性值 #将详细数据整理成字典格式
data = {
'标题':title,
'地址':address,
'价格':price,
'房东姓名':name,
'房东性别':sex,
'房东头像':img
}
print(data) """程序主入口"""
if __name__=='__main__':
start = time.time()
for number in range(1,4):
url = 'http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) #构造分页url(不是房源详情的url)
get_link(url)
time.sleep(5)
end = time.time()
print('运行时长:',end-start)
使用Xpath实现
"""
典型的分页型网站——小猪短租
使用Xpath解析网页,并对比时间效率
""" import requests
from lxml import etree
import time headers = {
'User-Agent':'User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
} #--Xpath-- """获取每一个房源的网址,参数是分页url"""
def get_link(url):
html_data = requests.get(url, headers=headers)
selector = etree.HTML(html_data.text)
infos = selector.xpath('//*[@id="page_list"]/ul/li')
for info in infos:
link = info.xpath('a[1]/@href')[0].strip()#获取a标签中的href使用@,注意写法
#link = link.get('href')
#print(link)
get_info(link) """判断房东性别"""
def sex_is(member):
if member == 'member_ico':
return "男"
else:
return "女" """#获取每一个房源的详细信息,参数url是每个房源的网址"""
def get_info(url):
html_data = requests.get(url, headers=headers)
selector = etree.HTML(html_data.text)
# title = selector.xpath('//div[3]/div[1]/div[1]/h4/em')#直接使用copyxpath的结果为空,原因未知,address字段同样情况
title = selector.xpath('//div[@class="wrap clearfix con_bg"]/div[1]/div[1]/h4/em/text()')[0].strip()
# title = selector.xpath('//div[@class="pho_info"]/h4/em/text()')[0].strip()
address = selector.xpath('//div[@class="pho_info"]/p/span/text()')[0].strip()
price = selector.xpath('//*[@id="pricePart"]/div[1]/span/text()')[0].strip()
#name = selector.xpath('//*[@id="floatRightBox"]/div[3]/div[2]/h6/a/@title')[0].strip()#此段是直接copy xpath的,某些房源会报错,因为有些房东认证了“超棒房东”,会多一行div
name = selector.xpath('//*[@id="floatRightBox"]/div[3]/div[@class="w_240"]/h6/a/@title')[0].strip()
#img = selector.xpath('//*[@id="floatRightBox"]/div[3]/div[1]/a/img/@src')[0].strip()#原因同name
img = selector.xpath('//*[@id="floatRightBox"]/div[3]/div[@class="member_pic"]/a/img/@src')[0].strip() sex = sex_is(selector.xpath('//*[@id="floatRightBox"]/div[3]/div[1]/div/@class')[0].strip())
#将详细数据整理成字典格式
data = {
'标题':title,
'地址':address,
'价格':price,
'房东姓名':name,
'房东性别':sex,
'房东头像':img
}
print(data) """程序主入口"""
if __name__=='__main__':
start = time.time()
for number in range(1,4):
url = 'http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) #构造分页url(不是房源详情的url)
get_link(url)
time.sleep(5)
end = time.time()
print('运行时长:',end-start)
对比时间效率
爬取1-3页数据,每页延时5s
BeautifulSoup用时27.9475s
XPath用时24.0693s
综上所述
XPath用时更短一些,并且XPath写法更简洁。对比而言,更推荐使用XPath进行网页解析。
值得注意的是,copy XPath的方法虽然好用,但是某些情况有可能抓取失败,比如本例中的title、name和img,此时需要手写(可以尝试明确class和id的写法提高抓取效率)
python3通过Beautif和XPath分别爬取“小猪短租-北京”租房信息,并对比时间效率(附源代码)的更多相关文章
- Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Eastmount PS:如有需要Python学习资料的小伙伴可以加 ...
- requests+xpath+map爬取百度贴吧
# requests+xpath+map爬取百度贴吧 # 目标内容:跟帖用户名,跟帖内容,跟帖时间 # 分解: # requests获取网页 # xpath提取内容 # map实现多线程爬虫 impo ...
- 使用Xpath爬取酷狗TOP500的歌曲信息
使用xpath爬取酷狗TOP500的歌曲信息, 将排名.歌手名.歌曲名.歌曲时长,提取的结果以文件形式保存下来.参考网址:http://www.kugou.com/yy/rank/home/1-888 ...
- Python3爬虫:(一)爬取拉勾网公司列表
人生苦短,我用Python 爬取原因:了解一下Python工程师在北上广等大中城市的薪资水平与入职前要求. Python3基础知识 requests,pyquery,openpyxl库的使用 爬取前的 ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- Python爬取某短视频热点
写在前面的一些话: 随着短视频的大火,不仅可以给人们带来娱乐,还有热点新闻时事以及各种知识,刷短视频也逐渐成为了日常生活的一部分.本文以一个简单的小例子,简述如何通过Pyhton依托Selenium来 ...
- 爬取豆瓣网图书TOP250的信息
爬取豆瓣网图书TOP250的信息,需要爬取的信息包括:书名.书本的链接.作者.出版社和出版时间.书本的价格.评分和评价,并把爬取到的数据存储到本地文件中. 参考网址:https://book.doub ...
- Python进阶练习与爬取豆瓣T250的影片相关信息
(一)Python进阶练习 正所谓要将知识进行实践,才会真正的掌握 于是就练习了几道题:求素数,求奇数,求九九乘法表,字符串练习 import re #求素数 i=1; flag=0 while(i& ...
随机推荐
- js:常用到的js操作记录
1:对参数去除空格 str.replace(/^\s+|\s+$/g, '');
- java中实现定时任务 task 或quartz
转载大神的 https://www.cnblogs.com/hafiz/p/6159106.html https://www.cnblogs.com/luchangyou/p/6856725.html ...
- NET Core写了一个轻量级的Interception框架[开源]
NET Core写了一个轻量级的Interception框架[开源] ASP.NET Core具有一个以ServiceCollection和ServiceProvider为核心的依赖注入框架,虽然这只 ...
- (转载)Python中模块的发布与安装
模块(Module) Python中有一个概念叫做模块(module),这个和C语言中的头文件以及Java中的包很类似,比如在Python中要调用sqrt函数,必须用import关键字引入math这个 ...
- 七,JOBC数据库编程
七,JOBC数据库编程 七,JOBC数据库编程 一,java数据库编程步骤 1,将数据库驱动包考入lib目录: 2,加载驱动--整个操作数据库程序运行期间只需要加载一次 Class.forName(& ...
- java Integer判等的大坑
在-128 至 127 范围内的赋值,Integer 对象是在IntegerCache.cache 产生,会复用已有对象,这个区间内的 Integer 值可以直接使用==进行 判断,但是这个区间之外的 ...
- Kendo MVVM 数据绑定(八) Style
Kendo MVVM 数据绑定(八) Style Style 绑定可以通过 ViewModel 绑定到 DOM 元素 CSS 风格属性,例如: <span data-bind="sty ...
- Linux生产服务器常规分区方案
常规分区方案 / 剩余硬盘大小 swap 100M /boot 100M DB及存储:有大量重要的数据 /data/ 剩余硬盘大小 / 50-200GB swap 1.5倍 /boot 100MB 门 ...
- SqlServer中嵌套事务使用--事务计数指示 BEGIN 和 COMMIT 语句的数目不匹配 --根本问题
转自 :SqlServer中嵌套事务使用--事务计数指示 BEGIN 和 COMMIT 语句的数目不匹配 --根本问题 问题: 1. System.Data.SqlClient.SqlExcepti ...
- UVA 11491 Erasing and Winning 奖品的价值 (贪心)
题意:给你一个n位整数,让你删掉d个数字,剩下的数字要尽量大. 题解:因为最后数字位数是确定的,而且低位数字对答案的贡献是一定不及高位数字的,所以优先选择选最大且最靠左边的数字,但是有一个限制,选完这 ...