Python进阶练习与爬取豆瓣T250的影片相关信息
(一)Python进阶练习
正所谓要将知识进行实践,才会真正的掌握
于是就练习了几道题:求素数,求奇数,求九九乘法表,字符串练习
import re
#求素数
i=1;
flag=0
while(i<=100):
flag=0
j=2;
while(j<i):
if(i%j==0):
flag=1
break;
j=j+1
if(flag==0):
print(i,end=' ')
i=i+1 #求奇数
for i in range(1,101):
if(i%2==1):
print(i,end=' ') #字符串练习
str="你好$$$我正在学 Python@#@#现在需要&*&*&修改字符串"
k=str.replace('$$$','').replace('@#@#',' ').replace('&*&*&',' ')
print(k)
p=re.sub('[$@#&*]',' ',str)
print(p) #九九乘法表
for i in range(1,10):
for j in range(1,i+1):
print("%d*%d=%d\t" %(j,i,i*j),end="")
print("")
(二)爬取静态网页
这次我们练习的实战是爬取静态网页,豆瓣T250电影的名字
首先我们分析一页有25个电影,我们想要250个,进行下一页的时候他的链接地址变成“https://movie.douban.com/top250?start=25”同理每翻一页就会增加25.我们就可以对这250个数据进行爬取了
我们要获取的信息是:电影名字,导演与主演以及时间类型,豆瓣评分,多少人评价
将这些信息存入到txt里面
import requests
from bs4 import BeautifulSoup def get_movie():
url = 'https://movie.douban.com/top250' #请求地址
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息
movie_list=[]
for i in range(0,10):
url = 'https://movie.douban.com/top250?start='+str(i*25)
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.text,"html.parser")
div_list = soup.find_all('div', class_='info')
for each in div_list:
title = each.find('div', class_="hd").span.text.strip()
info = each.find('div', class_='bd').p.text.strip()
info = info.replace('\\n', '').replace('\\xa0', '')
info = ' '.join(info.split())
star = each.find('span', class_='rating_num').text.strip()
people = each.find('div', class_='star').contents[7].text.strip()
movie_list.append([title, info, star, people])
return movie_list
movie=[]
movie=get_movie()
with open("Top_movie_250.txt","a+",encoding="utf-8") as f:
for i in range(len(movie)):
f.write(str(movie[i]))
f.write("\n")
f.close()
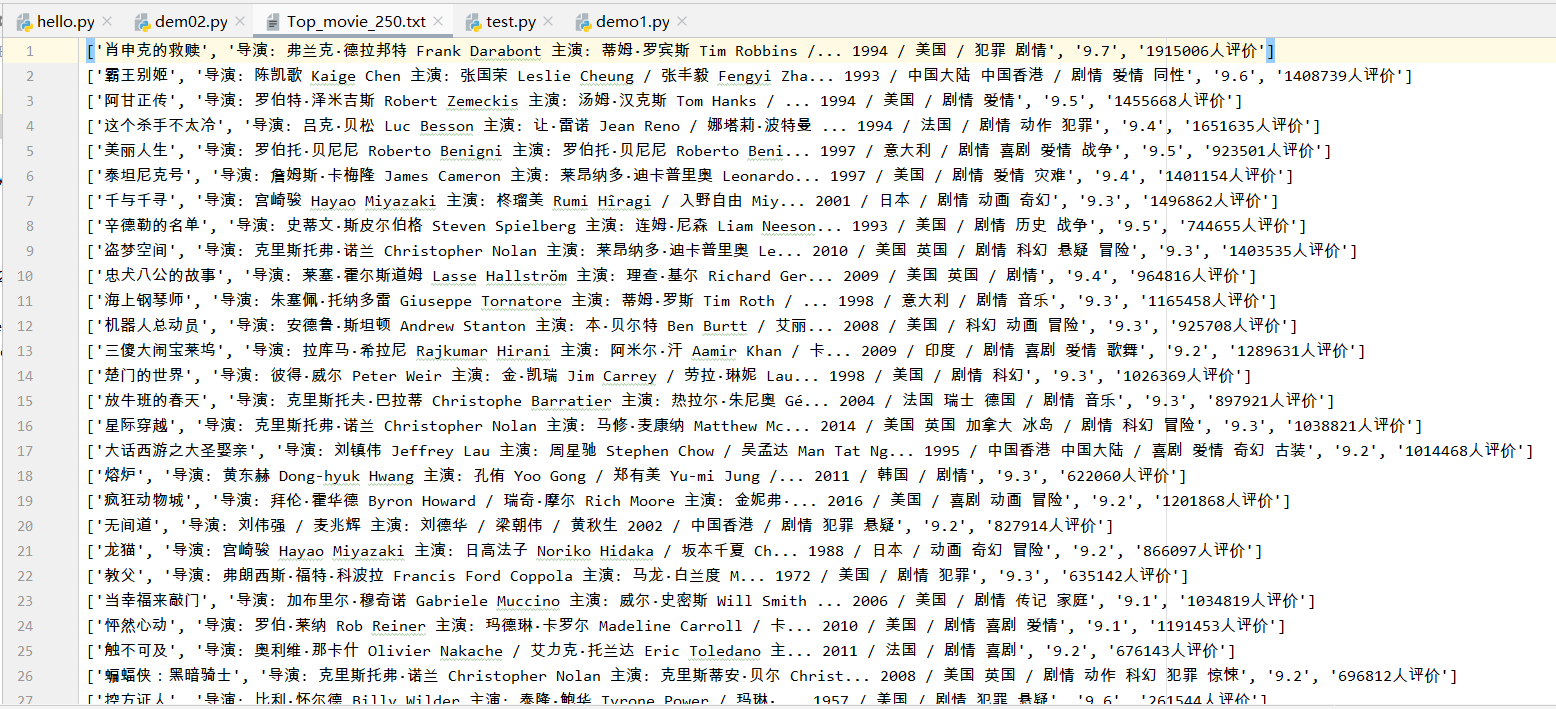
txt展示:
| 日期 | 开始时间 | 结束时间 | 中断时间 | 净时间 | 活动 |
| 3/12 | 20:30 | 21:45 | 0 | 75 | python练习与爬取T25的名字 |
| 3/12 | 22:00 | 22:30 | 5 | 25 | 爬取T250电影的名字,导演,评分等 |
总学习时长:100分钟,净代码行数:90行
Python进阶练习与爬取豆瓣T250的影片相关信息的更多相关文章
- 爬取豆瓣网图书TOP250的信息
爬取豆瓣网图书TOP250的信息,需要爬取的信息包括:书名.书本的链接.作者.出版社和出版时间.书本的价格.评分和评价,并把爬取到的数据存储到本地文件中. 参考网址:https://book.doub ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- python实例:自动爬取豆瓣读书短评,分析短评内容
思路: 1.打开书本“更多”短评,复制链接 2.脚本分析链接,通过获取短评数,计算出页码数 3.通过页码数,循环爬取当页短评 4.短评写入到txt文本 5.读取txt文本,处理文本,输出出现频率最高的 ...
- python爬虫+正则表达式实例爬取豆瓣Top250的图片
直接上全部代码 新手上路代码风格可能不太好 import requests import re from fake_useragent import UserAgent #### 用来伪造爬头部信息 ...
- python3爬取豆瓣排名前250电影信息
#!/usr/bin/env python # -*- coding: utf-8 -*- # @File : doubanmovie.py # @Author: Anthony.waa # @Dat ...
- Python网络爬虫 - 爬取中证网银行相关信息
最终版:07_中证网(Plus -Pro).py # coding=utf-8 import requests from bs4 import BeautifulSoup import io impo ...
- Python的scrapy之爬取豆瓣影评和排名
基于scrapy框架的爬影评 爬虫主程序: import scrapy from ..items import DoubanmovieItem class MoviespiderSpider(scra ...
随机推荐
- StartDT AI Lab | 视觉智能引擎+数据决策引擎——打造商业“智能沙盘”
众所周知,线上商家可以通过淘宝平台的大量前端“埋点”轻松获取商品的加购率.收藏率.转化率.成交额等大量基础信息,甚至商家能够在更精细的层面,获取商品关键字变化或者上新/爆款带来的流量变化数据,更甚者商 ...
- FPGA时序分析
更新于20180823 时序检查中对异步复位电路的时序分析叫做()和()? 这个题做的让人有点懵,我知道异步复位电路一般需要做异步复位.同步释放处理,但不知道这里问的啥意思.这里指的是恢复时间检查和移 ...
- [Machine Learning] Andrew Ng on Coursera (Week 1)
Week 1 的内容主要有: 机器学习的定义 监督式学习和无监督式学习 线性回归和成本函数 梯度下降算法 线性代数回归 主要是了解一下机器学习的基本概念,重点是学习线性回归模型,以及对应的成本函数和梯 ...
- 轮询本机所有网卡的IP地址
#include <stdio.h> #include <sys/types.h> #include <ifaddrs.h> #include <netine ...
- mysql 优化配置和方面
MySQL性能优化的参数简介 公司网站访问量越来越大,MySQL自然成为瓶颈,因此最近我一直在研究 MySQL 的优化,第一步自然想到的是 MySQL 系统参数的优化,作为一个访问量很大的网站(日20 ...
- python开发时小问题之端口占用
昨天开发时遇到个小问题: 在使用pycharm编写tornado代码时: 直接用这种方式开启了服务,当我想修改代码时发现端口已经被占用代码提交不上去 所以现在该关闭进程: 步骤一: 打开CMD 步骤二 ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- C语言Windows程序设计—— 使用计时器
传统意义上的计时器是指利用特定的原理来测量时间的装置, 在古代, 常用沙漏.点燃一炷香等方式进行粗略的计时, 在现代科技的带动下, 计时水平越来越高, 也越来越精确, 之所以需要进行计时是在很多情况下 ...
- 苹果又要召回iPhone 7!这到底是要闹哪样?
7!这到底是要闹哪样?" title="苹果又要召回iPhone 7!这到底是要闹哪样?"> 现在的苹果虽然刚刚收获了史上最赚钱的一个季度--营收和利润均创下史上最 ...
- 微软Project Oxford帮助开发人员创建更智能的应用
Oxford帮助开发人员创建更智能的应用" title="微软Project Oxford帮助开发人员创建更智能的应用"> 假设你是一名对关于健身的应用充满奇思妙想 ...