scrapy框架的命令行解释
scrapy框架的命令解释
创建爬虫项目
scrapy startproject 项目名
例子如下:
scrapy startproject test1
这个时候爬虫的目录结构就已经创建完成了,目录结构如下:
|____scrapy.cfg
|____test1
| |______init__.py
| |____items.py
| |____middlewares.py
| |____pipelines.py
| |____settings.py
| |____spiders
| | |______init__.py
接着我们按照提示可以生成一个spider,这里以百度作为例子,生成spider的命令格式为;
scrapy genspider 爬虫名字 爬虫的网址
scrapy genspider baiduSpider baidu.com
关于命令详细使用
命令的使用范围
这里的命令分为全局的命令和项目的命令,全局的命令表示可以在任何地方使用,而项目的命令只能在项目目录下使用
全局的命令有:
startproject
genspider
settings
runspider
shell
fetch
view
version
项目命令有:
crawl
check
list
edit
parse
bench
startproject
这个命令没什么过多的用法,就是在创建爬虫项目的时候用
genspider
用于生成爬虫,这里scrapy提供给我们不同的几种模板生成spider,默认用的是basic,我们可以通过命令查看所有的模板
scrapy genspider -l
当我们创建的时候可以指定模板,不指定默认用的basic,如果想要指定模板则通过
scrapy genspider -t 模板名字
$ scrapy genspider -t crawl zhihuspider zhihu.com
crawl
这个是用去启动spider爬虫格式为:
scrapy crawl 爬虫名字
这里需要注意这里的爬虫名字和通过scrapy genspider 生成爬虫的名字是一致的
check
用于检查代码是否有错误,scrapy check
list
scrapy list列出所有可用的爬虫
fetch
scrapy fetch url地址
该命令会通过scrapy downloader 讲网页的源代码下载下来并显示出来
这里有一些参数:
--nolog 不打印日志
--headers 打印响应头信息
--no-redirect 不做跳转
view
scrapy view url地址
该命令会讲网页document内容下载下来,并且在浏览器显示出来
因为现在很多网站的数据都是通过ajax请求来加载的,这个时候直接通过requests请求是无法获取我们想要的数据,所以这个view命令可以帮助我们很好的判断
shell
这是一个命令行交互模式
通过scrapy shell url地址进入交互模式
这里我么可以通过css选择器以及xpath选择器获取我们想要的内容(xpath以及css选择的用法会在下个文章中详细说明),例如我们通过scrapy shell http://www.baidu.com
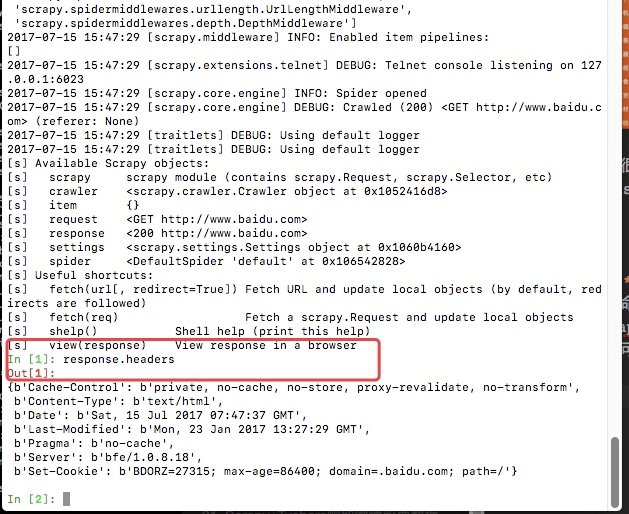
这里最后给我们返回一个response,这里的response就和我们通requests请求网页获取的数据是相同的。
view(response)会直接在浏览器显示结果
response.text 获取网页的文本
下图是css选择器的一个简单用法

settings
获取当前的配置信息
通过scrapy settings -h可以获取这个命令的所有帮助信息
scrapy settings -h
拿一个例子进行简单的演示:(这里是我的这个项目的settings配置文件中配置了数据库的相关信息,可以通过这种方式获取,如果没有获取的则为None)
scrapy settings --get=MYSQL_HOST
runspider
这个和通过crawl启动爬虫不同,这里是scrapy runspider 爬虫文件名称
所有的爬虫文件都是在项目目录下的spiders文件夹中
version
查看版本信息,并查看依赖库的信息
scrapy version
scrapy框架的命令行解释的更多相关文章
- Scrapy框架的命令行详解【转】
Scrapy框架的命令行详解 请给作者点赞 --> 原文链接 这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: loca ...
- Python爬虫从入门到放弃(十三)之 Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- Python之爬虫(十五) Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- pytest框架之命令行参数1
前言 pytest是一款强大的python自动化测试工具,可以胜任各种类型或者级别的软件测试工作.pytest提供了丰富的功能,包括assert重写,第三方插件,以及其他测试工具无法比拟的fixtur ...
- 3-----Scrapy框架的命令行详解
创建爬虫项目 scrapy startproject 项目名 例子如下: E:\crawler>scrapy startproject test1 New Scrapy project 'tes ...
- Python测试框架pytest命令行参数用法
在Shell执行pytest -h可以看到pytest的命令行参数有这10大类,共132个 序号 类别 中文名 包含命令行参数数量 1 positional arguments 形参 1 2 gene ...
- pytest框架之命令行参数2
前言 上篇博客说到命令行执行测试用例的部分参数如何使用?今天将继续更新其他一些命令选项的使用,和pytest收集测试用例的规则! pytest执行用例命令行参数 --collect-only:罗列出所 ...
- suricata 命令行解释【转】
suricata命令行 转载地址:http://blog.sina.com.cn/s/blog_6f8edcde0101gcha.html suricata命令行选项说明 你能两种方式使用命令行选项, ...
- cli框架 获取 命令行 参数
package main import ( "fmt" "log" "os" "github.com/urfave/cli&quo ...
随机推荐
- shapes
接口 shape package shape; public abstract interface shape { public abstract void Draw(); public abstra ...
- handler message messagequeue详解
long when 应该被处理的时间值,如果是即时发送,即为当前时间,如果是延迟发送则为当前时间+延迟时间
- HTML CSS 属性大全
CSS 属性大全 文字属性 「字体族科」(font-family),设定时,需考虑浏览器中有无该字体. 「字体大小」(font-size),注意度量单位.<绝对大小>|<相对大小&g ...
- Ansible 动态获取主机列表
参考文献: http://www.linuxidc.com/Linux/2016-12/138111.htm 附加 这个 include_vars 变量,可以 动态分别环境或者其他条件- hosts: ...
- 万亿级日志与行为数据存储查询技术剖析(续)——Tindex是改造的lucene和druid
五.Tindex 数果智能根据开源的方案自研了一套数据存储的解决方案,该方案的索引层通过改造Lucene实现,数据查询和索引写入框架通过扩展Druid实现.既保证了数据的实时性和指标自由定义的问题,又 ...
- js获取dom对象style样式的值
js获取到的dom对象的style通常是没有值得,因为我们都写在外部文件中,从慕课网上见到讲师封装的一个方法,挺不错.特此记录下来. function getStyle(obj,attr){ if(o ...
- 「USACO16OPEN」「LuoguP3147」262144(区间dp
P3147 [USACO16OPEN]262144 题目描述 Bessie likes downloading games to play on her cell phone, even though ...
- slice 和 splice 区别
splice() 方法与 slice() 方法的作用是不同的,splice() 方法会直接对数组进行修改. slice(start,end) ; start 必需.规定从何处开始选取.如果是负数,那 ...
- Makefile的常用技术总结
一.MAKE中的自动变量: $@: 表示target的名字 $%: 仅当目标是函数库文件中,表示规则中的目标成员名.例如,如果一个目标是"foo.a(bar.o)",那 ...
- 使用Swing组件实现简单的进制转换
请编写图像界面程序, 用户在第一文本行输入数字, 有三个按钮,分别是计算2进制,8进制,16进制, 点击其中一个按钮,第一个文本行中的数据转换为相应进制的数显示在第二个文本行中. import jav ...