【原创】大数据基础之Benchmark(4)TPC-DS测试结果(hive/hive on spark/spark sql/impala/presto)
1 测试集群
内存:256G
CPU:32Core (Intel(R) Xeon(R) CPU E5-2640 v3 @ 2.60GHz)
Disk(系统盘):300G
Disk(数据盘):1.5T*1
2 测试数据
- tpcds parquet 10g
- tpcds orc 10g
3 测试对象
- hive-2.3.4 【set mapreduce.map.memory.mb=4096; set mapreduce.map.java.opts=-Xmx3072m;】【yarn 200g*3】
- hive-2.3.4 on spark-2.4.0 【--master yarn --driver-memory 4g --num-executors 10 --executor-memory 4g】
- spark-2.4.0 【--master yarn --driver-memory 4g --num-executors 10 --executor-memory 4g】
- impala-2.12 【MEM_LIMIT=20gb * 3】
默认配置,未经优化;
4 测试结果
4.1 parquet
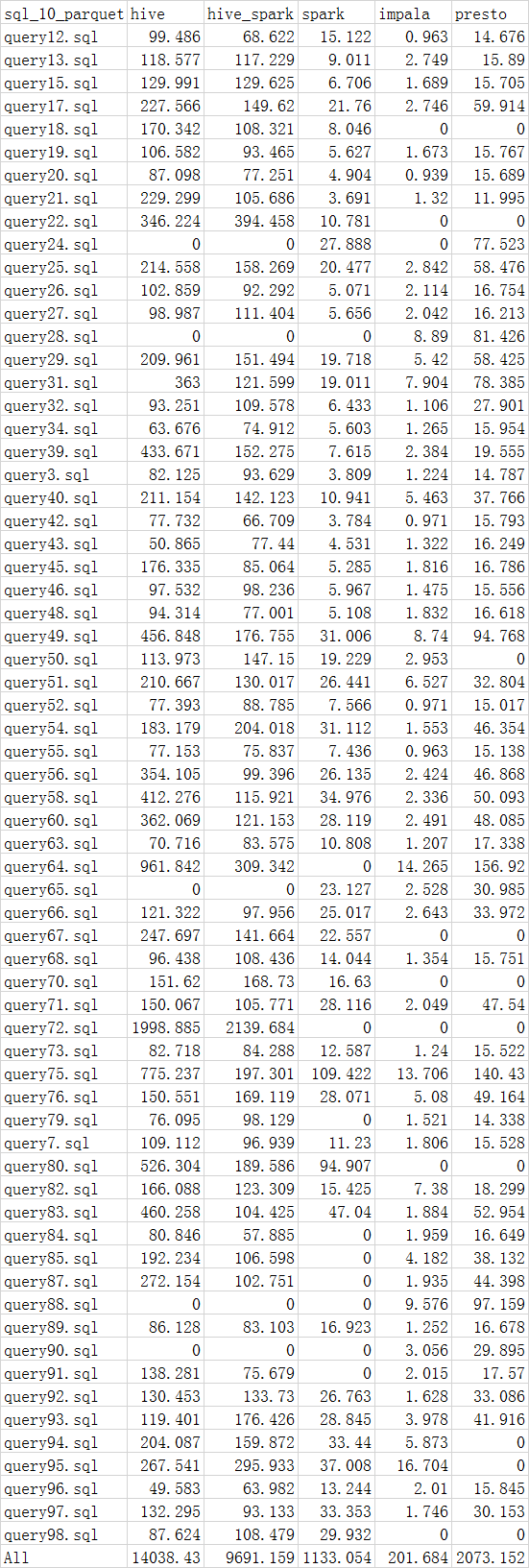
ps:0 means 执行失败
4.2 orc
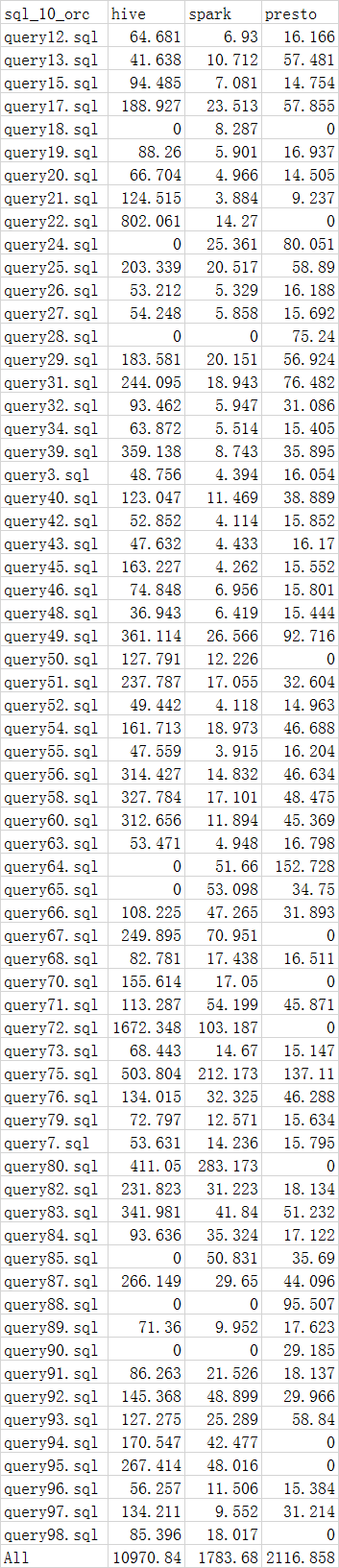
ps:0 means 执行失败
可见:
hive orc相比parquet性能提升22%;
spark parquet相比orc性能提升36%;
【原创】大数据基础之Benchmark(4)TPC-DS测试结果(hive/hive on spark/spark sql/impala/presto)的更多相关文章
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- 【原创】大数据基础之Benchmark(1)HiBench
HiBench 7官方:https://github.com/intel-hadoop/HiBench 一 简介 HiBench is a big data benchmark suite that ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之Hive(5)性能调优Performance Tuning
1 compress & mr hive默认的execution engine是mr hive> set hive.execution.engine;hive.execution.eng ...
- 【原创】大数据基础之Spark(3)Spark Thrift实现原理及代码实现
spark 2.1.1 一 启动命令 启动spark thrift命令 $SPARK_HOME/sbin/start-thriftserver.sh 然后会执行 org.apache.spark.de ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
随机推荐
- vue-router拦截
说明:以下均在main.js中添加. 主要思路 1.在路由分发时,检查本地缓存是否有账号信息,如果没有,跳转登陆页面,传入当前路由 2.在发送请求时,添加账号token 3.在接收请求时,检查响应的数 ...
- django生产环境启动问题
unavailable modifier requested: 0 环境: nginx+uwsgi+django *** Starting uWSGI 2.0.16 (64bit) on [Wed J ...
- java的TCP和UDP编程
TCP 客户端: import java.io.BufferedReader; import java.io.InputStreamReader; import java.io.PrintWriter ...
- AutoPostBack
AutoPostBack 属性用于设置或返回当用户在 TextBox 控件中按 Enter 或 Tab 键时,是否发生自动回传到服务器的操作. 如果把该属性设置为 TRUE,则启用自动回传,否则为 F ...
- 【十三】jvm 性能调优工具之 jstack
一.介绍 jstack是java虚拟机自带的一种堆栈跟踪工具.jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息,如果是在64位机器上,需要指定选项&qu ...
- 【三】Java VM 发展史
1. Sun Classic VM jdk1.0 第一款商用虚拟机. 只能使用纯解释器来运行Java代码.没有自己的判断,会把每一个方法每一行代码都编译,效率不好.导致大家普遍认为Java代码运行 ...
- [译]MediatR, FluentValidation, and Ninject using Decorators
原文 CQRS 我是CQRS模式的粉丝.对我来说CQRS能让我有更优雅的实现.它同样也有一些缺点:通常需要更多的类,workflow不总是清晰的. MediatR MediatR的文档非常不错,在这就 ...
- [C++]2-6 排列
/* 排列(Permutation) 用1,2,3,...,9组成3个三位数abc,def和ghi,每个数字恰好使用一次,要求abc:def:ghi = 1:2:3. 按照"abc def ...
- Linux之恢复误删的文件[针对丢弃到回收站]
1.丢弃到回收站(非RM)掉的文件一般在目录~/.local/share/Trash/files/下: 2.如何恢复呢? 原理很简单,既然它们还在,要么copy,要么移动到一个新的地方即可嘛. //以 ...
- 出题人的手环(牛客练习赛38D 离散化+树状数组)
题目链接(https://ac.nowcoder.com/acm/contest/358/D) 题目描述 出题人的妹子送了出题人一个手环,这个手环上有 n 个珠子,每个珠子上有一个数. 有一天,出题人 ...