python爬虫3之去哪儿网
学习任务
获取去哪儿网的出发地列表
获取旅游景点列表
获取景点产品列表
存储数据
1 获取出发地站点
(1)访问touch.qunar.com
(2)按F12,单击自由行,在自由行页面点击搜索框


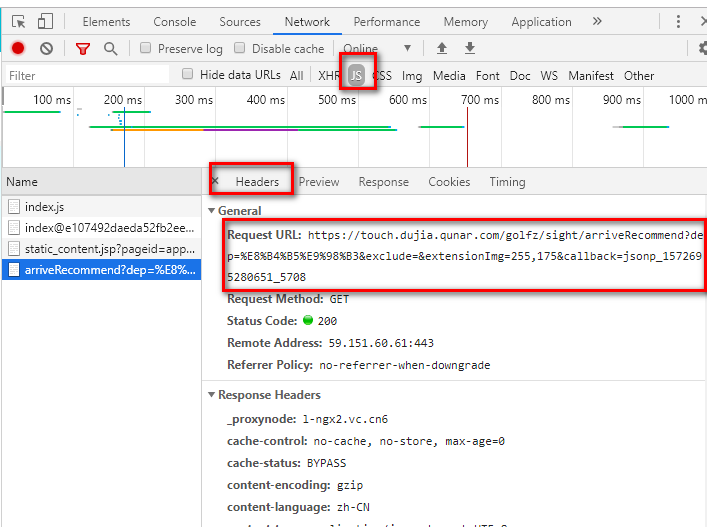
(3)单击任意一个城市,切换到headers,查看request URL如下所示。但是需要工具还原编码咋们才能知道这是啥(dep参数表示出发地,query表示目的地)。推荐网站http://www.jsons.cn/urlencode/,解码效果下面图2
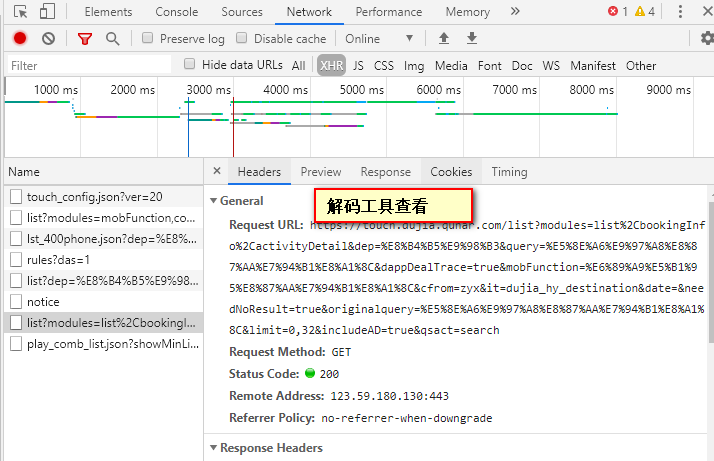

3 实现
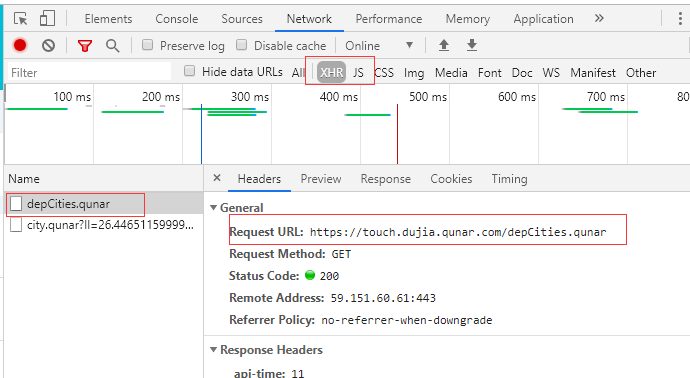
(1)首先获得出发地站点,因为最终需要获得整个自由行的产品列表。
自由行首页中点击左侧的出发点站点,然后获取目标URL如图二

import requests
url="https://touch.dujia.qunar.com/depCities.qunar" strhtml=requests.get(url)
print(strhtml)
dep_dict=strhtml.json()
print(dep_dict)
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
print(dep)
(2)获得目的地。根据上面的分析,json工具解码以后通过拼接可得URL。
url = 'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep))
(3)总源码
import requests
import urllib
import time
#import pymongo # client=pymongo.MongoClient('localhost',27017)
# book_qunar=client['qunar']
# sheet_qunar_zyx=book_qunar['qunar_zyx'] #获取产品列表
def get_list(dep,item):
url = 'https://touch.dujia.qunar.com/list?modules=list,bookingInfo&dep={}&query={}&mtype=all&ddt=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&et=FreetripTouch&date=&configDepNew=&needNoResult=true&originalquery={}&limit=0,20&includeAD=true&qsact=search'.format(
urllib.request.quote(dep), urllib.request.quote(item), urllib.request.quote(item))
strhtml = get_json(url)
try:
routeCount = int(strhtml['data']['limit']['routeCount'])
except:
return
for limit in range(0, routeCount, 20):
url = 'https://touch.dujia.qunar.com/list?modules=list,bookingInfo&dep={}&query={}&mtype=all&ddt=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&et=FreetripTouch&date=&configDepNew=&needNoResult=true&originalquery={}&limit={},20&includeAD=true&qsact=search'.format(
urllib.request.quote(dep), urllib.request.quote(item),
urllib.request.quote(item), limit)
strhtml = get_json(url)
result = {
'date': time.strftime('%Y-%m-%d', time.localtime(time.time())),
'dep': dep,
'arrive': item,
'limit': limit,
'result': strhtml
}
#sheet_qunar_zyx.insert_one(result)
print(result) # def connect_mongo():
# client=pymongo.MongoClient('localhost',27017)
# book_qunar=client['qunar']
# return book_qunar['qunar_zyx'] def get_json(url):
strhtml=requests.get(url)
time.sleep(1)
return strhtml.json() if __name__ == "__main__": url='https://touch.dujia.qunar.com/depCities.qunar'
dep_dict=get_json(url)
#这里是json格式 dep_dict中内嵌勒一层
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
a = []#目的地去重
#经过解码工具可以得到dep表示出发地 query和originalquery表示目的地
url = 'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep))
arrive_dict = get_json(url)
for arr_item in arrive_dict['data']:
for arr_item_1 in arr_item['subModules']:
for query in arr_item_1['items']:
if query['query'] not in a:
a.append(query['query'])
for item in a:
get_list(dep,item)
python爬虫3之去哪儿网的更多相关文章
- 用python爬虫爬取去哪儿4500个热门景点,看看国庆不能去哪儿
前言:本文建议有一定Python基础和前端(html,js)基础的盆友阅读. 金秋九月,丹桂飘香,在这秋高气爽,阳光灿烂的收获季节里,我们送走了一个个暑假余额耗尽哭着走向校园的孩籽们,又即将迎来一年一 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- Python爬虫入门教程 34-100 掘金网全站用户爬虫 scrapy
爬前叨叨 已经编写了33篇爬虫文章了,如果你按着一个个的实现,你的爬虫技术已经入门,从今天开始慢慢的就要写一些有分析价值的数据了,今天我选了一个<掘金网>,我们去爬取一下他的全站用户数据. ...
- Python爬虫入门教程 11-100 行行网电子书多线程爬取
行行网电子书多线程爬取-写在前面 最近想找几本电子书看看,就翻啊翻,然后呢,找到了一个 叫做 周读的网站 ,网站特别好,简单清爽,书籍很多,而且打开都是百度网盘可以直接下载,更新速度也还可以,于是乎, ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- Python爬虫入门教程 20-100 慕课网免费课程抓取
写在前面 美好的一天又开始了,今天咱继续爬取IT在线教育类网站,慕课网,这个平台的数据量并不是很多,所以爬取起来还是比较简单的 准备爬取 打开我们要爬取的页面,寻找分页点和查看是否是异步加载的数据. ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
随机推荐
- Python idle中lxml 解析HTML时中文乱码解决
例: <html><p>中文</p></html> 读取代码: 代码HTML需要进行decode('utf-8') 编译: p=etree.HTML(u ...
- Java——CaptchaUtil生成二维码乱码
前言 这个问题就是因为Linux上没有字体,你可以有两种方法,一个在生成的时候设置字体,一个就是安装字体. 默认的字体为Courier 乱码情况 步骤 安装字体工具 yum install -y fo ...
- css 的弱化与 js 的强化(转)
web 的三要素 html, css, js 在前端组件化的过程中,比如 react.vue 等组件化框架的运用,使 html 的弱化与 js 的强化 成为了一种趋势,而在这个过程中,其实还有另一种趋 ...
- lis框架showoncodename的用法
fm.Sex.value=tContent2[0][3];//这个一定得是查询出来的码值alert("获取到的值是:"+tContent2[0][3]);showOneCodeNa ...
- Centos7安装Spark2.4
准备 1.hadoop已部署(若没有可以参考:Centos7安装Hadoop2.7),集群情况如下(IP地址与之前文章有变动): hostname IP地址 部署规划 node1 172.20.0.2 ...
- .NET体系结构
主要内容包括: C#与.NET的关系.公共语言运行库.中间语言.程序集..NET Framework类.名称空间.内层管理... C#与.NET的关系 C#是门高级编程语言,.NET(Framewor ...
- 使用nginx 正向代理暴露k8s service && pod ip 外部直接访问
有时在我们的实际开发中我们希望直接访问k8s service 暴露的服务,以及pod的ip 解决方法,实际上很多 nodeport ingress port-forword 实际上我们还有一种方法:正 ...
- graphql-query-rewriter 无缝处理graphql 变更
graphql-query-rewriter 是一个graphql schema 变动重写的中间件,可以帮助我们解决在版本变动,查询实体变动 是的问题,从目前已知的技术中我们可选的方案有以下处理变动的 ...
- High scalability with Fanout and Fastly
转自:http://blog.fanout.io/2017/11/15/high-scalability-fanout-fastly/ Fanout Cloud is for high scale d ...
- PostGraphile 4.4 发布,支持real time 查询
在4.4 之前,real time 是通过插件完成处理的,4.4 直接内置了,还是很方便的功能,总算 和其他类似graphql 平台看齐了,使用上还是挺方便的. 参考资料 https://www.gr ...