python 爬取豆瓣的美剧
pc版大概有500条记录,mobile大概是50部,只有热门的,所以少一点
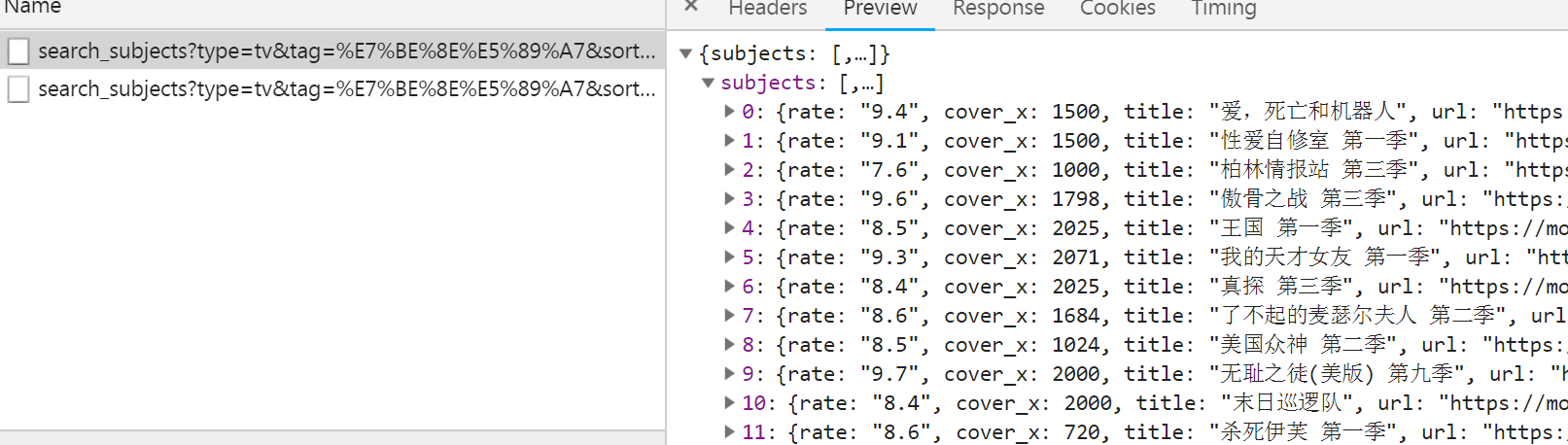

url构造很简单,主要参数就是page_limit与page_start,每翻一页,start+=20即可,tag是"美剧"编码后的结果,直接带着也可以,用unquote解码也可以,注意headers中一定要带上refer
import json
import requests
import math
import os
import shutil
from pprint import pprint
from urllib import parse class DoubanSpliderPC:
def __init__(self):
self.url = parse.unquote(
"https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}") self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Referer": "https://movie.douban.com/tv/"
}
self.file_dir = "./douban_american_pc.txt" def parse_url(self):
number = 0
while True:
url = self.url.format(number)
print(url)
response = requests.get(url, headers=self.headers)
response_dict = json.loads(response.content.decode())
subjects_list = response_dict["subjects"]
with open(self.file_dir, "a", encoding="utf-8") as file:
for subject in subjects_list:
file.write(json.dumps(subject, ensure_ascii=False))
file.write("\r\n")
if len(subjects_list) < 20:
break
number += 20 def run(self):
# 删除之前保存的数据
if os.path.exists(self.file_dir):
os.remove(self.file_dir)
print("文件已清空")
self.parse_url() def main():
splider = DoubanSpliderPC()
splider.run() if __name__ == '__main__':
main()
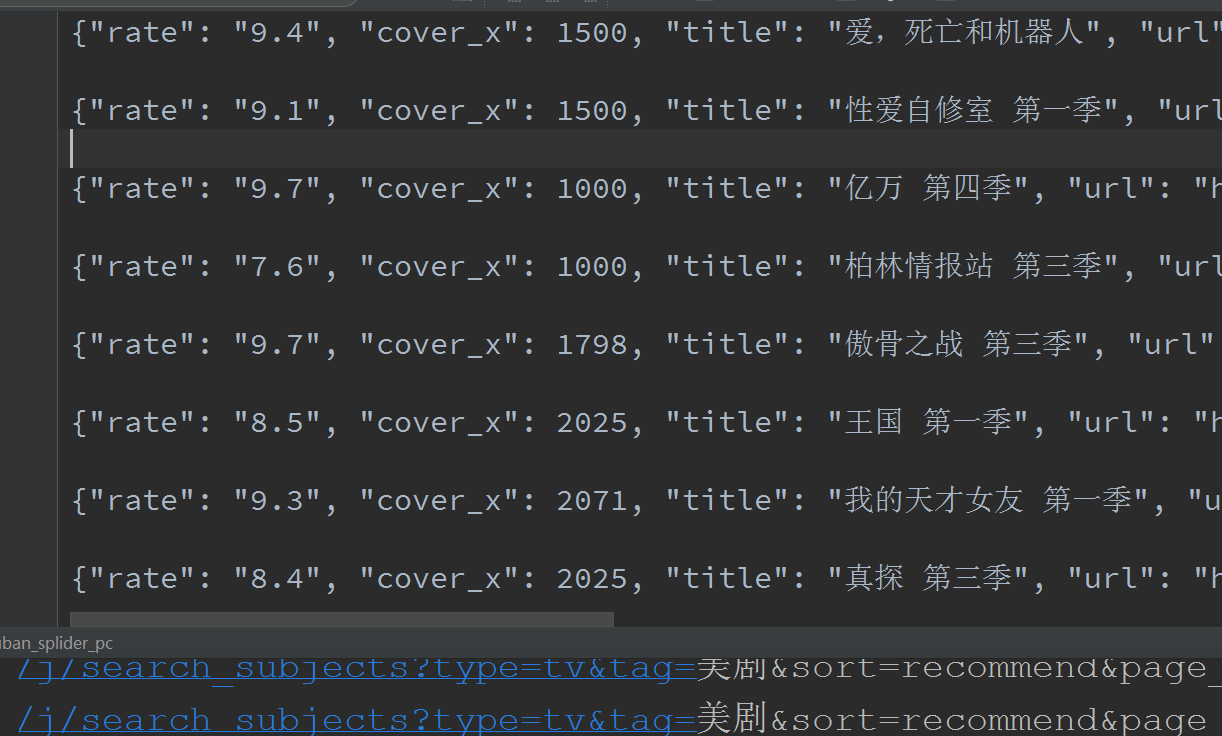
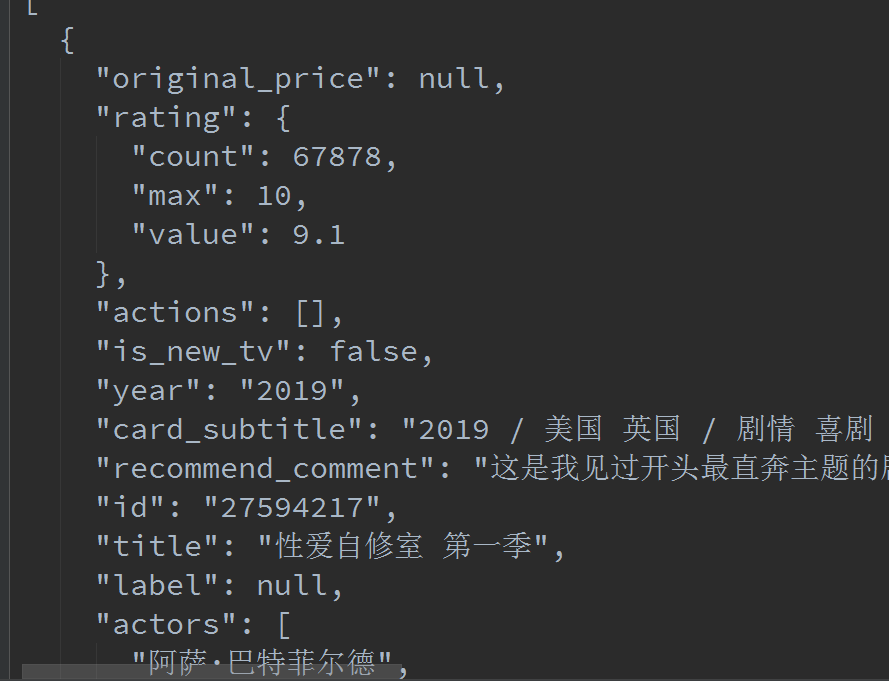
moblie类似,不过抓包的时候找那个Item就可以了
import json
import requests
import math
import os
import shutil
from pprint import pprint # 爬取豆瓣的美剧页面(手机版只有50条)
class DouBanSpliderMobile:
pageCount = 18
total = None def __init__(self):
self.first_url = "https://m.douban.com/rexxar/api/v2/subject_collection/tv_american/items?os=ios&for_mobile=1&start={}&count=18&loc_id=108288&_=1552995446961"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Referer": "https://m.douban.com/tv/american"
}
self.file_dir = "./douban_american_mobile.txt" def get_url_list(self):
url_list = []
for i in range(math.ceil(DouBanSpliderMobile.total / DouBanSpliderMobile.pageCount)):
url = self.first_url.format(i * 18)
url_list.append(url)
return url_list def parse_url(self, url):
response = requests.get(url, headers=self.headers)
response_dict = json.loads(response.content.decode())
DouBanSpliderMobile.total = int(response_dict["total"])
with open(self.file_dir, "a", encoding="utf-8") as file:
json.dump(response_dict["subject_collection_items"], file, ensure_ascii=False, indent=2) def run(self):
# 解析第一个url,获取total
self.parse_url(self.first_url.format(0))
url_list = self.get_url_list() # 删除之前保存的文件
if os.path.exists(self.file_dir):
os.remove(self.file_dir) for url in url_list:
self.parse_url(url) def main():
douban_splider = DouBanSpliderMobile()
douban_splider.run() if __name__ == '__main__':
main()
python 爬取豆瓣的美剧的更多相关文章
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- python爬取豆瓣小组700+话题加回复啦啦啦python open file with a variable name
需求:爬取豆瓣小组所有话题(话题title,内容,作者,发布时间),及回复(最佳回复,普通回复,回复_回复,翻页回复,0回复) 解决:1. 先爬取小组下,所有的主题链接,通过定位nextpage翻页获 ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
随机推荐
- Eclipse导出Library
在工作中遇到开发SDK,记录下导出Library的过程. 1.导出 选中项目>属性>Android 配置Is library例如以下图: 选中项目>导出>JAR ...
- C Tricks(十九)—— 求以任意数为底的对数
本文仅求对数的整数部分: int log(int n, int base){ int i = 1, cnt = 0; while (i*base < n){ i *= base; ++cnt; ...
- (转) 25个必须记住的SSH命令
转自:http://www.cnblogs.com/weafer/archive/2011/06/10/2077852.html OpenSSH是SSH连接工具的免费版本.telnet,rlogin和 ...
- 在 Windows 10 x64 上安装及使用 ab 工具的流程
本文转自:www.shuijingwanwq.com/2017/04/18/1568/ 1.基于AB测试工具进行高并发情形下的模拟测试,打开:http://httpd.apache.org/docs/ ...
- jqgrid 实现行编辑,表单编辑的列联动
这个问题的场景相信大家都遇到过,比方有A,B,C三列,B,C列均为下拉框.可是C列的值是由B列的值来决定的.即C列中的值是动态变化的,变化的根据就是B列中你选择的值. 本文给出的是一个有用,简易快捷的 ...
- Windows下安装Resin及配置具体解释与公布应用
关于Resin的优点,网上介绍了一大堆.小编经不住诱惑,决定试用一下. 眼下Resin的最新版本号为:4.0.40.能够从官网直接下载. 1. 将下载下来的Resin包解压开,会看到一 ...
- eclipse config 2 tab -> space
编码规范要求不同意使用tab,可是又要有4个字符的缩进,连点4次space,这不是程序猿的风格 来看看 eclipse 设置一次tab像space的转换 例如以下操作 Window->Prefe ...
- AOP技术应用和研究--OOP
1,软件编程技术的发展 软件编程技术与程序设计语言是分不开的.过去的几十年中,程序设计语言对抽象机制的支持程度不断提高:从机器语言到汇编语言,到高级语言,再到面向对象语言.每一种新的程序设计语言的出现 ...
- thinkphp5项目--企业单车网站(九)(加强复习啊)(花了那么多时间写的博客,不复习太浪费了)
thinkphp5项目--企业单车网站(九)(加强复习啊)(花了那么多时间写的博客,不复习太浪费了) 项目地址 fry404006308/BicycleEnterpriseWebsite: Bicyc ...
- ERROR:column "rolcatupdate" does not exist
1.错误描写叙述 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/ ...