python下载网页转化成pdf
最近在学习一个网站补充一下cg基础。但是前几天网站突然访问不了了,同学推荐了waybackmachine这个网站,它定期的对网络上的页面进行缓存,但是好多图片刷不出来,很憋屈。于是网站恢复访问后决定把网页爬下来存成pdf。
两点收获:
1.下载网页时图片、css等文件也下载下来,并且修改html中的路径。
2. beautifulsoup、wkhtmltopdf很强大,用起来很舒心
前期准备工作:
0.安装python
1.安装pip
下载pip的安装包get-pip.py,下载地址:https://pip.pypa.io/en/latest/installing.html#id7
然后在get-pip.py所在的目录下运行get-pip.py
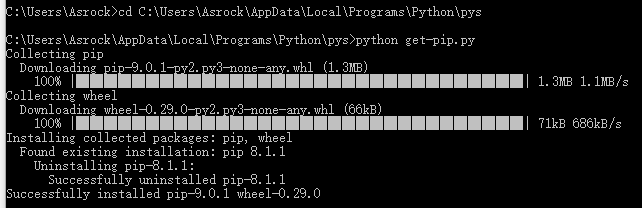
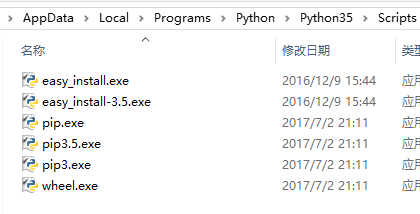
执行完成后,在python的安装目录下的Scripts子目录下,可以看到pip.exe
升级的话用 python -m pip install -U pip
2. 安装wkhtmltopdf : 适用于多平台的 html 到 pdf 的转换工具
3. install requests、beautifulsoup、pdfkit.
pdfkit 是 wkhtmltopdf 的Python封装包
beautifulsoup用于操纵html内容。
2.代码实现
from _ssl import PROTOCOL_TLSv1
from functools import wraps
import os
from ssl import SSLContext
import ssl
from test.test_tools import basepath
import urllib
from urllib.parse import urlparse # py3 from bs4 import BeautifulSoup
import requests
import urllib3 def sslwrap(func):
@wraps(func)
def bar(*args, **kw):
kw['ssl_version'] = ssl.PROTOCOL_TLSv1
return func(*args, **kw)
return bar def save(url,cls,outputDir,outputFile):
print("saving " + url);
response = urllib.request.urlopen(url,timeout=500)
soup = BeautifulSoup(response,"html5lib")
#set css
#save imgs #save html
if(os.path.exists(outputDir+outputFile)):
os.remove(outputDir+outputFile);
if(cls!=""):
body = soup.find_all(class_=cls)[0]
with open(outputDir+outputFile,'wb') as f:
f.write(str(body).encode(encoding='utf_8'))
else:
with open(outputDir+outputFile,'wb') as f:
f.write(str(soup.find_all("html")).encode(encoding='utf_8'))
print("finish!");
return soup; def crawl(base,outDir):
ssl._create_default_https_context = ssl._create_unverified_context
heads = save(base+"/index.php?redirect","central-column",outDir,"/head.html");
for link in heads.find_all('a'):
pos = str(link.get('href'))
if(pos.startswith('/lessons')==True):
curDir = outDir+pos;
if(os.path.exists(curDir)==False):
makedirs(curDir)
else:
print("already exist " + curDir);
continue
counter = 1;
while(True):
body = save(base+pos,"",curDir,"/"+str(counter)+".html")
counter+=1;
hasNext = False;
for div in body.find_all("div",class_="footer-prev-next-cell"):
if(div.get("style")=="text-align: right;"):
hrefs = div.find_all("a");
if(len(hrefs)>0):
hasNext = True;
pos = hrefs[0]['href'];
print(">>next is at:"+pos)
break;
if(hasNext==False):
break; if __name__ == '__main__':
crawl("https://www.***.com", "E:/Documents/CG/***");
print("finish")
python下载网页转化成pdf的更多相关文章
- Python下载网页的几种方法
get和post方式总结 get方式:以URL字串本身传递数据参数,在服务器端可以从'QUERY_STRING'这个变量中直接读取,效率较高,但缺乏安全性,也无法来处理复杂的数据(只能是字符串,比如在 ...
- 下载网页中的 pdf 各种姿势,教你如何 carry 各种网页上的 pdf 文档。
关联词: PDF 下载 FLASH 网页 HTML 报告 内嵌 浏览器 文档 FlexPaperViewer swfobject. 这个需求是最近帮一个妹子处理一下各大高校网站里的 PDF 文档下载, ...
- python下载网页上公开数据集
URL很简单,数据集分散开在一个URL页面上,单个用手下载很慢,这样可以用python辅助下载: 问题:很多国外的数据集,收到网络波动的影响很大,最好可以添加一个如果失败就继续请求的逻辑,这里还没有实 ...
- python下载网页视频
因网站不同需要修改. 下载 mp4 连接 from bs4 import BeautifulSoup import requests import urllib import re import js ...
- python下载网页源码 写入文本
import urllib.request,io,os,sysreq=urllib.request.Request("http://echophp.sinaapp.com/uncategor ...
- Python下载网页图片
有时候不如不想输入路径,那就需要用os模块来修改当前路径 下面是从其他地方看到的一个例子,就是把图片url中的图片名字修改,然后就可以循环保存了,不过也是先确定了某个url 来源:http://www ...
- 使用python把html网页转成pdf文件
我们看到一些比较写的比较好文章或者博客的时候,想保存下来到本地当一个pdf文件,当做自己的知识储备,以后即使这个博客或者文章的连接不存在了,或者被删掉,咱们自己也还有. 当然咱们作为一个coder,这 ...
- Python入门小练习 002 批量下载网页链接中的图片
我们常常需要下载网页上很多喜欢的图片,但是面对几十甚至上百张的图片,一个一个去另存为肯定是个很差的体验. 我们可以用urllib包获取html的源码,再以正则表达式把匹配的图片链接放入一个list中, ...
- Python + Selenium +Chrome 批量下载网页代码修改【新手必学】
Python + Selenium +Chrome 批量下载网页代码修改主要修改以下代码可以调用 本地的 user-agent.txt 和 cookie.txt来达到在登陆状态下 批量打开并下载网页, ...
随机推荐
- Struts2简单环境搭建
一.开篇 Struts2是一个运行于web容器的表示层框架,其核心作用是帮助我们处理Http请求.Struts2处理Http请求(Request),并进行内部处理,再进行Http返回. 下载strut ...
- 原生javascript实现文件异步上传
效果图: 代码:(demo33.jsp) <%@ page contentType="text/html;charset=UTF-8" language="java ...
- for循环的写法及优化
最近这几天在研究浏览器性能的时候发现了一些小知识,在此做一总结: 其中经常用到的for循环有:正常的for循环,for in循环,for of循环等,但是对于正常的for循环可以做一下优化,使得其在执 ...
- iOS 11 APP 设计中的几个 UI 设计细节
Apple 官网看了 iOS 11 的介绍,发现有不少的更新哦,比如控制中心.Siri.Live Photo 等等,总体来说都有很多不错的体验,不过本文不介绍功能,只说视觉界面. 在 iOS 11 的 ...
- ddk安装失败后的处理
7600.16385.1版本的DDK,在xp的本上死活按不上,怎么办呢?自己就把其他机器上安装的DDK目录,拷贝过来. 怎么建编译环境呢? 查看x86 Checked Build Environmen ...
- dfs___刷题记录
poj 1564 给出一个s,n个数,输出所有的能够得到s的方案 #include<cstdio> #include<cstring> #include<iostream ...
- 苹果操作系统名称演变史 新名称macOS
历史回顾 发布年代 名称 序号 1994-1999 Classic Mac OS 1-9 2001-2011 Mac OS X 10.0-Lion 2012-2015 OS X Mountain Li ...
- ZBrush软件特性之Color调控板
ZBrush®中的Color调色板显示当前颜色并提供数值的方法选择颜色,而且选择辅助色,使用描绘工具可以产生混合的色彩效果. ZBrush 4R8下载:http://wm.makeding.com/i ...
- CF894E Ralph and Mushrooms_强连通分量_记忆化搜索_缩点
Code: #include<cstdio> #include<stack> #include<cstring> using namespace std; cons ...
- 《Exception》第八次团队作业:Alpha冲刺(第二天)
一.项目基本介绍 项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 Exception 作业学习目标 1.掌握软件测试基础技术.2.学习迭代式增量软 ...