基于Redis的三种分布式爬虫策略
前言:
爬虫是偏IO型的任务,分布式爬虫的实现难度比分布式计算和分布式存储简单得多。
个人以为分布式爬虫需要考虑的点主要有以下几个:
- 爬虫任务的统一调度
- 爬虫任务的统一去重
- 存储问题
- 速度问题
- 足够“健壮”的情况下实现起来越简单/方便越好
- 最好支持“断点续爬”功能
Python分布式爬虫比较常用的应该是scrapy框架加上Redis内存数据库,中间的调度任务等用scrapy-redis模块实现。
此处简单介绍一下基于Redis的三种分布式策略,其实它们之间还是很相似的,只是为适应不同的网络或爬虫环境作了一些调整而已(如有错误欢迎留言拍砖)。
【策略一】
Slaver端从Master端拿任务(Request/url/ID)进行数据抓取,在抓取数据的同时也生成新任务,并将任务抛给Master。Master端只有一个Redis数据库,负责对Slaver提交的任务进行去重、加入待爬队列。
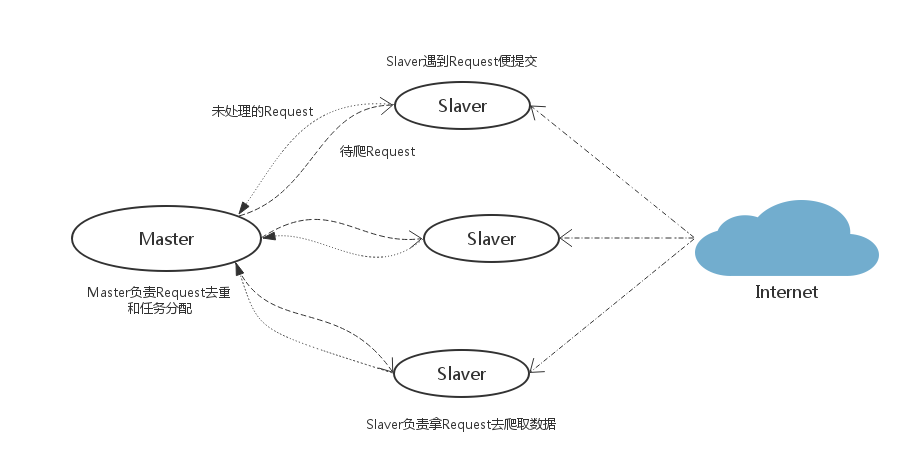
优点: scrapy-redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作scrapy-redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点: scrapy-redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间。当然我们可以重写方法实现调度url或者用户ID。
【策略二】
这是对策略的一种优化改进:在Master端跑一个程序去生成任务(Request/url/ID)。Master端负责的是生产任务,并把任务去重、加入到待爬队列。Slaver只管从Master端拿任务去爬。
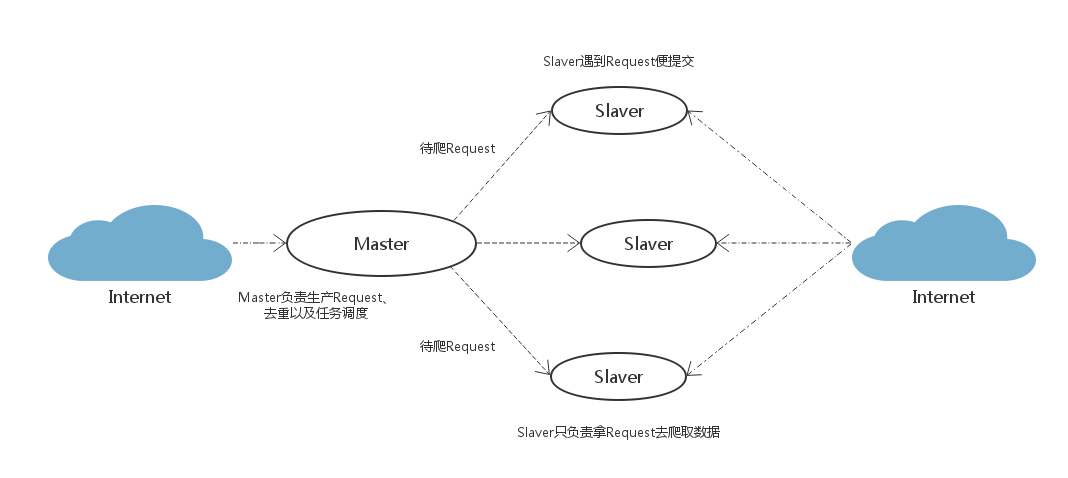
优点: 将生成任务和抓取数据分开,分工明确,减少了Master和Slaver之间的数据交流;Master端生成任务还有一个好处就是:可以很方便地重写判重策略(当数据量大时优化判重的性能和速度还是很重要的)。
缺点: 像QQ或者新浪微博这种网站,发送一个请求,返回的内容里面可能包含几十个待爬的用户ID,即几十个新爬虫任务。但有些网站一个请求只能得到一两个新任务,并且返回的内容里也包含爬虫要抓取的目标信息,如果将生成任务和抓取任务分开反而会降低爬虫抓取效率。毕竟带宽也是爬虫的一个瓶颈问题,我们要秉着发送尽量少的请求为原则,同时也是为了减轻网站服务器的压力,要做一只有道德的Crawler。所以,视情况而定。
【策略三】
Master中只有一个集合,它只有查询的作用。Slaver在遇到新任务时询问Master此任务是否已爬,如果未爬则加入Slaver自己的待爬队列中,Master把此任务记为已爬。它和策略一比较像,但明显比策略一简单。策略一的简单是因为有scrapy-redis实现了scheduler中间件,它并不适用于非scrapy框架的爬虫。
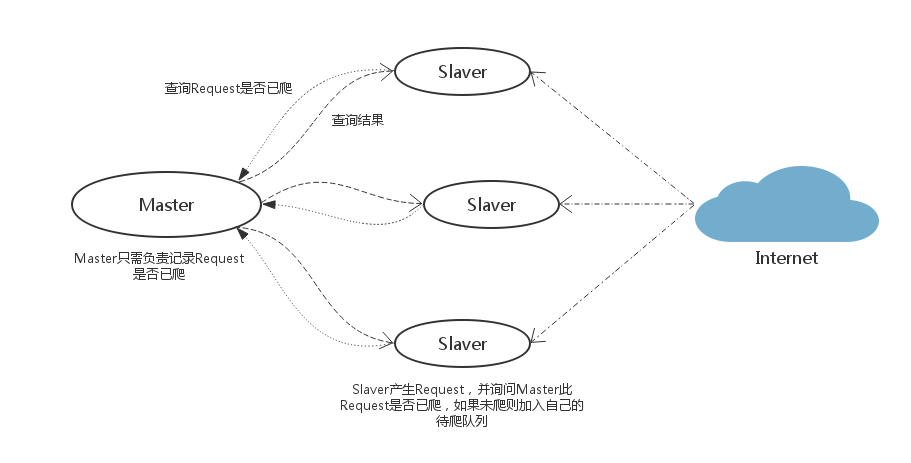
优点: 实现简单,非scrapy框架的爬虫也适用。Master端压力比较小,Master与Slaver的数据交流也不大。
缺点: “健壮性”不够,需要另外定时保存待爬队列以实现“断点续爬”功能。各Slaver的待爬任务不通用。
结语:
如果把Slaver比作工人,把Master比作工头。策略一就是工人遇到新任务都上报给工头,需要干活的时候就去工头那里领任务;策略二就是工头去找新任务,工人只管从工头那里领任务干活;策略三就是工人遇到新任务时询问工头此任务是否有人做了,没有的话工人就将此任务加到自己的“行程表”。
基于Redis的三种分布式爬虫策略的更多相关文章
- 基于ZooKeeper的三种分布式锁实现
[欢迎关注公众号:程序猿讲故事 (codestory),及时接收最新文章] 今天介绍基于ZooKeeper的分布式锁的简单实现,包括阻塞锁和非阻塞锁.同时增加了网上很少介绍的基于节点的非阻塞锁实现,主 ...
- 一文掌握Redis的三种集群方案
在开发测试环境中,我们一般搭建Redis的单实例来应对开发测试需求,但是在生产环境,如果对可用性.可靠性要求较高,则需要引入Redis的集群方案.虽然现在各大云平台有提供缓存服务可以直接使用,但了解一 ...
- Apache Spark探秘:三种分布式部署方式比较
转自:链接地址: http://dongxicheng.org/framework-on-yarn/apache-spark-comparing-three-deploying-ways/ 目 ...
- ASP.NET MVC:多语言的三种技术处理策略
ASP.NET MVC:多语言的三种技术处理策略 背景 本文介绍了多语言的三种技术处理策略,每种策略对应一种场景,这三种场景是: 多语言资源信息只被.NET使用. 多语言资源信息只被Javascrip ...
- redis 提供 6种数据淘汰策略
淘汰策略的原因 在 redis 中,允许用户设置最大使用内存大小 server.maxmemory,在内存限定的情况下是很有用的.譬如,在一台 8G 机子上部署了 4 个 redis 服务点,每一个服 ...
- 【连载】redis库存操作,分布式锁的四种实现方式[三]--基于Redis watch机制实现分布式锁
一.redis的事务介绍 1. Redis保证一个事务中的所有命令要么都执行,要么都不执行.如果在发送EXEC命令前客户端断线了,则Redis会清空事务队列,事务中的所有命令都不会执行.而一旦客户端发 ...
- 三种分布式锁 简易说说(包含前一篇提到的redis分布式锁)
大多数互联网系统都是分布式部署的,分布式部署确实能带来性能和效率上的提升,但为此,我们就需要多解决一个分布式环境下,数据一致性的问题. 当某个资源在多系统之间,具有共享性的时候,为了保证大家访问这个资 ...
- 基于 Redis 实现简单的分布式锁
摘要 分布式锁在很多应用场景下是非常有效的手段,比如当运行在多个机器上的不同进程需要访问同一个竞争资源的时候,那么就会涉及到进程对资源的加锁和释放,这样才能保证数据的安全访问.分布式锁实现的方案有很多 ...
- 基于Redis实现简单的分布式锁【理论】
摘要 分布式锁在很多应用场景下是非常有效的手段,比如当运行在多个机器上的不同进程需要访问同一个竞争资源的时候,那么就会涉及到进程对资源的加锁和释放,这样才能保证数据的安全访问.分布式锁实现的方案有很多 ...
随机推荐
- HDU3853:LOOPS(概率DP)
传送门 题意 从(i,j)走到(i,j),(i,j+1),(i+1,j)的概率为p[i][j][1],p[i][j][2],p[i][j][3],花费2魔力,问从(1,1)走到(r,c)的期望 分析 ...
- bzoj 2326: [HNOI2011]数学作业【dp+矩阵快速幂】
矩阵乘法一般不满足交换律!!所以快速幂里需要注意乘的顺序!! 其实不难,设f[i]为i的答案,那么f[i]=(f[i-1]w[i]+i)%mod,w[i]是1e(i的位数),这个很容易写成矩阵的形式, ...
- bzoj 2245 [SDOI2011]工作安排【最小费用最大流】
其实不用拆点,对于每个人我们假装他是\( s[i]+1 \)个点,可以由他向T点分别连\( s[i]+1 \)条边,容量为\( t[i][j]-t[i][j-1]\),由S点向所有产品i连容量为c[i ...
- apicloud踩坑集锦
最近在用apicloud开发,这里录入一些踩坑的地方,从头到尾,要多尴尬有多尴尬,新入app开发,记录一些心得,和遇到的坑以及解决办法. 1,apicloud 打包的Android app ,打开fr ...
- Scala入门到精通
原文出自于: http://my.csdn.net/lovehuangjiaju 感谢! 也感谢,http://m.blog.csdn.net/article/details?id=52233484 ...
- STL之map基础知识
Map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候 ...
- ACM_折线中点
折线中点 Time Limit: 2000/1000ms (Java/Others) Problem Description: 给定平面上N个点P1, P2, ... PN,将他们按顺序连起来,形成一 ...
- 在面试官问你BS和CS区别的时候如何回答??
这是我下来整理好的,如果哪里不全,望大家多多指教 C/S是Client/Server的缩写.服务器通常采用高性能的PC.工作站或小型机,并采用大型数据库系统,如Oracle.Sybase.Inform ...
- ABP教程(一)- ABP介绍
ABP是什么 ABP是”ASP.NET Boilerplate Project (ASP.NET样板项目)”的简称. ASP.NET Boilerplate是一个用最佳实践和流行技术开发现代WEB应用 ...
- SpringBoot之旅第七篇-Docker
一.引言 记得上大三时,要给微机房电脑安装系统,除了原生的操作系统外,还要另外安装一些必要的开发软件,如果每台电脑都重新去安装的话工作量就很大了,这个时候就使用了windows镜像系统,我们将要安装的 ...