MR execution in YARN
Overview
YARN provides API not for application developers but for the great developers working on new computing engines. YARN make it easy and unified for resource management for the computing engines. It fills the gap between mputation and storage. NoSQL database like HBase use slider apdaters to YARN.
With YARN 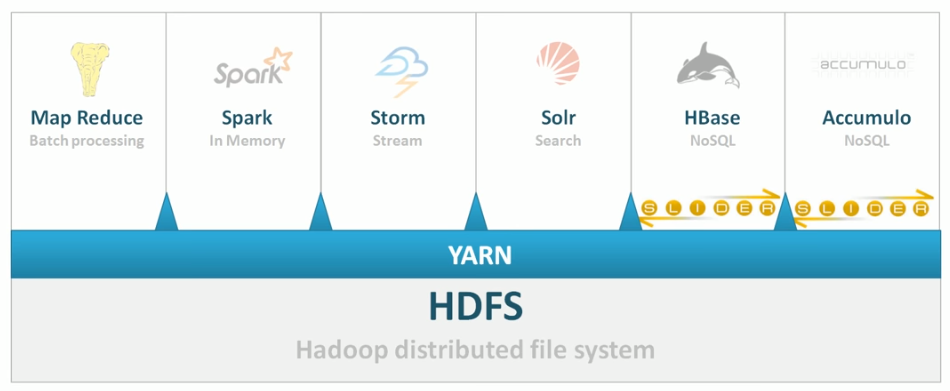
Withou YARN

Entities in YARN
The base of Distribution is HDFS and YARN. HDFS for managing storage. YARN for managing computing.
Client: who submits the job: connects to MR or HDFS framework.
YARN Resource Manager: allocate computing resource required by the job.
Scheduleer:job scheduling,locate the resources.
Application Manager:performan any monitoring or tracking of application/job status.
YARN Node Manager: on all slave nodes. launch / manager containers.
MR Application Master:carry out execution of the job associated with it. different between computing engines. It coordinates the tasks running and monitors the progress and aggregates it and since reports to its client . It is spawn under node manager on the instruction by RM. spawn for every job and end with the job done.
YARN Child: manages the run of the map and reduce tasks,send updates / progress to application master.
HDFS:i/o
The process of job run in YARN
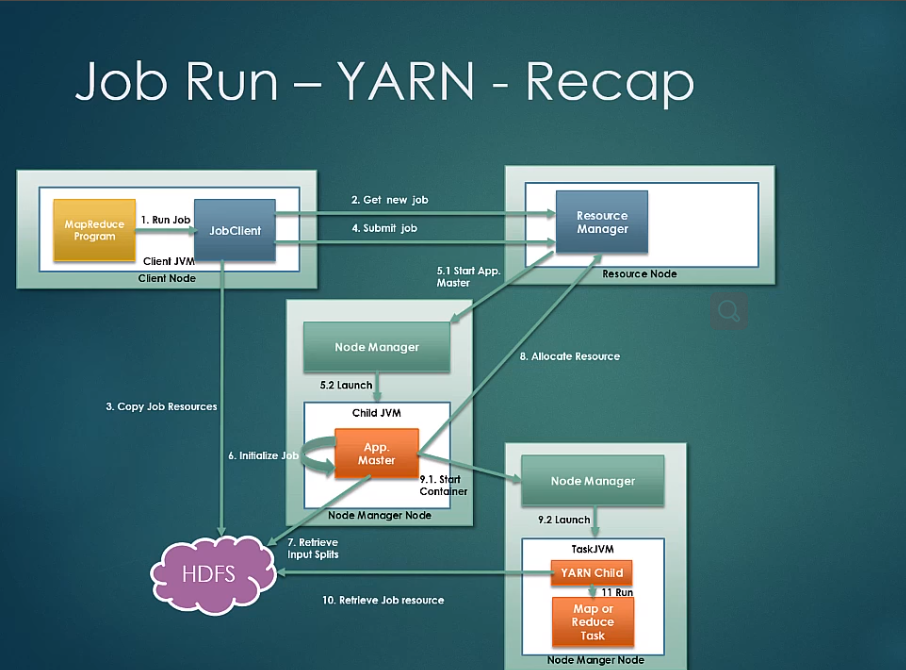
Job submission:Your program triggers the job client and the job client contacts the RM for the new job id. copy the job resource to HDFS with high replica and then submit the job.
Job Initialization: Then RM (the scheduler)picks up the job from the job queue(FIFO,capacity,fair) and contacts NM,sponsor new container (Linux kernel feature, a abstruct of resource like cpu,mem,disk,network bandwidth. doker uses it too) and launches AM for the job.
Job Assigement: AM creates new objects , it retrives the input splits from HDFS and crete one task per input split. AM then decides if the job is samll or not. If it is small job , run its jvm on a single node. If not,contacts RM locate computing resources.
Job Execution:RM considers data locality while assigning the resources(Scheduler at this time knows where the splits are located.It gathers this info from the heartbeats of NM. Based on it, it consider data locality when allocating resources. try as best, then consider the rack local nodes ,if still fails, it will pick random from available noedes).AM then communicates node managers which launches the yarn child(a java program the main class is YarnChild,seperate JVM from long running system demons from the suer code). yarn child retrieves the code and other resource from HDFS and then run the tasks(mr).Yan child sends the progress to AM(every 3 seconds) which aggregrates(each yarn client's information) the report and sends the report to the client.
Job Exmpletion:On job completion , yarn child and AM terminates themseves for the next job.
MR execution in YARN的更多相关文章
- Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(一)
我们知道,如果想要在Yarn上运行MapReduce作业,仅需实现一个ApplicationMaster组件即可,而MRAppMaster正是MapReduce在Yarn上ApplicationMas ...
- hadoop多机安装HA+YARN
HA 相比于Hadoop1.0,Hadoop 2.0中的HDFS增加了两个重大特性,HA(热备)和Federation(联邦).HA即为High Availability,用于解决NameNode单点 ...
- hadoop多机安装YARN
hadoop伪分布安装称为测试环境安装,多机分布称为生成环境安装.以下安装没有进行HA(热备)和Federation(联邦).除非是性能需要,否则没必要安装Federation,HA可以一试,涉及到Z ...
- Hadoop2.4.1 64-Bit QJM HA and YARN HA + Zookeeper-3.4.6 + Hbase-0.98.8-hadoop2-bin HA Install
Hadoop2.4.1 64-Bit QJM HA and YARN HA Install + Zookeeper-3.4.6 + Hbase-0.98.8-hadoop2-bin HA(Hadoop ...
- Hadoop 5、HDFS HA 和 YARN
Hadoop 2.0 产生的背景Hadoop 1.0 中HDFS和MapReduce存在高可用和扩展方面的问题 HDFS存在的问题 NameNode单点故障,难以用于在线场景 NameNode压力过大 ...
- YARN的基础配置
基于HADOOP3.0+Centos7.0的yarn基础配置: 执行步骤:(1)配置集群yarn (2)启动.测试集群(3)在yarn上执行wordcount案例 一.配置yarn集群 1.配置yar ...
- YARN的三种调度器的使用
YRAN提供了三种调度策略 一.FIFO-先进先出调度器 YRAN默认情况下使用的是该调度器,即所有的应用程序都是按照提交的顺序来执行的,这些应用程序都放在一个队列中,只有在前面的一个任务执行完成之后 ...
- Hadoop YARN上运行MapReduce程序
(1)配置集群 (a)配置hadoop-2.7.2/etc/hadoop/yarn-env.sh 配置一下JAVA_HOME export JAVA_HOME=/home/hadoop/bigdata ...
- hadoop3.1集成yarn ha
1.角色分配
随机推荐
- Knowledge Point 20180305 十进制转换成二进制浮点数
如何将十进制的浮点数 转换二进制的浮点数,分为两部分: 1. 先将整数部分转换为二进制, 2. 将小数部分转换为二进制, 然后将整数部分与小数部分相加. 以 20.5 转换为例,20转换后变为1010 ...
- iOS 自定义任意形状加载进度条(水波纹进度条)
1. 项目中要做类似下面的加载动画: 先给出安卓的实现方式 2.iOS的实现方式参考了下面两位的,感谢. 以任意底部图片为背景的加载动画 和 水波纹动画 最后附上自己的demo
- 20181029noip模拟赛T1
1.借书 [问题描述] Dilhao一共有n本教科书,每本教科书都有一个难度值,他每次出题的时候都会从其中挑两本教科书作为借鉴,如果这两本书的难度相差越大,Dilhao出的题就会越复杂,也就是说,一道 ...
- 复习宝典之SpringMVC
查看更多宝典,请点击<金三银四,你的专属面试宝典> 第七章:SpringMVC MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(co ...
- 如何利用Linux去油管下载带字幕的优质英文资料提升英文听力和词汇量
非常方便地从油管下载你需要的任何英文视频资料,并且带字幕,方便你学习某个特定领域的词汇: [step1,Centos6系统安装youtbe-dl下载带英文字幕的视频] 1.首先需要安装youtube- ...
- [异常笔记] zookeeper集群启动异常: Cannot open channel to 2 at election address ……
- ::, [myid:] - WARN [WorkerSender[myid=]:QuorumCnxManager@] - Cannot open channel to at election ad ...
- 替代Xshell的良心国产软件 FinalShell
今年8月份NetSarang公司旗下软件家族的官方版本被爆被植入后门着实让我们常用的Xshell,Xftp等工具火了一把,很长时间都是在用Xshell,不过最近发现了一款同类产品FinalShell, ...
- 05JavaScript语句
1.JavaScript 语句 JavaScript 语句是发给浏览器的命令. 这些命令的作用是告诉浏览器要做的事情. 2.分号 ; 分号用于分隔 JavaScript 语句. 通常我们在每条可执行的 ...
- ruby语言里的self理解
关键的一句话:关键看谁调用self,self就属于谁 有3种情况: 1.在class或module的定义中,self代表这个class或者这个module对象,代码如下: class S puts ' ...
- 从Github开源项目《云阅》所学到的知识
感谢开源,感谢大神,才让我们这些菜鸟成长! 附上云阅开源项目地址:点我吧. 1.轮播图的实现. 现在的APP基本都会实现这个功能吧,然后一直都找不到好的第三方库,能够满足各种需求.然而碰到了这个开源库 ...