【hadoop】细读MapReduce的工作原理
前言:中秋节有事外加休息了一天,今天晚上重新拾起Hadoop,但感觉自己有点烦躁,不知后续怎么选择学习Hadoop的方法。
干脆打开电脑,决定:
1、先将Hadoop的MapReduce和Yarn基本原理打扎实了再说,网上说的边画图边记得效果好点;
2、有时间就多看看Java和Python的基础知识,牢固牢固;
3、开始学习hive以及spark
正文:
MapReduce如何分而治之?
Map阶段:
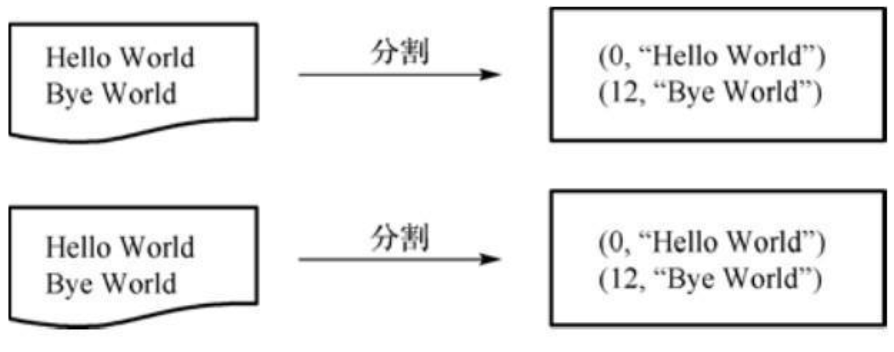
a.拆分输入数据(Split):逐行读取数据,得到一系列(key/value)
注:Split个数根据文件多少来分配,key值包括回车符
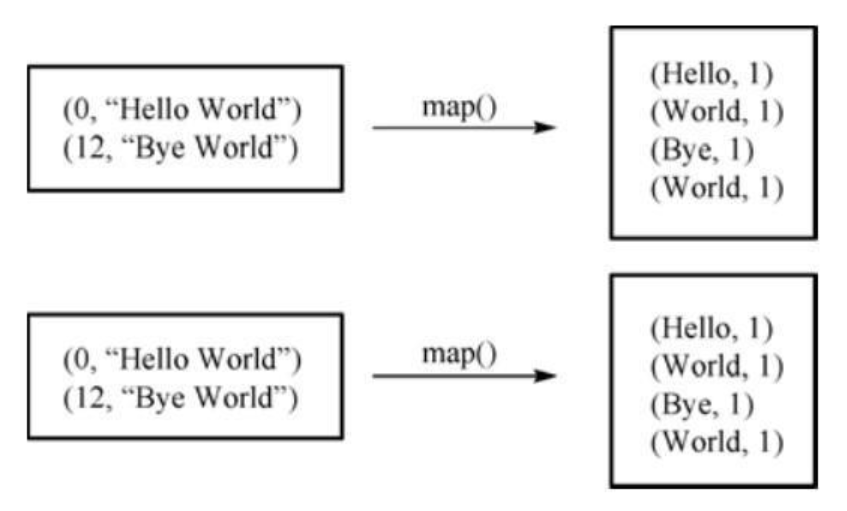
b.执行用户自定义的Map方法
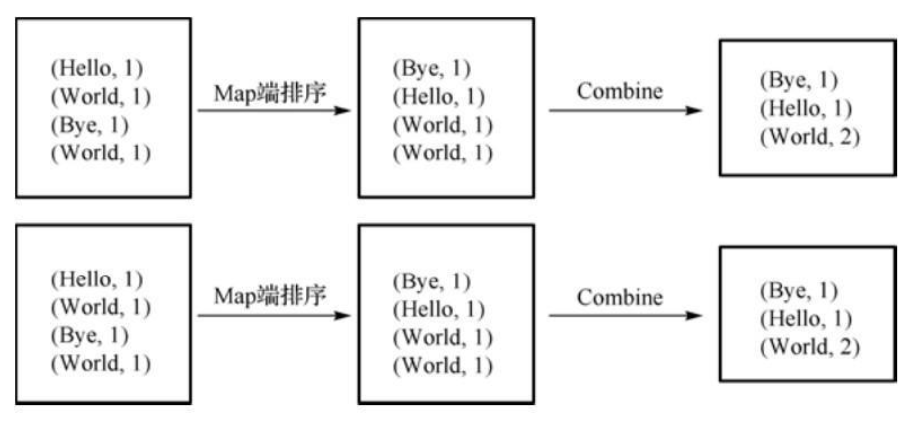
c.Mapper按输出的key值对输出的(key,value)进行排序,并执行combine过程,将key值相同的value累加
注1:combine不能取代reduce,但combine可以减少map和reduce之间数据传输量
注2:在map和cobine之间还有两个过程:collect和spill
collect:是map方法处理完数据后,一般调用OutputCollector。collect()收集结果,并在该内部形成(key/value)分片,并写入一个环形缓冲区
spill:当环形缓冲区填满后,MapReduce会将数据写入本地磁盘,生成临时文件
Reduce阶段:
对Map阶段输出的值进行自定义的reduce函数处理,并输出新的(key/value),并作为结果输出。
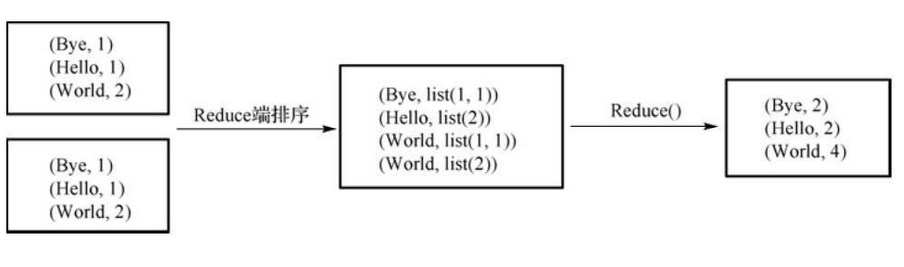
Reduce阶段分5个步骤:shuffle(复制)——merge(合并)——sort(排序)——reduce(执行函数)——write(写入结果)
【hadoop】细读MapReduce的工作原理的更多相关文章
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zoo ...
- 一图看懂hadoop Spark On Yarn工作原理
hadoop Spark On Yarn工作原理
- hadoop之hdfs及其工作原理
hadoop之hdfs及其工作原理 (一)hdfs产生的背景 随着数据量的不断增大和增长速度的不断加快,一台机器上已经容纳不下,因此就需要放到更多的机器中,但这样做不方便维护和管理,因此需要一种文件系 ...
- MapReduce的工作原理
MapReduce简介 MapReduce是一种并行可扩展计算模型,并且有较好的容错性,主要解决海量离线数据的批处理.实现下面目标 ★ 易于编程 ★ 良好的扩展性 ★ 高容错性 MapReduce ...
- MapReduce 1工作原理图文详解
MapReduce工作原理图文详解 一 MapReduce程序执行流程 程序执行流程图如下: 流程分析:1.在客户端启动一个作业.2.向JobTracker请求一个Job ID.3.将运行作业所需要的 ...
- MapReduce工作原理图文详解
目录:1.MapReduce作业运行流程2.Map.Reduce任务中Shuffle和排序的过程 1.MapReduce作业运行流程 流程示意图: 流程分析: 1.在客户端启动一个作业. 2.向Job ...
随机推荐
- MySQL学习笔记——MySQL5.7的启动过程(一)
MySQL的启动函数在 sql/main.cc 文件中. main.cc: extern int mysqld_main(int argc, char **argv); int main(int ar ...
- 第三章 授权——《跟我学Shiro》
转发地址:https://www.iteye.com/blog/jinnianshilongnian-2020017 目录贴:跟我学Shiro目录贴 授权,也叫访问控制,即在应用中控制谁能访问哪些资源 ...
- redis key 空闲(一)
语法: redis 127.0.0.1:6379> COMMAND KEY_NAME 实例: redis 127.0.0.1:6379[1]> select 2 OK redis 127. ...
- 最新 开创java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.开创等10家互联网公司的校招Offer,因为某些自身原因最终选择了开创.6.7月主要是做系统复习.项目复盘.LeetCode ...
- 20191011-构建我们公司自己的自动化接口测试框架-testrun最重要的模块
testrun模块呢就是最终自动化测试入口,调用前面封装的各个模块主要流程是: 1. 获取测试集种待执行的测试用例 2. 处理测试用例获取的数据,包括转换数据格式,处理数据的中的关联等 3. 处理完数 ...
- Django Simple Captcha的使用
Django Simple Captcha的使用 1.下载Django Simple Captcha django-simple-captcha官方文档地址 http://django-simple- ...
- WUSTOJ 1889: 编辑距离(Java)
转自:
- 安全篇-AES/RSA加密机制
在服务器与终端设备进行HTTP通讯时,常常会被网络抓包.反编译(Android APK反编译工具)等技术得到HTTP通讯接口地址和参数.为了确保信息的安全,我们采用AES+RSA组合的方式进行接口参数 ...
- 使用Duilib开发Windows软件(1)——HelloWorld
我使用的是网易版本: https://github.com/netease-im/NIM_Duilib_Framework 时间是2019-11-28,作者最新的提交如下图: 运行官方示例程序 下载完 ...
- scratch少儿编程第一季——01、初识图形化界面编程的神器
各位小伙伴大家好: 说到2018年互联教育的热门事件,那就不得不提Scratch. 相信各位不关注信息技术领域的各位家长也都听说过这个东西. 对于小学阶段想要接触编程或信息技术学生来说,Scratch ...