[BD] Flume
什么是Flume
- 采集日志,存在HDFS上
- 分布式、高可用、高可靠的海量日志采集、聚合和传输系统
- 支持在日志系统中定制各类数据发送方,用于收集数据
- 支持对数据进行简单处理,写到数据接收方
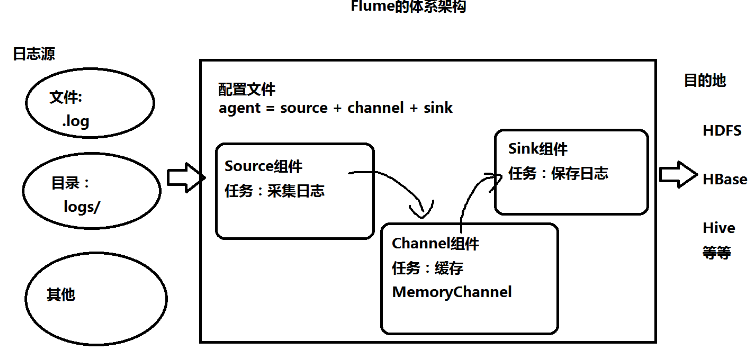
组件
- source:数据的来源
- avro:接收另一个flume的数据
- taildir:监控不断追加的日志文件
- channel:数据传输通道
- sink:数据落盘处
配置
- 配置文件


1 #bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
2 #定义agent名, source、channel、sink的名称
3 a4.sources = r1
4 a4.channels = c1
5 a4.sinks = k1
6
7 #具体定义source
8 a4.sources.r1.type = spooldir
9 a4.sources.r1.spoolDir = /root/training/logs
10
11 #具体定义channel
12 a4.channels.c1.type = memory
13 a4.channels.c1.capacity = 10000
14 a4.channels.c1.transactionCapacity = 100
15
16 #定义拦截器,为消息添加时间戳
17 a4.sources.r1.interceptors = i1
18 a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
19
20
21 #具体定义sink
22 a4.sinks.k1.type = hdfs
23 a4.sinks.k1.hdfs.path = hdfs://192.168.56.111:9000/flume/%Y%m%d
24 a4.sinks.k1.hdfs.filePrefix = events-
25 a4.sinks.k1.hdfs.fileType = DataStream
26
27 #不按照条数生成文件
28 a4.sinks.k1.hdfs.rollCount = 0
29 #HDFS上的文件达到128M时生成一个文件
30 a4.sinks.k1.hdfs.rollSize = 134217728
31 #HDFS上的文件达到60秒生成一个文件
32 a4.sinks.k1.hdfs.rollInterval = 60
33
34 #组装source、channel、sink
35 a4.sources.r1.channels = c1
36 a4.sinks.k1.channel = c1
命令
- 启动:bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
应用
- 采集网络传输信息
- node01安装flume,写配置文件,开启flume
- node02中telnet给node01发送信息
- 采集特定目录下新文件内容到HDFS
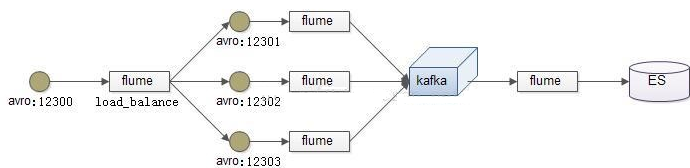
- 高可用(failover)
- agent1.sinkgroups.g1.processor.type = failover
- 停掉node02的agent,自动切换到node03上的agent
- 启动node02的agent,由于node02优先级高,自动切换回node02上的agent

- 负载均衡(load balancer)
- a1.sinkgroups.g1.processor.type = load_balance
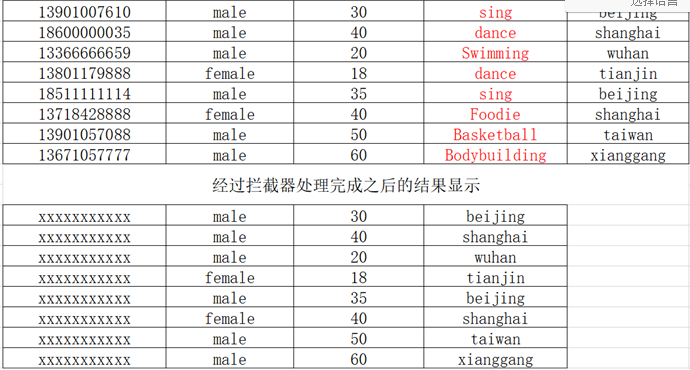
- 静态拦截器
- 将不同数据源的数据放在不同目录
- 自定义拦截器
- 数据采集后,将不需要的数据过滤掉,并将指定的第一个字段进行加密,再存到hdfs上
- a1.sources.r1.interceptors.i1.type =com.kkb.flume.interceptor.MyInterceptor$MyBuilder
- a1.sources.r1.interceptors.i1.encrypted_field_index=0
- a1.sources.r1.interceptors.i1.out_index=3



- 自定义source
- MySql数据采集到HDFS
参考
官方文档
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
快速入门
https://www.iteye.com/blog/manzhizhen-2298394
flume插件
https://www.cnblogs.com/mingfengshan/p/6853777.html
flume监控spoolDir日志到HDFS
https://blog.csdn.net/qq_20641565/article/details/52807776
avro sink 扩展
https://segmentfault.com/q/1010000023286882
source:avro
https://zhidao.baidu.com/question/373286862006114404.html
source:taildir
http://lxw1234.com/archives/2015/10/524.htm
[BD] Flume的更多相关文章
- flume的使用
1.flume的安装和配置 1.1 配置java_home,修改/opt/cdh/flume-1.5.0-cdh5.3.6/conf/flume-env.sh文件
- Flume1 初识Flume和虚拟机搭建Flume环境
前言: 工作中需要同步日志到hdfs,以前是找运维用rsync做同步,现在一般是用flume同步数据到hdfs.以前为了工作简单看个flume的一些东西,今天下午有时间自己利用虚拟机搭建了 ...
- Flume(4)实用环境搭建:source(spooldir)+channel(file)+sink(hdfs)方式
一.概述: 在实际的生产环境中,一般都会遇到将web服务器比如tomcat.Apache等中产生的日志倒入到HDFS中供分析使用的需求.这里的配置方式就是实现上述需求. 二.配置文件: #agent1 ...
- Flume(3)source组件之NetcatSource使用介绍
一.概述: 本节首先提供一个基于netcat的source+channel(memory)+sink(logger)的数据传输过程.然后剖析一下NetcatSource中的代码执行逻辑. 二.flum ...
- Flume(2)组件概述与列表
上一节搭建了flume的简单运行环境,并提供了一个基于netcat的演示.这一节继续对flume的整个流程进行进一步的说明. 一.flume的基本架构图: 下面这个图基本说明了flume的作用,以及f ...
- Flume(1)使用入门
一.概述: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统. 当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- flume使用示例
flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受 ...
随机推荐
- RabbitMQ 入门 (Go) - 4. 使用 Fanout Exchange 做服务发现(上)
到目前为止,我们项目的结果大致如下: 传感器生成的模拟数据(包含传感器名称.数据.时间戳)是通过传感器在运行时动态创建的 Queue 来发送的.这些 Queue 很难直接被发现. 为了解决这个问题,我 ...
- epoll poll select区别
函数依赖 ( Functional Dependency,FD) select:http://www.cnblogs.com/Anker/archive/2013/08/14/3258674.html ...
- 一本关于HTTP的恋爱日记
1991年 8月 我叫客户端,英文名字 client. 她叫服务端,英文名字 server. 这一年,我们出生了. 是的,我们都是90后. 我爱她,可是她却远在天边. 为了和她可以互诉衷肠,我同时发明 ...
- [GDKOI2021] 普及组 Day1 总结
[ G D K O I 2021 ] 普 及 组 D a y 1 总 结 [GDKOI2021] 普及组 Day1 总结 [GDKOI2021]普及组Day1总结 长达3天的快乐GDKOI2021普及 ...
- java面试-synchronized与lock有什么区别?
1.原始构成: synchronized是关键字,属于JVM层面,底层是由一对monitorenter和monitorexit指令实现的. ReentrantLock是一个具体类,是API层面的锁. ...
- 无线网络的应用之aircrack-ng
在kalilinux的aircracke-ng中.在这儿描述自己所遇到的问题并给予写blog 在使用之前,需要确定是否有对应的支持无线网卡监听的网卡,在虚拟机中需要先将网卡的驱动重定向到虚拟机内 在终 ...
- C程序数组算法 — 冒泡法排序【前冒 || 后冒】
第一种写法(前冒泡): /* C程序数组算法 - 冒泡法排序 * 此例子按照 大 -> 小 排序 * 原理:两两相比较,然后进行大小对调 * 比较次数: n^2 次 * 说明:冒泡排序是相对稳定 ...
- 消息中间件-RabbitMQ基本使用
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件).RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的.所有主要 ...
- JavaWeb 基础知识补充
软件架构 1. C/S: Client/Server 客户端/服务器端 * 在用户本地有一个客户端程序,在远程有一个服务器端程序 * 如:QQ,迅雷... ...
- 100天搞定机器学习:PyYAML基础教程
编程中免不了要写配置文件,今天我们继续Python网络编程,学习一个比 JSON 更简洁和强大的语言----YAML .本文老胡简单介绍 YAML 的语法和用法,以及 YAML 在机器学习项目中的应用 ...