使用HttpGet协议与正则表达实现桌面版的糗事百科
打开糗事百科笑话的主页,在这里我只取糗事笑话中文字这一板块,点击文字这一菜单栏。如下图。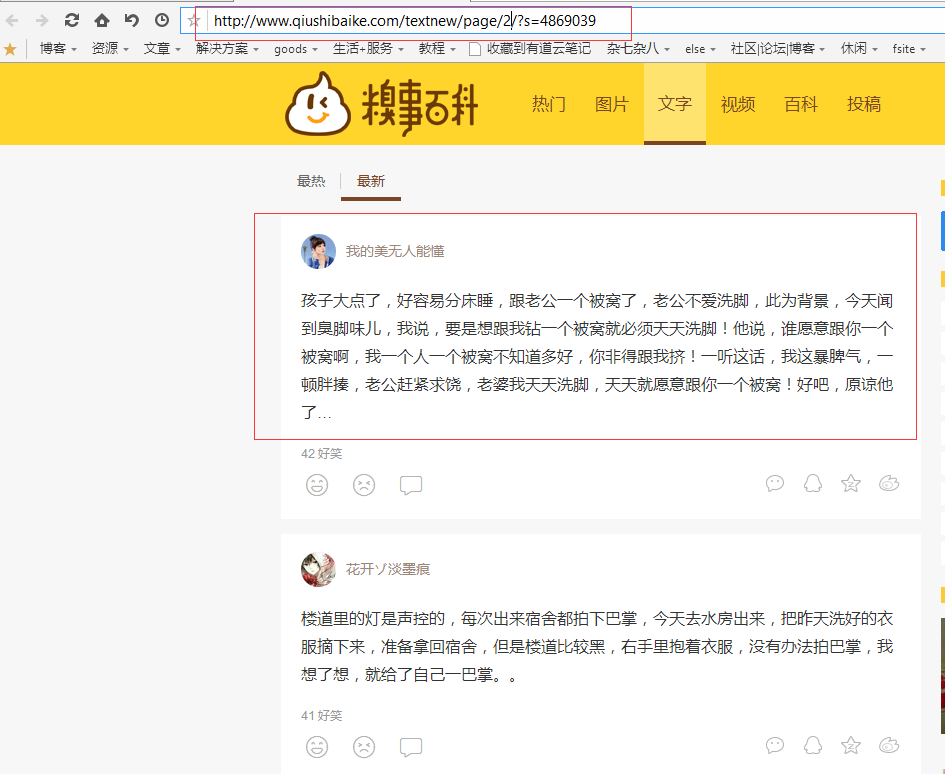
const string qsbkMainUrl = "http://www.qiushibaike.com";
//获取糗百文字笑话页的url
private static string GetWBJokeUrl(int pageIndex)
{
StringBuilder url = new StringBuilder();
url.Append(qsbkMainUrl);
url.Append ("/textnew/page/");
url.Append(pageIndex.ToString ());
url.Append("/?s=4869039");
return url.ToString();
}
//根据网页的url获取网页的html源码
private static string GetUrlContent(string url)
{
try
{
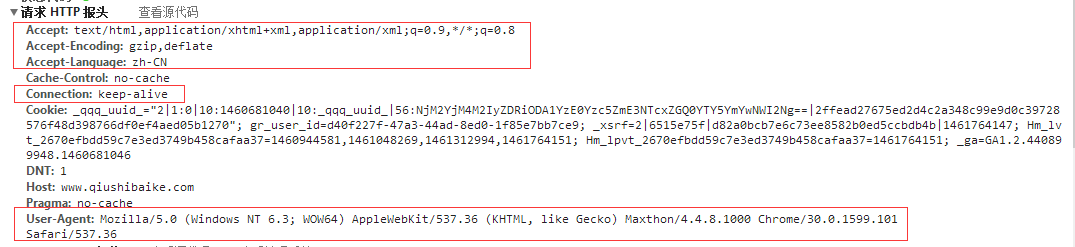
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.8.1000 Chrome/30.0.1599.101 Safari/537.36";
request.Method = "GET";
request.ContentType = "text/html;charset=UTF-8";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));//因为知道糗百网页的编码方式为utf-8
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
catch { return null; }
}
在1中我们已经根据page页索引的不同而获取不同的页面内容,而这一步的任务就是如何从返回的html源代码中获取我们想要的笑话内容。
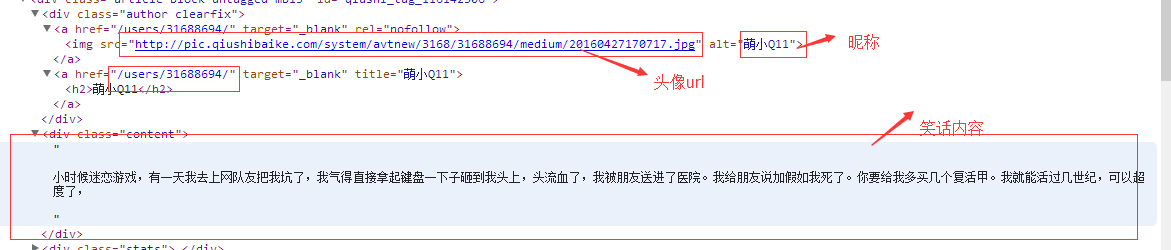
正则:<img src="([^"]*")\s*alt="([^"]*)"/>\s</a>\s<a href="([^"]*)"[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class="content">\s*((.*|<br/>)*)
public class JokeItem
{
private string nickName;
/// <summary>
/// 昵称
/// </summary>
public string NickName
{
get { return nickName; }
set { nickName = value; }
}
private Image headImage;
/// <summary>
/// 头像
/// </summary>
public Image HeadImage
{
get { return headImage; }
set { headImage = value; }
}
private string jokeContent;
/// <summary>
/// 笑话内容
/// </summary>
public string JokeContent
{
get { return jokeContent; }
set { jokeContent = value; }
}
private string jokeUrl;
/// <summary>
/// 笑话地址
/// </summary>
public string JokeUrl
{
get { return jokeUrl; }
set { jokeUrl = value; }
}
}
b、利用正则获取笑话内容
/// <summary>
/// 获取笑话列表
/// </summary>
/// <param name="htmlContent"></param>
public static List<JokeItem> GetJokeList(int pageIndex)
{
string htmlContent=GetUrlContent(GetWBJokeUrl(pageIndex));
List<JokeItem> jokeList = new List<JokeItem>();
Regex rg = new Regex(@"<img src=""([^""]*"")\s*alt=""([^""]*)""/>\s</a>\s<a href=""([^""]*)""[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class=""content"">\s*((.*|<br/>)*)", RegexOptions.IgnoreCase);
JokeItem joke;
MatchCollection matchResults = rg.Matches(htmlContent);
foreach (Match result in matchResults)
{
joke = new JokeItem();
joke.HeadImage = GetWebImage(result.Groups[].Value);
joke.HeadImage = joke.HeadImage != null ? new Bitmap(GetWebImage(result.Groups[].Value), , ) : null;
joke.NickName = result.Groups[].Value;
joke.JokeUrl = qsbkMainUrl + "/" + result.Groups[].Value; ;
joke.JokeContent = result.Groups[].Value.Replace("<br/>", "\r\n").Replace("<br>", "\r\n");
joke.JokeContent = Regex.Replace(joke.JokeContent, @"(\r\n)+", "\r\n");//去掉多余的空行
jokeList.Add(joke);
}
return jokeList;
}
c、根据头像url地址获取头像
private static Image GetWebImage(string webUrl)
{
try
{
Encoding encode = Encoding.GetEncoding("utf-8");//网页编码==Encoding.UTF8
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(new Uri(webUrl));
HttpWebResponse ress = (HttpWebResponse)req.GetResponse();
Stream sstreamRes = ress.GetResponseStream();
return System.Drawing.Image.FromStream(sstreamRes);
}
catch { return null; }
}
3、数据绑定
使用HttpGet协议与正则表达实现桌面版的糗事百科的更多相关文章
- HttpGet协议与正则表达
使用HttpGet协议与正则表达实现桌面版的糗事百科 写在前面 最近在重温asp.net,找了一本相关的书籍.本书在第一章就讲了,在不使用浏览器的情况下生成一个web请求,获取服务器返回的内容.于 ...
- python+正则提取+ip代理爬取糗事百科文字信息
很多网站都有反爬措施,最常见的就是封ip,请求次数过多服务器会拒绝连接,如图: 在程序中设置一个代理ip,可有效的解决这种问题,代码如下: # 需要的库 import requests import ...
- Python+Requests+Re(正则)爬取某糗事百科图片(数据分析一)
1.博客目前在学习爬虫课程,使用正则表达式来爬取网页的图片信息 2.下面我们一起来回归下Python中的正则使用方式/方法 3.糗事百科图片爬取源码如下: import requestsimport ...
- python+正则+多进程爬取糗事百科图片
话不多说,直接上代码: # 需要的库 import requests import re import os from multiprocessing import Pool # 请求头 header ...
- Javascript正则构造函数与正则表达字面量&&常用正则表达式
本文不讨论正则表达式入门,即如何使用正则匹配.讨论的是两种创建正则表达式的优劣和一些细节,最后给出一些常用正则匹配表达式. Javascript中的正则表达式也是对象,我们可以使用两种方法创建正则表达 ...
- js正则表达test、exec和match的区别
test的用法和exec一致,只不过返回值是 true false. 以前用js很少用到js的正则表达式,即使用到了,也是诸如邮件名称之类的判断,网上代码很多,很少有研究,拿来即用. 最近开发遇到一些 ...
- 正则表达示 for Python3
前情提要 从大量的文字内容中找到自己想要的东西,正则似乎是最好的方法.也是写爬虫不可缺少的技能.所以,别墨迹了赶紧好好学吧! 教程来自http://www.runoob.com/python3/pyt ...
- Python之面向对象和正则表达(代数运算和自动更正)
面向对象 一.概念解释 面对对象编程(OOP:object oriented programming):是一种程序设计范型,同时也是一种程序开发的方法,实现OOP的程序希望能够在程序中包含各种独立而又 ...
- JS写法 数值与字符串的相互转换 取字符中的一部分显示 正则表达规则
http://www.imooc.com/article/15885 正则表达规则 <script type="text/javascript"> </scrip ...
随机推荐
- 本地数据库导入线上服务器的mongodb中
更改默认端口 sudo vi /etc/mongod.conf 进入conf文件,修改port值为19999保存并退出. 重启mongodb sudo service mongod restart 进 ...
- MySQL实例crash的案例分析
[作者] 王栋:携程技术保障中心数据库专家,对数据库疑难问题的排查和数据库自动化智能化运维工具的开发有强烈的兴趣. [问题描述] 我们生产环境有一组集群的多台MySQL服务器(MySQL 5.6.21 ...
- springMvc的执行流程(源码分析)
1.在springMvc中负责处理请求的类为DispatcherServlet,这个类与我们传统的Servlet是一样的.我们来看看它的继承图 2. 我们发现DispatcherServlet也继承了 ...
- leetcode-917-仅仅反转字母
题目描述: 给定一个字符串 S,返回 “反转后的” 字符串,其中不是字母的字符都保留在原地,而所有字母的位置发生反转. 示例 1: 输入:"ab-cd" 输出:"dc-b ...
- 数据分析库Pandas
Pandas介绍 导入pandas库 import pandas as pd 读取CSV文件 df = pd.read_csv('file_name') #注意文件路径 读取前几条数据 df.head ...
- SQL实现数据行列转换
前言: 在日常的工作中,使用数据库查看数据是很经常的事,数据库的数据非常多,如果此时的数据设计是一行行的设计话,就会有多行同一个用户的数据,查看起来比较费劲,如果数据较多时,不方便查看,为了更加方便工 ...
- iOS开发证书与配置文件的使用
前提 众所周知,开发iOS应用必须要有iOS证书(Certificates)和配置文件(Provisioning Profiles),那么问题来了: 1.什么是iOS证书,它是如何与app应用关联的? ...
- java基本语法二
1 运算符 1.1 运算符的概念 运算符是一种特殊的符号,用以表示数据的运算.赋值和比较等. 在java语言中,运算符有如下的分类: ①算术运算符. ②赋值运算符. ③比较运算符(关系运算符). ④逻 ...
- Netty核心概念(9)之Future
1.前言 第7节讲解JAVA的线程模型中就说到了Future,并解释了为什么可以主线程可以获得线程池任务的执行后结果,变成一种同步状态.秘密就在于Java将所有的runnable和callable任务 ...
- 初始JAVA中浅拷贝和深拷贝
1. 简单变量的复制 public static void main(String[] args) { int a = 5; int b = a; System.out.println(a); Sys ...