Python+Requests+Re(正则)爬取某糗事百科图片(数据分析一)
1、博客目前在学习爬虫课程,使用正则表达式来爬取网页的图片信息
2、下面我们一起来回归下Python中的正则使用方式/方法
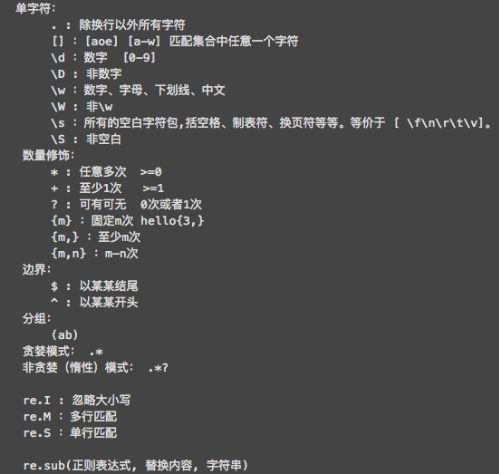
3、糗事百科图片爬取源码如下:
import requests
import re
import os
if __name__ == '__main__':
# headers请求头信息
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
# 新建文件夹用来存储糗事图片
if not os.path.exists('./qiushiLibs'):
os.makedirs('./qiushiLibs')
# Url进行封装循环分页爬取
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
for page in range(1,2):
new_url = format(url%page)
# 调用get请求获取text字符串
page_source = requests.get(url=new_url,headers=headers).text
# 正则表达式:使用到非贪婪模式
ER = r'<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
# 返回list数组
img_src_list = re.findall(ER,page_source,re.S)
for src in img_src_list:
# 遍历拼接图片URL
src = 'https:'+src
# 下载图片新建请求
# 以二进制流的方式存储
img_content = requests.get(url=src,headers=headers).content
# print(img_content)
# 生成图片的名称
imgName = src.split('/')[-1]
# 图片路径
imgPath = './qiushiLibs/'+imgName
# 持久化存储
with open(imgPath,'wb') as fp:
fp.write(img_content)
print(imgName,'下载成功!!!')
Python+Requests+Re(正则)爬取某糗事百科图片(数据分析一)的更多相关文章
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
- [Python]网络爬虫(八):糗事百科的网络爬虫(v0.2)源码及解析
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8932310 项目内容: 用Python写的糗事百科的网络爬虫. 使用方法: 新建一个 ...
- python+正则+多进程爬取糗事百科图片
话不多说,直接上代码: # 需要的库 import requests import re import os from multiprocessing import Pool # 请求头 header ...
- python requests库网页爬取小实例:百度/360搜索关键词提交
百度/360搜索关键词提交全代码: #百度/360搜索关键词提交import requestskeyword='Python'try: #百度关键字 # kv={'wd':keyword} #360关 ...
- Python Requests库网络爬取全代码
#爬取京东商品全代码 import requestsurl = "http://item.jd.com/2967929.html"try: r = requests.get(url ...
- python requests库网页爬取小实例:亚马逊商品页面的爬取
由于直接通过requests.get()方法去爬取网页,它的头部信息的user-agent显示的是python-requests/2.21.0,所以亚马逊网站可能会拒绝访问.所以我们要更改访问的头部信 ...
- python Requests库网络爬取IP地址归属地的自动查询
#IP地址查询全代码import requestsurl = "http://m.ip138.com/ip.asp?ip="try: r = requests.get(url + ...
- python+BeautifulSoup+多进程爬取糗事百科图片
用到的库: import requests import os from bs4 import BeautifulSoup import time from multiprocessing impor ...
- 【Python】python3 正则爬取网页输出中文乱码解决
爬取网页时候print输出的时候有中文输出乱码 例如: \\xe4\\xb8\\xad\\xe5\\x8d\\x8e\\xe4\\xb9\\xa6\\xe5\\xb1\\x80 #爬取https:// ...
随机推荐
- oracle表ddl审计
============= 表ddl 审计============== 1.table信息 SQL> select * from test; ID CUST_CREDIT_LIMIT TIME ...
- 简单理解数据库连接池(JDBC)
为什么要使用连接池? 在我们写代码的时候,写了很多类,假如这些类都和数据库打交道.这样的话每个类都要去获取数据库连接,操作完了之后就把连接释放了. 要知道,获取数据库连接的操作其实是向操作系统底层去获 ...
- CentOS:操作系统级监控及常用计数器解析---除CPU以外
I/O I/O 其实是挺复杂的一个逻辑,但我们今天只说在做性能分析的时候,应该如何定位问题. 对性能优化比较有经验的人(或者说见过世面比较多的人)都会知道,当一个系统调到非常精致的程度时,基本上会卡在 ...
- sql:group by和 max
通过group by,having,max实现查询出每组里指定列中最大的内容 例如:我需要实现的功能是 获取每个模块中点击量最大的内容(表中有许多内容,内容里) 我写的查询语句如下 查询结果如下: 然 ...
- csp-s模拟测试59(10.4)「Reverse」(set)·「Silhouette」(容斥)
A. Reverse 菜鸡wwb又不会了..... 可以线段树优化建边,然而不会所以只能set水了 发现对于k和当前反转点固定的节点x确定奇偶性所到达的节点奇偶性是一定的 那么set维护奇偶点,然后每 ...
- 开箱即用的微服务框架 Go-zero(进阶篇)
之前我们简单介绍过 Go-zero 详见<Go-zero:开箱即用的微服务框架>.这次我们从动手实现一个 Blog 项目的用户模块出发,详细讲述 Go-zero 的使用. 特别说明本文涉及 ...
- 【科普】MySQL中DDL操作背后的并发原理
一. 简介 DQL:指数据库中的查询(select)操作. DML:指数据库中的插入(insert).更新(update).删除(delete)等行数据变更操作. DDL:指数据库中加列(add co ...
- NAT网络地址转换技术
NAT网络地址转换技术 目录 一.NAT概述 1.1.概述 1.2.NAT 的应用场景 二.NAT的类型及配置命令 2.1.静态NAT 2.2.动态NAT 2.3.Easy IP 2.4.NATP 2 ...
- CVPR2021 | 开放世界的目标检测
本文将介绍一篇很有意思的论文,该方向比较新,故本文保留了较多论文中的设计思路,背景知识等相关内容. 前言: 人类具有识别环境中未知对象实例的本能.当相应的知识最终可用时,对这些未知实例的内在好奇心 ...
- uniapp 打包IOS 更新AppStore版本
Hello 你好,我是大粽子. 最近随着新版本UI的发布APP也随之更新,随之而来的也就是IOS程序提审步骤,这次我详细的截图了每一个步骤,如果你正好也需要那么跟着我的节奏一步步来肯定是没问题的. 提 ...