ES分布式原理
参考:https://blog.csdn.net/chang384915878/article/details/86747419
一、准备知识
这里只是简单的介绍,详情可以看我的另一篇博客:https://www.cnblogs.com/JimShi/p/11309651.html
elasticsearch设计的理念就是分布式搜索引擎,底层实现还是基于Lucene的,核心思想是在多态机器上启动多个es进程实例,组成一个es集群。了解几个概念:
1、接近实时
es是一个接近实时的搜索平台,这就意味着,从索引一个文档直到文档能够被搜索到有一个轻微的延迟
2、集群(cluster)
一个集群有多个节点(服务器)组成,通过所有的节点一起保存你的全部数据并且通过联合索引和搜索功能的节点的集合,每一个集群有一个唯一的名称标识
3、节点(node)
一个节点就是一个单一的服务器,是你的集群的一部分,存储数据,并且参与集群和搜索功能,一个节点可以通过配置特定的名称来加入特定的集群,在一个集群中,你想启动多少个节点就可以启动多少个节点。
4、索引(index)
一个索引就是还有某些共有特性的文档的集合,一个索引被一个名称唯一标识,并且这个名称被用于索引通过文档去执行搜索,更新和删除操作。
5、类型(type)
type 在6.0.0已经不赞成使用
为什么不使用?https://www.cnblogs.com/JimShi/p/11309651.html
6、文档(document)
一个文档是一个基本的搜索单元
二、如何实现分布式
1、分片
Elasticsearch 也是会对数据进行切分,同时每一个分片会保存多个副本,其原因是为了保证分布式环境下的高可用,同时也扩大了存储空间。es也是master-slave架构,在 es 中,节点是对等的,节点间会通过自己的一些规则选取集群的 Master,Master 会负责集群状态信息的改变,并同步给其他节点。值得注意的是,只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的。
具体就是你先建立一个索引,这个索引可以拆分成多个 shard,每个 shard 存储部分数据。这个shard 的数据实际是有多个备份,就是说每个 shard 都有一个 primary shard,负责写入数据,但是还有几个 replica shard。primary shard 写入数据之后,会将数据同步到其他几个 replica shard 上去。
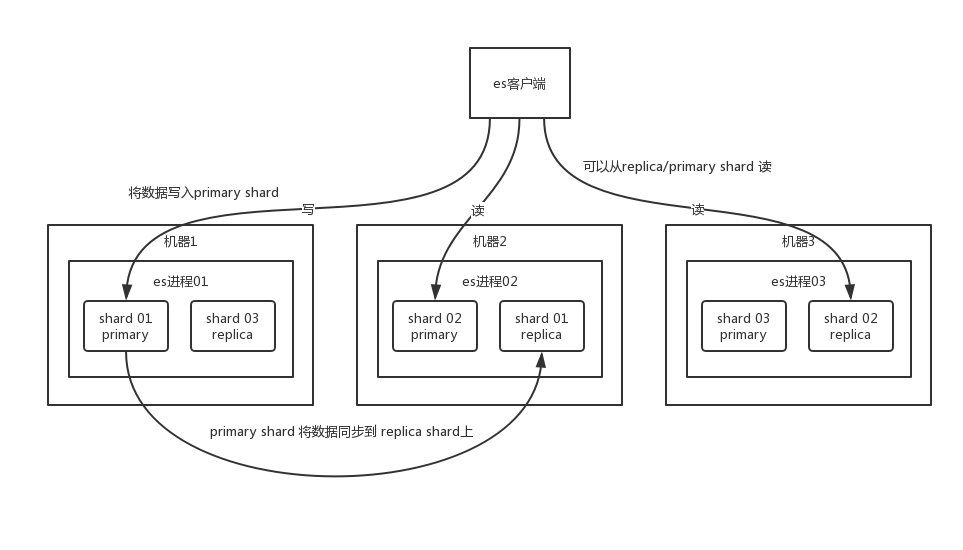
通过这个 replica 的方案,每个 shard 的数据都有多个备份,如果某个机器宕机了,没关系啊,还有别的数据副本在别的机器上呢。高可用了吧。
es 集群多个节点,会自动选举一个节点为 master 节点,这个 master 节点其实就是干一些管理的工作的,比如维护索引元数据、负责切换 primary shard 和 replica shard 身份等。要是 master 节点宕机了,那么会重新选举一个节点为 master 节点。如果是非 master节点宕机了,那么会由 master 节点,让那个宕机节点上的 primary shard 的身份转移到其他机器上的 replica shard。接着你要是修复了那个宕机机器,重启了之后,master 节点会控制将缺失的 replica shard 分配过去,同步后续修改的数据之类的,让集群恢复正常。说得更简单一点,就是说如果某个非 master 节点宕机了。那么此节点上的 primary shard 不就没了。那好,master 会让 primary shard 对应的 replica shard(在其他机器上)切换为 primary shard。如果宕机的机器修复了,修复后的节点也不再是 primary shard,而是 replica shard。
其实上述就是 ElasticSearch 作为分布式搜索引擎最基本的一个架构设计。
ES分布式原理的更多相关文章
- 学习笔记TF061:分布式TensorFlow,分布式原理、最佳实践
分布式TensorFlow由高性能gRPC库底层技术支持.Martin Abadi.Ashish Agarwal.Paul Barham论文<TensorFlow:Large-Scale Mac ...
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- scrapy分布式原理
scrapy分布式原理 关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键 ...
- Elasticsearch学习系列七(Es分布式集群)
核心概念 集群(Cluster) 一个Es集群由多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识 节点(Node) 一个Es实例就是一个Node.Es的配置文件中可以通过node.ma ...
- elasticsearch 口水篇(5)es分布式集群初探
es有很多特性,分布式.副本集.负载均衡.容灾等. 我们先搭建一个很简单的分布式集群(伪),在同一机器上配置三个es,配置分别如下: cluster.name: foxCluster node.nam ...
- ES 分布式搜索
ES整个查询过程是scatter/gather的过程,具体如下: 图见 https://blog.csdn.net/thomas0yang/article/details/78572596?utm_s ...
- 29.es路由原理
主要知识点 1.document路由到shard的理解及原理 2.路由算法:shard = hash(routing) % number_of_primary_shards 3.routing值(_i ...
- 9.简单理解ES分布式
主要知识点: 1.Elasticsearch对复杂分布式机制的透明隐藏特性 2.Elasticsearch的垂直扩容与水平扩容 3.增减或减少节点时的数据rebalance 4.master节 ...
- es倒排索引原理解析
倒排索引原理 普通的存储方式是给每个文档编一个序号 然后让这个序号对应单个文档的所有内容 如果用这样的方式查找 当需要查找某个单词的时候需要遍历所有的文档集合 查找文档的效率会非常的慢 2.基本 ...
随机推荐
- 排序算法总结(java实现)
排序算法 介绍:排序分为内部排序和外部排序,内部排序指在内存中进行的排序过程:外部排序指在外存中进行排序的过程,但是此过程建立在多次访问内存的基础上(分成一段段利用内部排序进行排序). 以下排序均属于 ...
- What is the !! (not not) operator in JavaScript?
What is the !! (not not) operator in JavaScript? 解答1 Coerces强制 oObject to boolean. If it was falsey ...
- 怎么理解一个规模大且结构复杂的c工程源码
很久以前,当要着手一个规模很大,结构复杂的c工程源码时,总是感觉无从下手.这个时候,一般google一下”XX源码分析“.当这个源码是很广泛使用的时,这样到也能得到不少启发:很不幸,经常要接触一些很少 ...
- Uep查询语句总结
今天没事干总结一下uep查询语句: 第一种方法: 注意在实体写上对应的构造方法 package com.haiyisoft.entity.wz; import java.math.BigDecimal ...
- EC
- linux(centOS7)的基本操作(七) 其它
本地与linux服务器之间的文件传输 本地下载的文件,如果想在远端的linux服务器上执行,需要文件传输.如果本地使用windows系统,则借助XFTP软件的图形界面即可.如果本地使用macOS系统, ...
- Python_序列对象内置方法详解_String
目录 目录 前言 软件环境 序列类型 序列的操作方法 索引调用 切片运算符 扩展切片运算符 序列元素的反转 连接操作符 重复运算符 成员关系符 序列内置方法 len 获取序列对象的长度 zip 混合两 ...
- 十五:jinja2过滤器之实现自定义过滤器
过滤器的本质就是函数,如果在模板中调用这个过滤器,那么就会将这个变量的值作为第一个参数传给过滤器函数,然后将函数的返回值作为滤器的返回值 1.在python文件中写好过滤的函数和逻辑2.将将函数注册到 ...
- Linq之旅:Linq入门详解(Linq to Objects)(转)
http://www.cnblogs.com/heyuquan/p/Linq-to-Objects.html 示例代码下载:Linq之旅:Linq入门详解(Linq to Objects) 本博文详细 ...
- delphi中 formclose的事件 action:=cafree form:=nil分别是什么意思?
MDI子窗体关闭时用到的(以下摘自Delphi的帮助)caNone The form is not allowed to close, so nothing happens.caHide The ...