Matplotlib学习---用matplotlib和sklearn画拟合线(line of best fit)
在机器学习中,经常要用scikit-learn里面的线性回归模型来对数据进行拟合,进而找到数据的规律,从而达到预测的目的。用图像展示数据及其拟合线可以非常直观地看出拟合线与数据的匹配程度,同时也可用于后续的解释和阐述工作。
这里利用Nathan Yau所著的《鲜活的数据:数据可视化指南》一书中的数据,学习画图。
数据地址:http://datasets.flowingdata.com/unemployment-rate-1948-2010.csv
准备工作:先导入matplotlib和pandas,用pandas读取csv文件,然后创建一个图像和一个坐标轴
import pandas as pd
from matplotlib import pyplot as plt
unemployment=pd.read_csv(r"http://datasets.flowingdata.com/unemployment-rate-1948-2010.csv")
fig,ax=plt.subplots()
让我们先来看看这个数据文件(此处只截取部分):
Series id Year Period Value
0 LNS14000000 1948 M01 3.4
1 LNS14000000 1948 M02 3.8
2 LNS14000000 1948 M03 4.0
3 LNS14000000 1948 M04 3.9
4 LNS14000000 1948 M05 3.5
.. ... ... ... ...
716 LNS14000000 2007 M09 4.7
717 LNS14000000 2007 M10 4.7
718 LNS14000000 2007 M11 4.7
719 LNS14000000 2007 M12 5.0
这个数据展示的是美国1948年到2010年各月份的失业率。
我们需要先把数据用散点图画出来,再用sklearn对数据进行拟合,最后把拟合线也画出来。
首先,把年份和失业率数据提取出来,画出散点图。这里需要注意的是,年份数据比失业率数据规模大很多(年份以千计,失业率大部分是个位数),因此在拟合前需要进行特征缩放,否则年份这一特征值的影响将远远大于失业率。
其次,从sklearn导入线性回归模块。假设数据模型属于简单线性回归,此时,就是把年份数据当作自变量(通常记为变量x),失业率数据当作因变量(通常记为变量y),找出它们之间的线性关系。然后在散点图上画出此拟合线。需要注意的是:年份数据是一维数组,需要将其转换为二维矩阵(这个矩阵的每一列为各个特征的量化值,每一行为每个样本的观测数据),才可以用sklearn进行拟合。通常通过x.reshape(-1,1)方法或x[:,np.newaxis]方法将其转换。
此时图像如下:
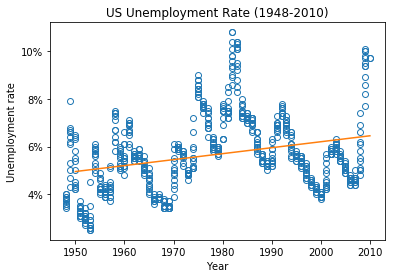
可以看出,这条拟合线并不能很好反映出数据的pattern。
所以接下来,我们再用多项式回归模型来试一试。sklearn里面并没有直接的多项式回归模块可供我们使用,而是需要从sklearn.preprocessing导入PolynomialFeatures,在PolynomialFeatures里确定进行几次多项式变换,将年份自变量转换为多项式形式,然后再用线性模型进行拟合。例如:假设年份自变量为:
[[19]
[20]
[21]]
那么将其转换为二次多项式形式(degree=2)后就变成:
[[1 19 361]
[1 20 400]
[1 21 441]]
这样就相当于把原有的方程式y=b1x+a转换成了y=b1x+b2x2+1+a。
完整代码如下:
import numpy as np
import pandas as pd
import matplotlib
from matplotlib import pyplot as plt
unemployment=pd.read_csv(r"http://datasets.flowingdata.com/unemployment-rate-1948-2010.csv")
fig,ax=plt.subplots(figsize=(10,6)) #提取年份和对应的失业率数据,由于年份数据都是上千,而失业率大都是个位数,
#因此这里要用到特征缩放,把年份缩小100倍
x=unemployment["Year"].values/100
y=unemployment["Value"].values #以年份为x轴,失业率为y轴,画出散点图
ax.plot(x,y,"o",markerfacecolor="none")
ax.set(xlabel="Year",ylabel="Unemployment rate",title="US Unemployment Rate (1948-2010)")
ax.yaxis.set_major_formatter(matplotlib.ticker.FormatStrFormatter('%.f%%')) #把y轴刻度值设置为百分比形式
ax.set_xticklabels(np.arange(1940,2011,10)) #设置x轴刻度标签 #假设数据属于简单线性回归,对其进行拟合
from sklearn.linear_model import LinearRegression
linear=LinearRegression()
xfit=x.reshape(-1,1)
yfit=y.reshape(-1,1)
linear.fit(xfit,yfit)
xpre=np.linspace(19.5,20.1,num=50,endpoint=True) #创建用于预测的x值
ypre=linear.predict(xpre[:,np.newaxis]) ax.plot(xpre,ypre,"-",label="degree 1") #假设数据属于多项式回归,分别对其进行拟合
from sklearn.preprocessing import PolynomialFeatures
for i in [2,4]:
PF=PolynomialFeatures(degree=i)
xfit1=PF.fit_transform(xfit)
linear1=LinearRegression()
linear1.fit(xfit1,yfit)
xpre1=PF.fit_transform(xpre[:,np.newaxis])
ypre1=linear1.predict(xpre1)
ax.plot(xpre,ypre1,"-",label="degree {}".format(i)) ax.legend() plt.show()
图像如下:
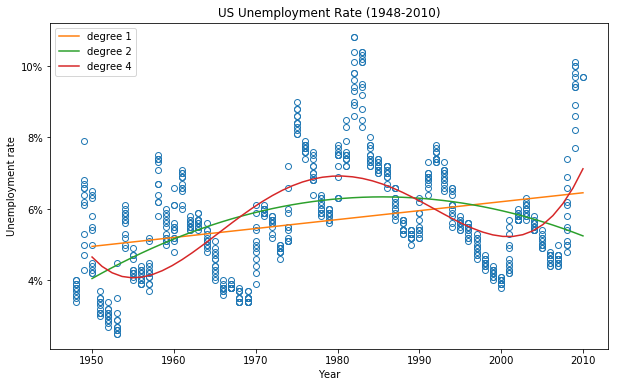
可以看出,用多项式回归模型进行拟合的效果比较好。
Matplotlib学习---用matplotlib和sklearn画拟合线(line of best fit)的更多相关文章
- Matplotlib学习---用matplotlib画箱线图(boxplot)
箱线图通过数据的四分位数来展示数据的分布情况.例如:数据的中心位置,数据间的离散程度,是否有异常值等. 把数据从小到大进行排列并等分成四份,第一分位数(Q1),第二分位数(Q2)和第三分位数(Q3)分 ...
- Matplotlib学习---用matplotlib画直方图/密度图(histogram, density plot)
直方图用于展示数据的分布情况,x轴是一个连续变量,y轴是该变量的频次. 下面利用Nathan Yau所著的<鲜活的数据:数据可视化指南>一书中的数据,学习画图. 数据地址:http://d ...
- Matplotlib学习---用matplotlib画误差线(errorbar)
误差线用于显示数据的不确定程度,误差一般使用标准差(Standard Deviation)或标准误差(Standard Error). 标准差(SD):是方差的算术平方根.如果是总体标准差,那么用σ表 ...
- Matplotlib学习---用matplotlib画阶梯图(step plot)
这里利用Nathan Yau所著的<鲜活的数据:数据可视化指南>一书中的数据,学习画图. 数据地址:http://datasets.flowingdata.com/us-postage.c ...
- Matplotlib学习---用matplotlib画面积图(area chart)
这里利用Nathan Yau所著的<鲜活的数据:数据可视化指南>一书中的数据,学习画图. 数据地址:http://book.flowingdata.com/ch05/data/us-pop ...
- Matplotlib学习---用matplotlib画热图(heatmap)
这里利用Nathan Yau所著的<鲜活的数据:数据可视化指南>一书中的数据,学习画图. 数据地址:http://datasets.flowingdata.com/ppg2008.csv ...
- Matplotlib学习---用matplotlib画饼图/面包圈图(pie chart, donut chart)
我在网上随便找了一组数据,用它来学习画图.大家可以直接把下面的数据复制到excel里,然后用pandas的read_excel命令读取.或者直接在脚本里创建该数据. 饼图: ax.pie(x,labe ...
- Matplotlib学习---用matplotlib画折线图(line chart)
这里利用Jake Vanderplas所著的<Python数据科学手册>一书中的数据,学习画图. 数据地址:https://raw.githubusercontent.com/jakevd ...
- Matplotlib学习---用matplotlib画散点图,气泡图(scatter plot, bubble chart)
Matplotlib里有两种画散点图的方法,一种是用ax.plot画,一种是用ax.scatter画. 一. 用ax.plot画 ax.plot(x,y,marker="o",co ...
随机推荐
- [程序员的业余生活]一周读完《高效能人士的七个习惯》Day1:这是不是一碗鸡汤?
提出问题 今天突然想聊聊最近对职场的一些感悟. 这段时间,小端一直在思考一个问题:作为一个程序员,怎么才能成为团队的核心? 还记得刚入职场那几年,小端一直觉得,技术过硬,经验丰富,敢打敢拼,就是答案. ...
- 二十四、小程序中改变checkbox和radio的样式
来源:https://blog.csdn.net/qq_39364032/article/details/79742415 在微信小程序里面,有时候为了配合整个项目的风格,checkbox和radio ...
- Python-类的组合与重用
软件重用的重要方式除了继承之外还有另外一种方式,即:组合 组合指的是,在一个类中以另外一个类的对象作为数据属性,称为类的组合 1.继承的方式 通过继承建立了派生类与基类之间的关系,它是一种'是'的关系 ...
- C. Painting the Fence
链接 [https://codeforces.com/contest/1132/problem/C] 题意 就是有个n长的栅栏,然后每个油漆工可以染的区域不同 给你q让你选出q-2个人使得被染色的栅栏 ...
- 广州商学院16级软工一班&二班-第一次作业成绩
广州商学院16级软工一班&二班-第一次作业成绩 作业地址 16软工一班 16软工二班 总结 本次作业反映了几个比较严重的问题: 不按要求阅读相应的文章,回答问题只是敷衍几句. 部分同学的版式混 ...
- Podfile语法参考(译)
https://www.jianshu.com/p/8af475c4f717 2015.10.30 19:14* 字数 2496 阅读 35976评论 9喜欢 120 本文翻译自官方的Podfile ...
- message:GDI+ 中发生一般性错误。
图片类型的文件保存的时候出了问题,可能是路径出错,也可能是保存到的文件夹不存在导致(发布项目的时候如果文件夹是空的,文件夹将不存在)
- [2017BUAA软工助教]个人项目小结
2017BUAA个人项目小结 一.作业链接 http://www.cnblogs.com/jiel/p/7545780.html 二.评分细则 0.注意事项 按时间完成并提交--正常评分 晚交一周以内 ...
- bootstrap简单使用
Bootstrap (版本 v3.3.7) 官网教程: https://v3.bootcss.com/css/ row——行 row——列 push——推 pull——拉 col-md-o ...
- 01-学习vue前的准备工作
起步 1.扎实的HTML/CSS/Javascript基本功,这是前置条件. 2.不要用任何的构建项目工具,只用最简单的<script>,把教程里的例子模仿一遍,理解用法.不推荐上来就直接 ...