Spark学习笔记
Map-Reduce

我认为上图代表着MapReduce不仅仅包括Map和Reduce两个步骤这么简单,还有两个隐含步骤没有明确,全部步骤包括:切片、转换、聚合、叠加,按照实际的运算场景上述步骤可以简化。
具体的流程为:
- 原始数据 -) [切片] -> 数据对单元集合(列表) (k1,v1)
- 数据对单元集合 (k1,v1) -> [Map转换] -) 数据对单元集合 (k2,v2)
- 数据对单元集合 (k2,v2) -> [聚合(合并] -) 数据对单元集合(字典)(k2,[v2])
- 数据对单元集合 (k2,[v2]) -> [抽象(叠加)reduce] -) 数据对单元集合(列表)[(k3,v3)]
Spark作业流程

- 用户编写Spark程序,定义RDD创建、转换、行动、存储等操作。提交程序(spark-submit xx.py)申请Spark集群执行该程序;
- Spark集群收到用户的程序后,启动Driver进程,负责响应执行用户的函数。Driver也可以在Client端启动,也可以在某个worker节点启动; Driver启动后,发现函数包含了RDD的相关操作(这些操作会分散在集群中并行完成),与Master节点通信申请资源;
- 在Spark集群中的所有worker节点都会向Master节点注册自己的计算资源;Master资源会通过心跳检测来检测节点状态;在收到driver在3条件下申请后,master会命令已注册的worker节点按照调度策略启动executor进程;
- Master检查发现worker节点状态存活且worker节点上的executor启动成功,Master将已经启动的资源信息通知driver进程,让driver进程了解可以使用哪些资源来完成Spark程序;
- driver根据Spark程序中的RDD操作情况对程序进行分割,分割后的任务发送给已经申请的多个executor资源,每个executor独立完成分配的计算任务,并将执行的结果反馈给driver,driver负责了解每一个executor进程的完成情况,以统一了解整个spark程序的完成情况;
- worker节点上运行的executor是真正工作的执行者,在每个worker节点上可以启动多个executor,每个executor单独运行一个JVM进程,每个计算任务则是运行在executor中的一个线程,最后executor负责将计算结果保存到磁盘中;
- driver通知client应用程序执行完成。
上述的步骤中有三个细节需要特别注意:
- spark采用惰性计算来生成RDD(只有遇到action操作才会生成新的RDD),生成操作通过将所有相关操作形成一个有向无环图DAG来试试,每个DAG会触发Spark生成一个作业。
- driver节点中的DAGScheduler实例会想有向无环图中的节点依赖关系遍历,并将所有操作切分成多个调度阶段(stage),并生成对应的taskSet。
- driver节点中的TaskScheduler会为每一个taskSet生成taskSetManager(管理每个taskset的内部调度任务,维护taskset的声明周期),并提交到worker节点的executor进程中执行。
- 从微观上来看,一个spark应用程序最终是分解成了多个taskset的任务急。在并行执行taskset的情况下,TaskScheduler调度策略可以分为FIFO先进先出和FAIR公平调度两种模式。
Spark并发机制
- Spark的基础数据结构RDD是由一系列的分区构成的,每个分区中包含一个RDD的部分数据;
- 在Spark调度和执行计算任务时,会为RDD的每个分区创建一个Task;
- 默认的情况下,Spark为每个需要执行的Task分配一个CPU内核资源


Spark RDD和Job生命周期
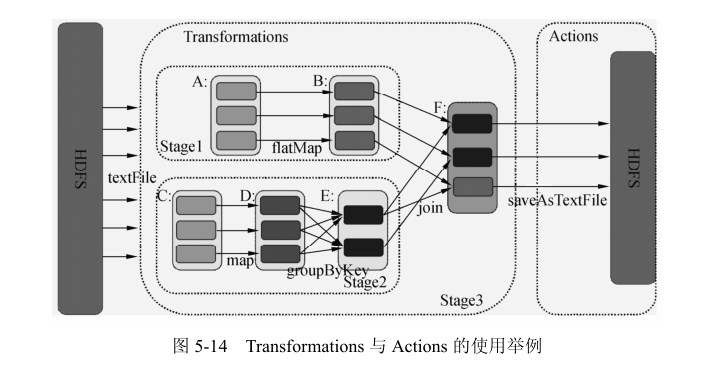
RDD 的生存周期主要包括 RDD 的创建和操作。RDD 的创建有两种方式:从 HDFS(或其他分布式存储系统)输入创建以及从父 RDD 转换得到新 RDD。对于 RDD 的操作可以分为两种,即 Transformation 和 Action。Transformation 是根据现有的数据集创建一个新的数据集,Action 是在 RDD 上运行计算后,返回一个值给驱动程序。Transformations 操作是Lazy 的,也就是说从一个 RDD 转换生成 转换生成另一个 RDD 的操作不马上执行,Spark 在遇到Transformations 操作时只会记录需要这样的操作,并不会去执行,需要等到有 Actions 操作的时候才会真正启动计算过程进行计算。
Job 的生存周期是从 Action 作用于某 RDD 时开始的,此时该 Action 将会作为一个 Job被提交。在提交的过程中,DAGScheduler 模块介入运算,计算 RDD 之间的依赖关系。RDD之间的依赖关系就形成了 DAG。每一个 Job 被分为多个 stage,划分 stage 的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个 stage,避免多个 stage 之间的消息传递开销。当 stage 被提交之后,由 TaskScheduler 根据 stage 来计算所需要的 task,并将 task 提交到对应的 Worker。

pyspark
- 数据集
- access.log:第一列为网络标号,0表示2G和3G的网络,1为4G网络。用以过滤和去重
- words.txt: 关于python的英文文档介绍,用于实现计数和topk。
- bayes1.dat: 朴素贝叶斯输入数据,有四个天气维度决定一个人是否出行,四个维度分别是天气外观、温度、湿度、刮风,最后一个值是否出行。
- bayes2.dat: 朴素贝叶斯测试数据。
[kejun.he@spark36 ~]$ cat access.log0 12341234 www.baidu.com/s?wd=spark1 22113345 www.hulian.com1 332244 www.wanglian.com0 15558 www.zhice.com1 332244 www.wanglian.com1 999222 www.up.com1 999222 www.up.com1 999222 www.up.com[kejun.he@spark36 ~]$ cat bayes1.datsunny hot high FALSE nosunny hot high TRUE noovercast hot high FALSE yesrainy mild high FALSE yesrainy cool normal FALSE yesrainy cool normal TRUE noovercast cool normal TRUE yessunny mild high FALSE nosunny cool normal FALSE yesrainy mild normal FALSE yessunny mild normal TRUE yesovercast mild high TRUE yesovercast hot normal FALSE yesrainy mild high TRUE no[kejun.he@spark36 ~]$ cat bayes2.datsunny mild normal Truesunny hot high Falserainy cool high Trueovercast cool normal False[kejun.he@spark36 ~]$ hadoop fs -put access.log /user/kejun.he/input[kejun.he@spark36 ~]$ hadoop fs -put words.txt /user/kejun.he/input[kejun.he@spark36 ~]$ hadoop fs -put bayes1.dat /user/kejun.he/input[kejun.he@spark36 ~]$ hadoop fs -put bayes2.dat /user/kejun.he/input
过滤,去重及统计
在access.log中统计4G网络的不同用户访问次数。
>>> log=sc.textFile("file:///home/kejun.he/access.log")>>> log.collect()[u'0 12341234 www.baidu.com/s?wd=spark', u'1 22113345 www.hulian.com', u'1 332244 www.wanglian.com', u'0 15558 www.zhice.com', u'1 999221 www.up.com/s?blabla', u'1 332214 www.wanglian.com', u'1 999221 www.up.com', u'1 999222 www.up.com', u'1 999223 www.up.com']>>> filter_rdd=log.filter(lambda x:x.split(" ")[0]=="1") #导入数据>>> filter_rdd.collect()[u'1 22113345 www.hulian.com', u'1 332244 www.wanglian.com', u'1 999221 www.up.com/s?blabla', u'1 332214 www.wanglian.com', u'1 999221 www.up.com', u'1 999222 www.up.com', u'1 999223 www.up.com']>>> import re>>> map_rdd=filter_rdd.map(lambda x:" ".join([x.split(" ")[1],re.compile("/.*").sub("",x.split(" ")[2])]))#数据转换:1去除网络标记号,2.保留站点信息>>> map_rdd.collect()[u'22113345 www.hulian.com', u'332244 www.wanglian.com', u'999221 www.up.com', u'332214 www.wanglian.com', u'999221 www.up.com', u'999222 www.up.com', u'999223 www.up.com']>>> revert_rdd=map_rdd.map(lambda x:(x.split(" ")[1],x.split(" ")[0])) #数据转换,形成<网站,用户>的key-value对>>> revert_rdd.collect()[(u'www.hulian.com', u'22113345'), (u'www.wanglian.com', u'332244'), (u'www.up.com', u'999221'), (u'www.wanglian.com', u'332214'), (u'www.up.com', u'999221'), (u'www.up.com', u'999222'), (u'www.up.com', u'999223')]>>> distinct_rdd=revert_rdd.distinct() #去重>>> distinct_rdd.collect()[(u'www.hulian.com', u'22113345'), (u'www.up.com', u'999222'), (u'www.wanglian.com', u'332214'), (u'www.up.com', u'999221'), (u'www.up.com', u'999223'), (u'www.wanglian.com', u'332244')]>>> set_one_rdd=distinct_rdd.mapValues(lambda x:1) #去除用户信息>>> set_one_rdd.collect()[(u'www.hulian.com', 1), (u'www.up.com', 1), (u'www.wanglian.com', 1), (u'www.up.com', 1), (u'www.up.com', 1), (u'www.wanglian.com', 1)]>>> from operator import add>>> reduce_rdd=set_one_rdd.reduceByKey(add)#统计次数>>> reduce_rdd.collect()[(u'www.up.com', 3), (u'www.hulian.com', 1), (u'www.wanglian.com', 2)]>>> reduce_rdd.saveAsTextFile("output") #保存统计结果
相关计数
与之前的Spark环境安装 实现的简单计数有区别,相关计数是计算两个或多个实体以一定方式共同出现的次数或者概率,在数据挖掘的领域中,我们也称为co-occurance。这个工作将切换到python文件运行的模式,不在pyspark下使用。
运算的步骤如下:
- 获取每一行的文本数据
- 对该行数据进行文本清洗
- 清洗后进行转换关联,并形成key-value对
- reduce统计
from pyspark import SparkContextfrom operator import addimport reprint ("start doing ###############")sc=SparkContext("spark://spark36.localdomain:7077","myApp")naive_words=sc.textFile("hdfs:///user/kejun.he/input/words.txt").cache()words_rdd=naive_words.map(lambda str1: str1.replace("."," ").replace(","," ").replace("("," ").replace(")"," ").replace("-"," ").replace(":"," ").split(" ")).cache()#print words_rdd.collect()def cut_words(x):l=len(x)i=0while(i<l-1):if is_valid(x[i]) and is_valid(x[i+1]):yield ((x[i],x[i+1]),1)i+=1def is_valid(ch):match=re.search('^[a-zA-Z1-9]+$', ch)if match:return Trueelse:return Falsetransform_rdd=words_rdd.flatMap(cut_words)#print transform_rdd.collect()count_result=transform_rdd.reduceByKey(add)sorted_result=count_result.sortBy(lambda x:x[1])#print (sorted_result.collect())sorted_result.repartition(1).saveAsTextFile("count_co_occurance")
朴素贝叶斯
Spark学习笔记的更多相关文章
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- Spark学习笔记——读写Hbase
1.首先在Hbase中建立一张表,名字为student 参考 Hbase学习笔记——基本CRUD操作 一个cell的值,取决于Row,Column family,Column Qualifier和Ti ...
随机推荐
- (NO.00003)iOS游戏简单的机器人投射游戏成形记(二十)
接上一篇文章,我们现在来实现篮框的感应器. 所谓感应器,就是在物体接触到的时候做出反应的节点.我们需要将感应器放在篮框底部,这样子弹接触感应器的时候,我们就知道子弹坠入了篮框,从而得分. 为了放置子弹 ...
- 设计模式之——工厂模式(A)
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/41085085 昨天看完了工厂模式,觉得在开发的过程中好多地 ...
- Swift的基础之UILabel控件
对于UILabel的相关内容,其他控件可以相似创建 //设置全局变量,将下面的 let 去掉,然后替换即可 //var myLabel = UILabel(); //系统生成的view ...
- 【Java编程】Java中的字符串匹配
在Java中,字符串的匹配可以使用下面两种方法: 1.使用正则表达式判断字符串匹配 2.使用Pattern类和Matcher类判断字符串匹配 正则表达式的字符串匹配: ...
- HADOOP中的CRC数据校验文件
Hadoop系统为了保证数据的一致性,会对文件生成相应的校验文件(.crc文件),并在读写的时候进行校验,确保数据的准确性.在本地find -name *.crc -print 看 比如我们遇到的这个 ...
- Windows系统版本判定那些事儿
v:* { } o:* { } w:* { } .shape { }p.MsoNormal,li.MsoNormal,div.MsoNormal { margin: 0cm; margin-botto ...
- Oracle EBS ERP中月结年结的流程总结
月结与年结处理,是企业财务比较特殊而重要的业务操作.在实施与推广OracleERP系统过程中,如何结合现行的会计制度与惯例,充分利用软件功能,做好相应的关账.开账工作,是困扰许多企业财务人员乃至实施顾 ...
- 实战项目开发细节:C语言分离一个16进制数取出相应的位1或0
最近在公司开发一个关于钢琴的PCBA项目,项目大概是这样的,完成各种功能的测试,准备去工厂量产的时候可以通过软件快速甄别硬件是否短路,断路等问题. 其中,甄别好坏的方法是通过比如按键,或者其它的操作然 ...
- 如何修改linux开机运行配置脚本
开机运行级别的配置角本 /etc/inittab 开机运行级别 init 是切换运行级别的指令 0.关机 //init0 1.单用户模式(自动获取超级用户权限,无网络,无服 ...
- Leetocde_290_Word Pattern
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/49717803 Given a pattern and a ...