Yarn 的日志聚集功能配置使用
需要 hadoop 的安装目录/etc/hadoop/yarn-site.xml 中进行配置
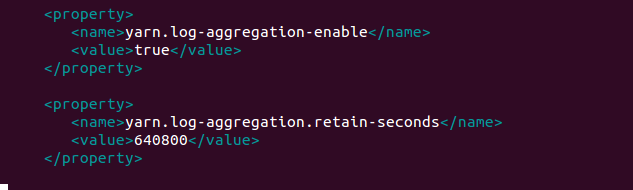
配置内容
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
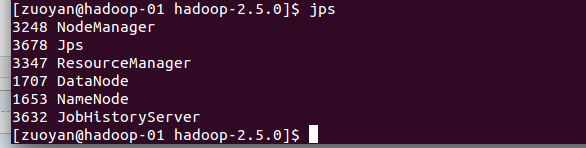
配置好了之后 需要重新启动 nodemanager resourcemanager historyserver 才可以生效
重新启动之后,在Hadoop上面使用yarn 运行wordcount程序
命令:
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/zuoyan/mapreduce/wordcount/input/ /user/zuoyan/mapreduce/wordcount/output2
打开Hadoop的任务管理界面的日志信息
就可以看到,日志已经可以打印出来了
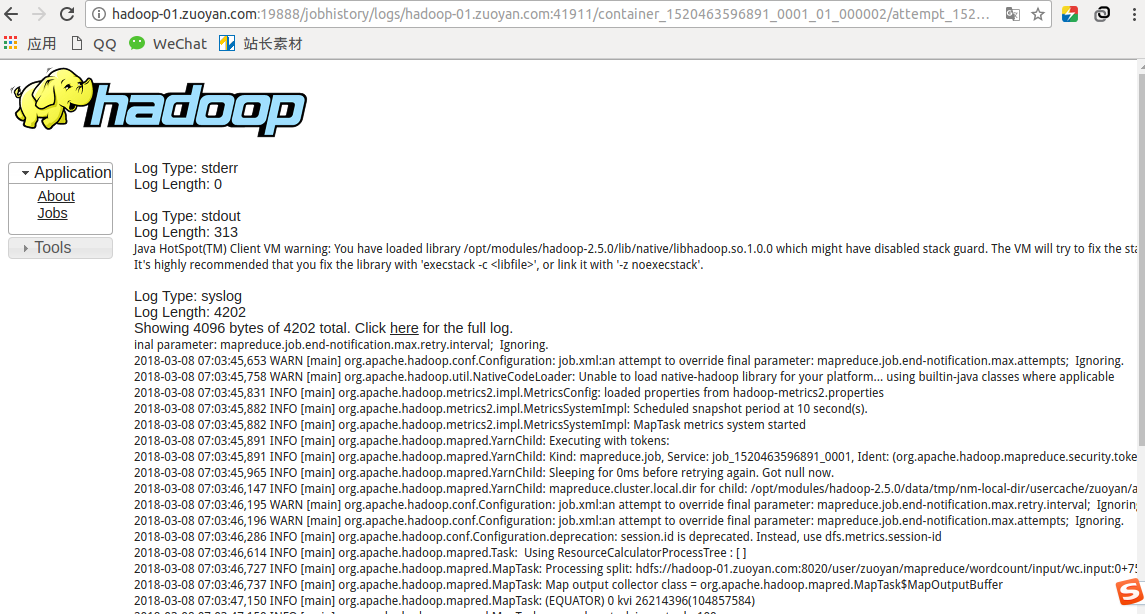
使用这种的好处 省去了以后去找日志信息查看的麻烦问题,能够比较直观的查看到错误信息!
这样Yarn的日志聚集功能就已经配置好了!
Yarn 的日志聚集功能配置使用的更多相关文章
- Hadoop基础-完全分布式模式部署yarn日志聚集功能
Hadoop基础-完全分布式模式部署yarn日志聚集功能 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 其实我们不用配置也可以在服务器后台通过命令行的形式查看相应的日志,但为了更方 ...
- hadoop 3.x 配置日志聚集功能
打开$HADOOP_HOME/etc/hadoop/yarn-site.xml,增加以下配置(在此配置文件中尽量不要使用中文注释) <!--logs--> <property> ...
- 启用yarn日志聚集功能
在yarn-site.xml配置文件中添加如下内容: ##开启日志聚集功能 <property> <name>yarn.log-ag ...
- 开启spark日志聚集功能
spark监控应用方式: 1)在运行过程中可以通过web Ui:4040端口进行监控 2)任务运行完成想要监控spark,需要启动日志聚集功能 开启日志聚集功能方法: 编辑conf/spark-env ...
- hadoop配置历史服务器&&配置日志聚集
配置历史服务器 1.在mapred-site.xml中写入一下配置 <property> <name>mapreduce.jobhistory.address</name ...
- 【原创】大叔经验分享(47)yarn开启日志归集
yarn开启日志归集功能,除了配置之外 yarn.log-aggregation-enable=true 还要检查/tmp/logs目录是否存在以及权限,尤其是在开启kerberos之后,有些目录可能 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- 如何在 ETL 项目中统一管理上百个 SSIS 包的日志和包配置框架
一直准备写这么一篇有关 SSIS 日志系统的文章,但是发现很难一次写的很完整.因为这篇文章的内容可扩展的性太强,每多扩展一部分就意味着需要更多代码,示例和理论支撑.因此,我选择我觉得比较通用的 LOG ...
- springmvc 项目完整示例05 日志 --log4j整合 配置 log4j属性设置 log4j 配置文件 log4j应用
log4j 就是log for java嘛,老外都喜欢这样子,比如那个I18n ---internationalization 不就是i和n之间有18个字母... http://logging.a ...
随机推荐
- Python 第四阶段 学习记录之----多线程
多线程 多线程例子, 注释部份即为多线程的使用 #-*- coding: utf-8 -*- # Wind clear raise # 2017/3/5 下午2:34 import socket im ...
- 怎么查 ODBC Driver for SQL Server
1)进入服务器,找到SQL Server 2016 Configuration... ,点进去就好了 2)
- Sqoop与HDFS、Hive、Hbase等系统的数据同步操作
Sqoop与HDFS结合 下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出. Sqoop import 它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示. 我们来 ...
- Python HTMLTestRunner 学习
HTMLTestRunner 是 基于 unittest 单元测试的 HTML报告 的一个第三库 安装: 1. 安装:下载HTMLTestRunner.py文件:地址http://tungwaiy ...
- GoldenGate for bigdata 12.3.1.1
GoldenGate for big data 12.3.1.1在8.18已经发布,主要新特性如下: 1. 新目标:Amazon Kinesis 2. 新目标:使用Kafka Connect API及 ...
- 数据库 SQL 优化大总结之:百万级数据库优化方案
网上关于SQL优化的教程很多,但是比较杂乱.近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充. 这篇文章我花费了大量的时间查找资料.修改.排版,希望大家阅读之后,感觉 ...
- 【js】手机浏览器端唤起app,没有app就去下载app 的方法
这种功能的作用: 1.一般公司有自己的app,而app是需要不断有新用户涌入才能持续运营,达到不错的收入.就需要使用这种方式进行引入新的用户. 2.一些内容在网页端体验不好,或者一些功能需要app内才 ...
- xtrabackup 对pxc节点进行备份恢复
xtrabackup 对pxc节点进行备份恢复 全量备份一个节点的数据,当节点挂掉时,使用备份恢复到最近状态,再启动节点加入集群. 备份 xtrabackup 命令小解释: --defaults-fi ...
- Prometheus监控学习笔记之Prometheus存储
0x00 概述 Prometheus之于kubernetes(监控领域),如kubernetes之于容器编排.随着heapster不再开发和维护以及influxdb 集群方案不再开源,heapster ...
- Linux学习笔记之yum安装和卸载软件
# yum -y install 包名(支持*) :自动选择y,全自动 # yum install 包名(支持*) :手动选择y or n # yum remove 包名(不支持*) # rpm -i ...