python中url解析 or url的base64编码
目录
from urllib.parse import urlparse, quote, unquote, urlencode
1、解析url的组成成分:urlparse(url)
2、url的base64编解码:quote(url)、unquote(url)
3、字典变成一个字符串=&连接,并且被base64编码:urlencode(字典)
from urllib.parse import urlparse, quote, unquote, urlencode
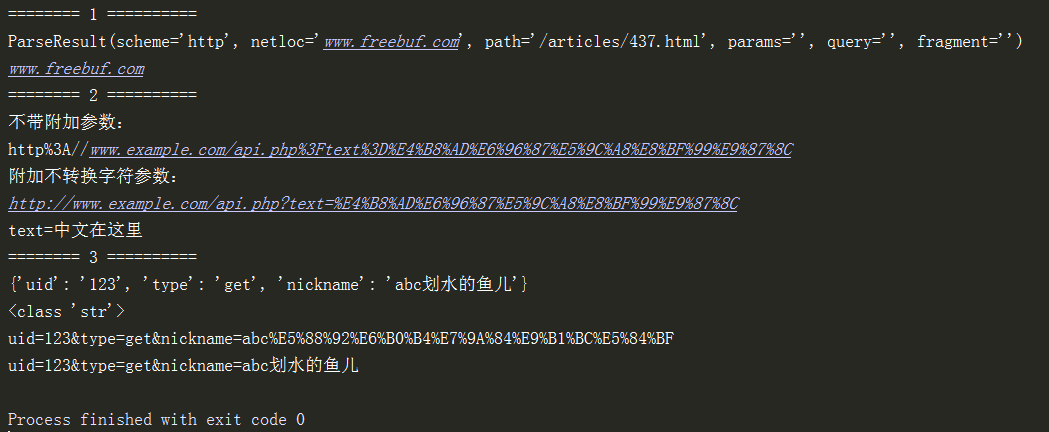
print("======== 1 解析url的组成==========")
url='http://www.freebuf.com/articles/437.html'
url_parse = urlparse(url)
print(url_parse)
print(url_parse.netloc)
print("======== 2 对字符串进行base64编码和反编码==========")
url = 'http://www.example.com/api.php?text=中文在这里'
# 不带附加参数
print('不带附加参数:\n%s' % quote(url))
# 附带不转换字符参数
print('附加不转换字符参数:\n%s' % quote(url, safe='/:?='))
print(unquote("text%3D%E4%B8%AD%E6%96%87%E5%9C%A8%E8%BF%99%E9%87%8C"))
print("======== 3 对字典转换为=&连接的字符串,并且base64编码==========")
params = {
"uid": "123",
"type": "get",
"nickname": "abc划水的鱼儿",
}
print(params)
data_str_base64 = urlencode(params) # 字典转为字符串,并且base64编码
print(type(data_str_base64))
print(data_str_base64)
data_str_unbase64 = unquote(data_str_base64) # 字符串中base64被反解码
print(data_str_unbase64)
输出结果:
到此看懂了,后面就可以不用看了。
1、解析url的组成成分:urlparse(url)
提取域名domain
from urllib.parse import urlparse url = 'http://www.freebuf.com/articles/437.html'
url_parse = urlparse(url)
print(url_parse)
print(url_parse.netloc)
print(url_parse.hostname)
输出:
ParseResult(scheme='http', netloc='www.freebuf.com', path='/articles/437.html', params='', query='', fragment='')
www.freebuf.com
www.freebuf.com
2、url的base64编解码:quote(url)、unquote(url)
url的base64编码 、解码
from urllib.parse import quote
url = 'http://www.example.com/api.php?text=中文在这里' # 不带附加参数
print('\n不带附加参数:\n%s' % quote(url)) # 附带不转换字符参数
print('\n附加不转换字符参数:\n%s' % quote(url, safe='/:?='))
输出结果:

base64解码
print(unquote("text%3D%E4%B8%AD%E6%96%87%E5%9C%A8%E8%BF%99%E9%87%8C"))
(一)字符串转义为base64编码和解码(和上文重复,不用看)
import urllib.parse url_han = 'https://www.baidu.com/s?wd=北京'
print(urllib.parse.quote(url_han)) # base64编码
# https%3A//www.baidu.com/s%3Fwd%3D%E5%8C%97%E4%BA%AC url_base64 = 'https://www.baidu.com/s?wd=%E6%B7%B1%E5%9C%B3'
print(urllib.parse.unquote(url_base64)) # base64反编码
# https://www.baidu.com/s?wd=深圳
3、字典变成一个字符串=&连接,并且被base64编码
(二)字典转化为&连接的字符串
说明:字典转字符串后,发生了2件事
1、冒号变成等号;逗号变成&
2、汉字和特殊字符被base64编码
案例:
源代码:
import urllib.parse
params = {
"uid": "123",
"type": "get",
"nickname": "abc划水的鱼儿",
}
print(params)
data_str_base64 = urllib.parse.urlencode(params) # 字典转为字符串,并且base64编码
print(type(data_str_base64))
print(data_str_base64)
data_str_unbase64 = urllib.parse.unquote(data_str_base64) # 字符串中base64被反解码
print(data_str_unbase64)
输出结果:
{'uid': '123', 'type': 'get', 'nickname': 'abc划水的鱼儿'}
<class 'str'>
uid=123&type=get&nickname=abc%E5%88%92%E6%B0%B4%E7%9A%84%E9%B1%BC%E5%84%BF
uid=123&type=get&nickname=abc划水的鱼儿
python中url解析 or url的base64编码的更多相关文章
- python中html解析-Beautiful Soup
1. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- python中unicode、utf8、gbk等编码问题
转自:http://luchanghong.com/python/2012/07/06/python-encoding-with-unicode-and-gbk-and-utf8.html 概要:编码 ...
- Python中xlwt解析
1.导入模块 import xlwt 2.构造excel表 workbook = xlwt.Workbook() #返回一个工作簿对象 3.构造sheet w ...
- python中html解析
import requestsfrom bs4 import BeautifulSoup url = "..." payload =...headers = None respon ...
- Python中配置文件解析模块-ConfigParser
Python中有ConfigParser类,可以很方便的从配置文件中读取数据(如DB的配置,路径的配置).配置文件的格式是: []包含的叫section, section 下有option=value ...
- Python中yield解析
小探yield 查看 python yield 文档 yield expressions: Using a yield expression in a function's body causes t ...
- Python中xlutils解析
1.导入模块 import xlrd import xlutils.copy 2.打开模块表 book = xlrd.open_workbook('test.xls', formatting_info ...
- Python中Json解析的坑
JSON虽好,一点点不对,能把人折腾死: 1.变量必须要用双引号 2.如果是字符串,必须要用引号包起来 Error:Expecting : delimiter: line 1 column 6 (ch ...
- python中xml解析
import xml.dom.minidom input_xml_string = '''<root><a>hello</a></root>'''#打开 ...
随机推荐
- nginx介绍和安装
1.nginx的介绍 1.1 nginx的优势 1) 作为Web服务器,Nginx处理静态文件.索引文件,自动索引的效率非常高. 2) 作为代理服务器,Nginx可以实现无缓存的反向代理加速,提高网站 ...
- 纯css制作带三角(兼容所有浏览器)
如何用 border 来制作三角. html 代码如下: 代码如下: <div class="arrow-up"></div> <div class= ...
- jquery.gritter.js简介
Gritter 是一个小型的 jQuery 消息通知插件,通知效果如下图所示: 参考网
- 深入理解 Neutron -- OpenStack 网络实现(1):GRE 模式
问题导读1.什么是VETH.qvb.qvo?2.qbr的存在的作用是什么?3.router服务的作用是什么? 如果不具有Linux网络基础,比如防火墙如何过滤ip.端口或则对openstack ovs ...
- css - 文字元素等的美化效果代码汇总(更新中...)
投影的设置 -webkit-box-reflect: below 0px -webkit-gradient(linear, left top, left bottom, from(transparen ...
- shell中的环境变量:local,global,export
1.local一般用于局部变量声明,多在在函数内部使用.实例如下: echo_start() { local STR="$1" echo "...... ${ ...
- 【转】Navigation Drawer(导航抽屉)
创建一个导航抽屉 创建抽屉布局 初始化抽屉列表 处理导航项选点击事件 监听导航抽屉打开和关闭事件 点击应用图标来打开和关闭导航抽屉 创建一个导航抽屉 导航抽屉是一个位于屏幕左侧边缘用来显示应用程序 ...
- .NET中字符串split的C++实现
void CustomVersion::split(const string &s, char delim, vector<string> &elems){ istring ...
- 【CF819D】Mister B and Astronomers EXGCD
[CF819D]Mister B and Astronomers 题意:小鼠Jack想当太空人(哦不,太空鼠)!为此,它在夜晚带领一堆小朋友一起来到户外看星星.一共有 $n$ 只小鼠,这些小鼠围成一 ...
- Express 4.x Node.js的Web框架----《转载》
本文使用node.js v0.10.28 + express 4.2.0 1 Express概述 Express 是一个简洁而灵活的node.js的MVC Web应用框架,提供一系列强大特性创建各种W ...