入门大数据---通过Yarn搭建MapReduce和应用实例
上一篇中我们了解了MapReduce和Yarn的基本概念,接下来带领大家搭建下Mapreduce-HA的框架。
结构图如下:
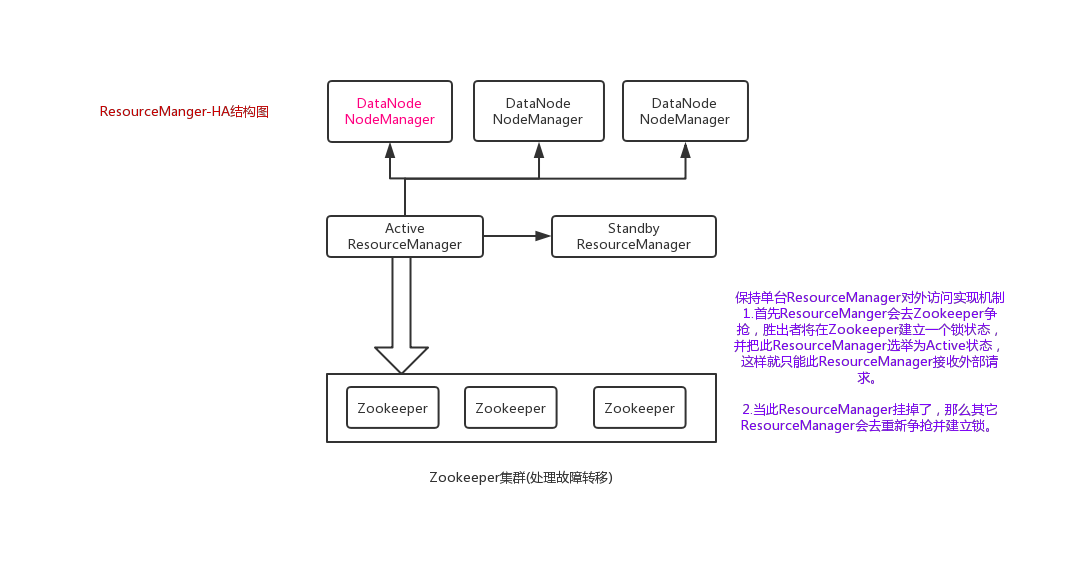
开始搭建:
一.配置环境
注:可以现在一台计算机上进行配置,然后分发给其它服务器
1.1 编辑mapred-site.xml文件:
进入目录 /opt/hadoop/hadoop-2.6.5/etc/hadoop
cd /opt/hadoop/hadoop-2.6.5/etc/hadoop
vim mapred-site.xml
添加如下配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> <!--指定mapreduce通过yarn获取数据,还可以填写参数localhost-->
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
1.2 编辑yarn-site.xml文件:
vim yarn-site.xml
添加如下配置:
<configuratoin>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> <!--指定nodemanager可以拉取数据-->
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value><!--启动resourcemanager高可用-->
</property>
<property>
<name>hadoop.zk.address</name><!--配置zookeeper地址-->
<value>tuge1:2181,tuge2:2181,tuge3:2181,tuge4:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value><!--配置resourcemanager虚拟地址到物理地址的映射-->
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>tuge1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>tuge2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>tuge1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>tuge2:8088</value>
</property>
</configuration>
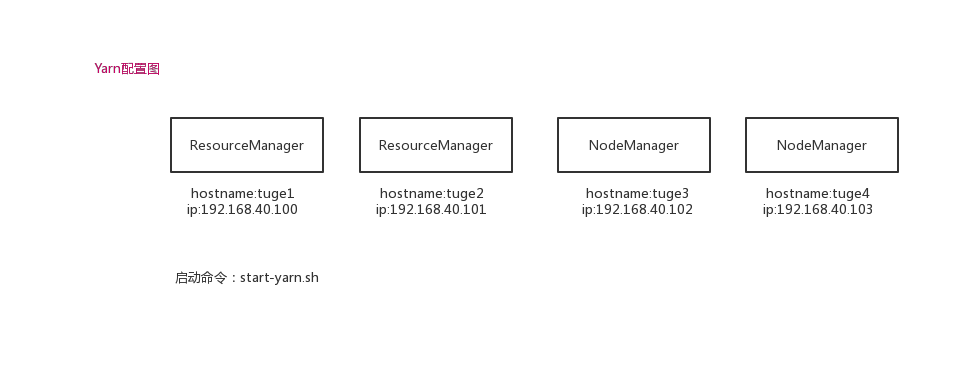
二.启动程序
在tuge1服务器启动:
cd /opt/hadoop/hadoop-2.6.5/sbin
start-yarn.sh
启动后,使用jps即可查看resourcemanager和nodemanager是否启动成功。
三.浏览效果
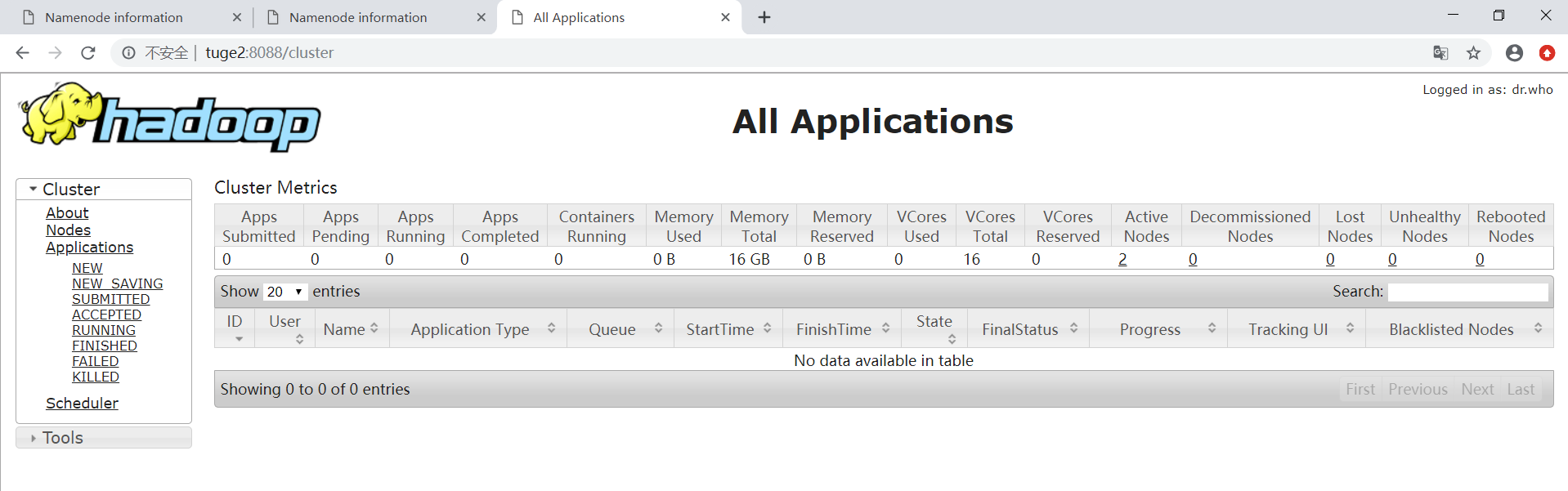
四.实现一个计算Demo
4.1 在hdfs里面创建一个10000行的test.txt文件
使用命令:
//首先创建一个root文件夹
hadoop fs -mkdir /user/root/
//在linux随便找一个目录创建一个文件,并加入1万行What are you doing 123?
touch test.txt
vim test.txt
然后输入数字10000,再点击i进行输入What are you doing 123? ,然后按Esc 这时10000行What are you doing 123?就录入了,然后保存。
//将本地文件复制到hdfs上面
hadoop dfs -scpFromLocal test.txt /user/root/
4.2 进入/opt/hadoop/hadoop-2.6.5/share/hadoop/mapreduce
cd /opt/hadoop/hadoop-2.6.5/share/hadoop/mapreduce
4.3 使用mapreduce统计刚刚上传文件里面的单词数量
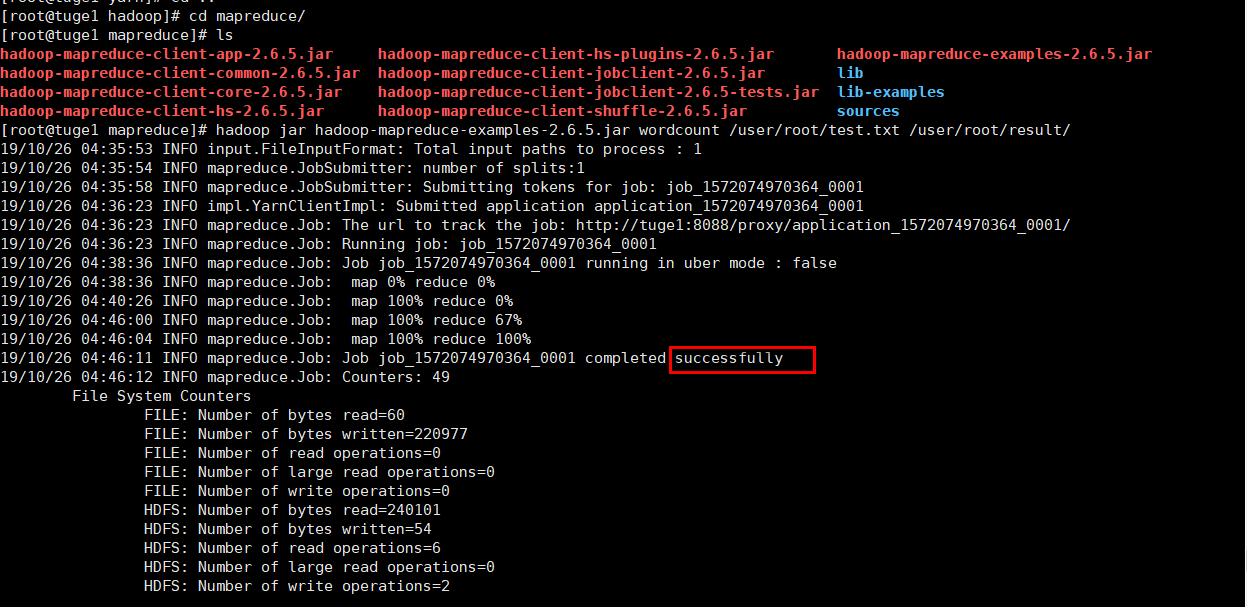
hadoop jar hadoop-mapreduce-examples-2.6.5.jar /user/root/test.txt /user/root/result --意思是使用hadoop 运行jar环境,并执行程序,统计的文件路径,输出结果路径(这个路径必须是空的或者不存在的)
4.4 控制台执行效果图和web ui浏览效果图
4.5 最后我们可以在上面的输出目录查看统计结果
hadoop fs -cat /user/root/result/part-r-00000
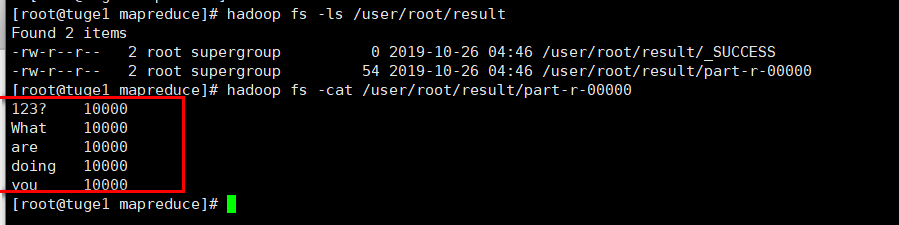
从上图可以看到,每个单词统计均为10000,那么就证明我们搭建成功啦~
入门大数据---通过Yarn搭建MapReduce和应用实例的更多相关文章
- 入门大数据---Hive的搭建
本博客主要介绍Hive和MySql的搭建: 学习视频一天就讲完了,我看完了自己搭建MySql遇到了一堆坑,然后花了快两天才解决完,终于把MySql搭建好了.然后又去搭建Hive,又遇到了很多坑,就这 ...
- 入门大数据---Kafka的搭建与应用
前言 上一章介绍了Kafka是什么,这章就讲讲怎么搭建以及如何使用. 快速开始 Step 1:Download the code Download the 2.4.1 release and un-t ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 入门大数据---Flume的搭建
一.下载并解压到指定目录 崇尚授人以渔的思想,我说给大家怎么下载就行了,就不直接放连接了,大家可以直接输入官网地址 http://flume.apache.org ,一般在官网的上方或者左边都会有Do ...
- Ambari——大数据平台的搭建利器之进阶篇
前言 本文适合已经初步了解 Ambari 的读者.对 Ambari 的基础知识,以及 Ambari 的安装步骤还不清楚的读者,可以先阅读基础篇文章<Ambari——大数据平台的搭建利器>. ...
- 我眼中的大数据(三)——MapReduce
这次来聊聊Hadoop中使用广泛的分布式计算方案--MapReduce.MapReduce是一种编程模型,还是一个分布式计算框架. MapReduce作为一种编程模型功能强大,使用简单.运算内容不 ...
- 大数据应用日志采集之Scribe演示实例完全解析
大数据应用日志采集之Scribe演示实例完全解析 引子: Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它能够从各种日志源上收集日志,存储到一个中央存储系 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
随机推荐
- (Java实现) 组合的输出
问题 B: [递归入门]组合的输出 时间限制: 1 Sec 内存限制: 128 MB 题目描述 排列与组合是常用的数学方法,其中组合就是从n个元素中抽出r个元素(不分顺序且r < = n),我们 ...
- C# winform 学习(一)
目标 1.类和对象 2.定义类 3.对象的操作 4.命名空间 一.类和对象 1.理解 1)类:具有共同特征和行为的一类事物的统称 2)对象:类的一个具体唯一的实例 eg: 1路公交车;(类) 车牌为F ...
- Java实现 LeetCode 309 最佳买卖股票时机含冷冻期
309. 最佳买卖股票时机含冷冻期 给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 . 设计一个算法计算出最大利润.在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股 ...
- java中ReentrantLock类的详细介绍(详解)
博主如果看到请联系小白,小白记不清地址了 简介 ReentrantLock是一个可重入且独占式的锁,它具有与使用synchronized监视器锁相同的基本行为和语义,但与synchronized关键字 ...
- java实现矩阵变换加密法
一种Playfair密码变种加密方法如下:首先选择一个密钥单词(称为pair)(字母不重复,且都为小写字母),然后与字母表中其他字母一起填入至一个5x5的方阵中,填入方法如下: 1.首先按行填入密钥串 ...
- java实现取球游戏
/* 今盒子里有 n 个小球,A.B 两人轮流从盒中取球,每个人都可以看到另一个人取了多少个, 也可以看到盒中还剩下多少个,并且两人都很聪明,不会做出错误的判断. 我们约定: 每个人从盒子中取出的球的 ...
- 分布式锁没那么难,手把手教你实现 Redis 分布锁!|保姆级教程
书接上文 上篇文章「MySQL 可重复读,差点就让我背上了一个 P0 事故!」发布之后,收到很多小伙伴们的留言,从中又学习到很多,总结一下. 上篇文章可能举得例子有点不恰当,导致有些小伙伴没看懂为什么 ...
- Cookie默认不设置path时,哪些请求会携带cookie数据
默认不设置path的时候,只会在请求和servlet同路径的情况下才会携带cookie中存储的数据,包含同级目录和下级目录 例如: 在http://localhost:8080/day01/test/ ...
- sublime配置C++编译环境
配置C++编译命令 { "file_regex": "^(..[^:]*):([0-9]+):?([0-9]+)?:? (.*)$", "workin ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...