【Hadoop离线基础总结】Apache Hadoop的三种运行环境介绍及standAlone环境搭建
Apache Hadoop的三种运行环境介绍及standAlone环境搭建
三种运行环境
- standAlone环境
单机版的hadoop运行环境 - 伪分布式环境
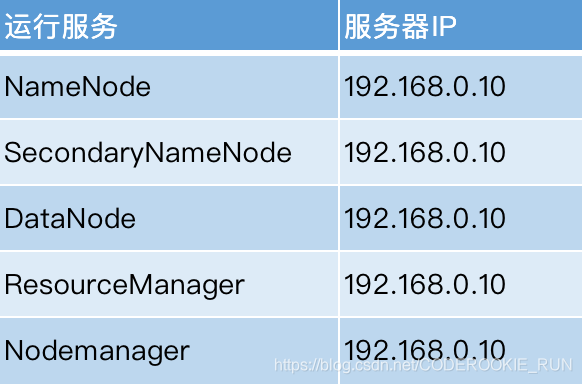
主节点都在一台机器上,从节点分开到其他机器上(可以借助三台机器来实现) - 完全分布式环境
主节点全部分散到不同机器上(NameNode Active,NameNode StandBy,ResourceManager 主节点,ResourceManager 备份节点)
standAlone环境搭建
- 第一步:下载apache hadoop并上传到服务器
下载链接:http://archive.apache.org/dist/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz
上传到/export/softwares/,并解压到/export/servers/
tar -zxvf hadoop-2.7.5.tar.gz -C /export/servers/
Hadoop的本地库:/export/servers/hadoop-2.7.5/lib/native
(很重要,里面集成了一些C程序,包括了一些压缩的支持)
bin/hadoop checknative 检测本地库的支持

- 第二步:修改配置文件
cd /export/servers/hadoop-2.7.5/etc/hadoop
修改core-site.xml(核心配置文件,主要定义了我们的集群是分布式,还是本机运行)
vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.0.10:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.5/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
修改hdfs-site.xml(分布式文件系统的核心配置,决定了我们数据存放在哪个路径,数据的副本,数据的block块大小)
vim hdfs-site.xml
<configuration>
<!-- NameNode存储元数据信息的路径,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<!-- 集群动态上下线
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.7.4/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/export/servers/hadoop-2.7.4/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
修改hadoop-env.sh(配置我们jdk的home路径)
vim hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改mapred-site.xml(定义了我们关于mapreduce运行的一些参数)
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
</configuration>
修改yarn-site.xml(定义我们的yarn集群)
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
修改slaves(定义了我们的从节点是哪些机器,也就是DataNode和NodeManager运行在哪些机器上)
vim slaves
node01
- 第三步:启动集群
要启动Hadoop集群,需要启动HDFS和YARN两个模块
注意:首次启动HDFS时,必须对其进行格式化操作,本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的
hdfs namenode -format或者hadoop namenode -format
启动命令:
创建数据存放文件夹,在第一台机器执行
cd /export/servers/hadoop-2.7.5/
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
准备启动:
cd /export/servers/hadoop-2.7.5/
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
tips
HDFS集群查看界面:node01:50070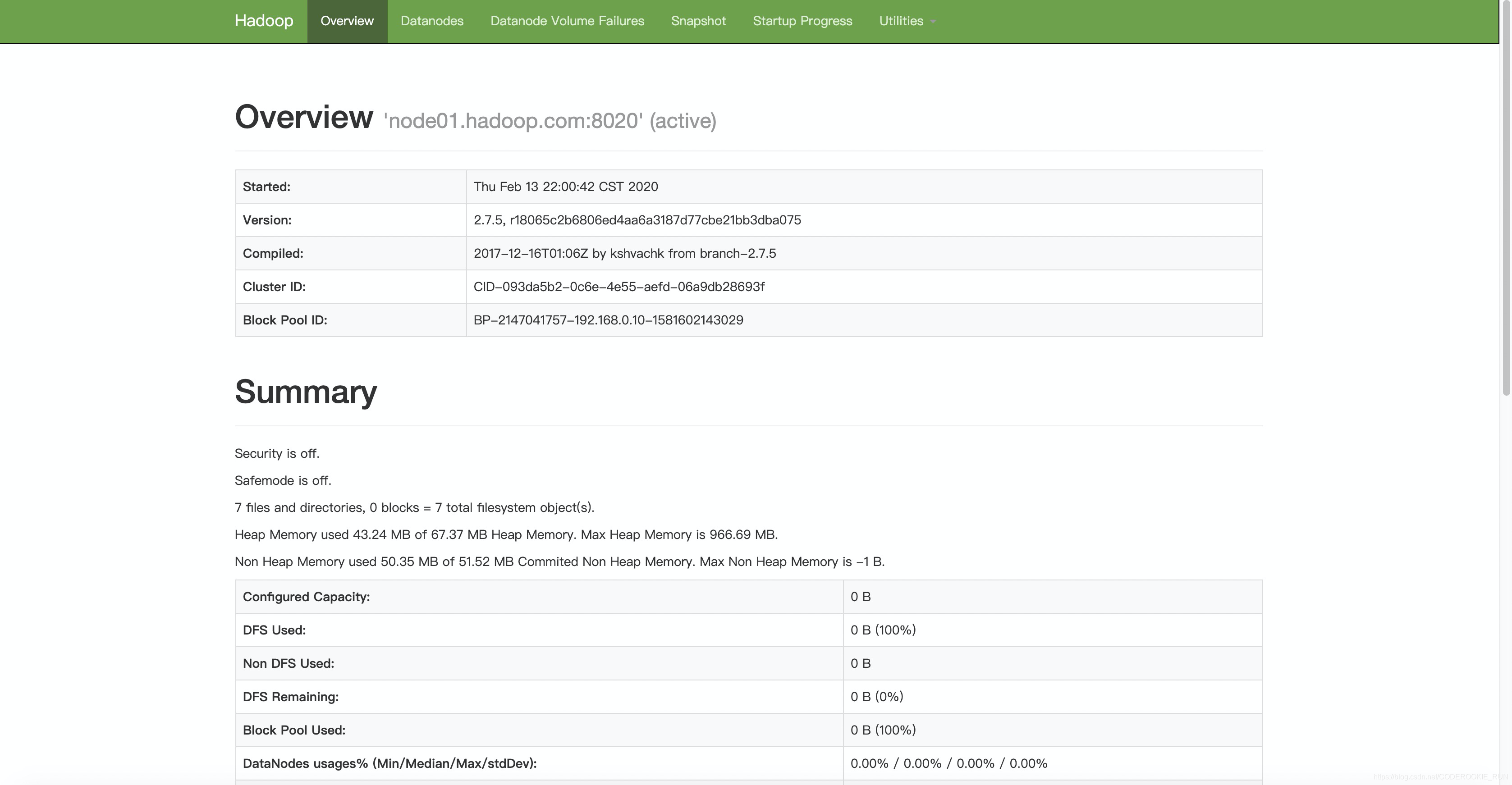
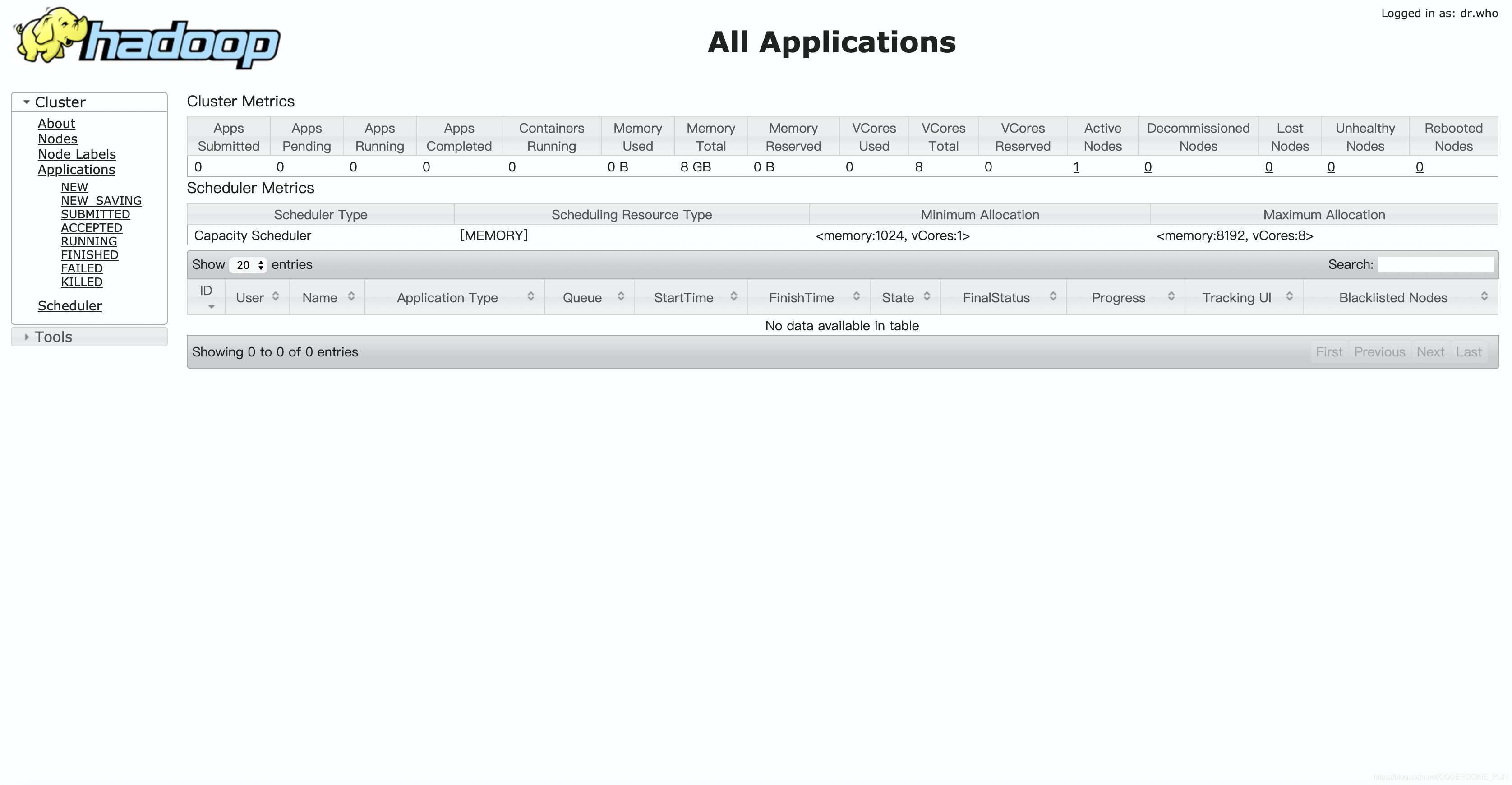
Yarn集群查看界面:node01:8088
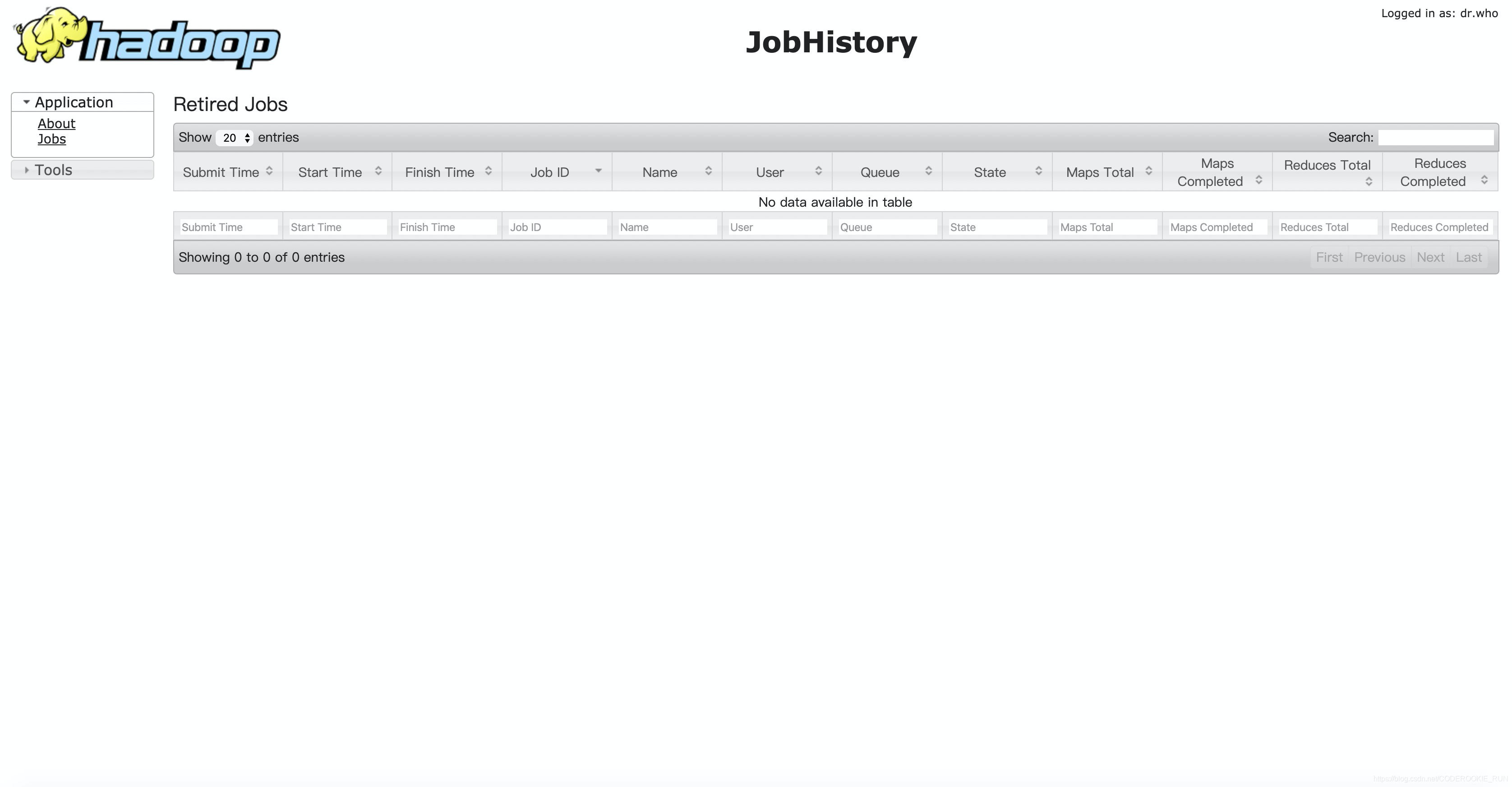
历史任务完成界面:node01:19888
【Hadoop离线基础总结】Apache Hadoop的三种运行环境介绍及standAlone环境搭建的更多相关文章
- 【Hadoop离线基础总结】Hadoop High Availability\Hadoop基础环境增强
目录 简单介绍 Hadoop HA 概述 集群搭建规划 集群搭建 第一步:停止服务 第二步:启动所有节点的ZooKeeper 第三步:更改配置文件 第四步:启动服务 简单介绍 Hadoop HA 概述 ...
- 【Hadoop离线基础总结】Hadoop的架构模型
Hadoop的架构模型 1.x的版本架构模型介绍 架构图 HDFS分布式文件存储系统(典型的主从架构) NameNode:集群当中的主节点,主要用于维护集群当中的元数据信息,以及接受用户的请求,处理用 ...
- 【Hadoop离线基础总结】impala简单介绍及安装部署
目录 impala的简单介绍 概述 优点 缺点 impala和Hive的关系 impala如何和CDH一起工作 impala的架构及查询计划 impala/hive/spark 对比 impala的安 ...
- 【Hadoop离线基础总结】Hive调优手段
Hive调优手段 最常用的调优手段 Fetch抓取 MapJoin 分区裁剪 列裁剪 控制map个数以及reduce个数 JVM重用 数据压缩 Fetch的抓取 出现原因 Hive中对某些情况的查询不 ...
- 【Hadoop离线基础总结】流量日志分析网站整体架构模块开发
目录 数据仓库设计 维度建模概述 维度建模的三种模式 本项目中数据仓库的设计 ETL开发 创建ODS层数据表 导入ODS层数据 生成ODS层明细宽表 统计分析开发 流量分析 受访分析 访客visit分 ...
- 【Hadoop离线基础总结】MapReduce自定义InputFormat和OutputFormat案例
MapReduce自定义InputFormat和OutputFormat案例 自定义InputFormat 合并小文件 需求 无论hdfs还是mapreduce,存放小文件会占用元数据信息,白白浪费内 ...
- 【Hadoop离线基础总结】MapReduce入门
MapReduce入门 Mapreduce思想 概述 MapReduce的思想核心是分而治之,适用于大量复杂的任务处理场景(大规模数据处理场景). 最主要的特点就是把一个大的问题,划分成很多小的子问题 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- 【Hadoop离线基础总结】Hue的简单介绍和安装部署
目录 Hue的简单介绍 概述 核心功能 安装部署 下载Hue的压缩包并上传到linux解压 编译安装启动 启动Hue进程 hue与其他框架的集成 Hue与Hadoop集成 Hue与Hive集成 Hue ...
随机推荐
- Daily Scrum 1/7/2015
Process: Zhaoyang: Do some code intergration and test the total feature in the IOS APP. Yandong: Cod ...
- stand up meeting 11/16/2015
第一周,熟悉任务中~ 大致写下一天的工作: 冯晓云:熟悉bing接口,本意是调在线的必应词典API,参阅了大量C#调用API开发.net的工作,[约莫是因为有个窗口互动性更强,所以这样的工作更有趣,也 ...
- div3--C. Pipes
题目链接:https://codeforces.com/contest/1234/problem/C 题目大意:根据规则,判断是否可以从左上走到右下,1,2,3,4,5,6分别对应题干给的图片,所以1 ...
- Problem D. Ice Cream Tower
题解:二分加贪心,,,二分答案,然后进行判断,判断的时候,首先给每一组配一个最大的球,然后在向每一组里面填球,注意填球的时候要按组进行,每一组先填一个,然后更新每一组内的最小值,方便下一次寻找. #i ...
- Android | 教你如何在安卓上实现通用卡证识别,一键各种卡绑定
目录 前言 通用卡证识别的应用场景 如何使用通用卡证识别服务 集成通用卡证识别服务的关键流程 开发实战 1 开发准备 1.1 在项目级gradle里添加华为maven仓 1.2 在应用级的build. ...
- SQLi —— 逗号,空格,字段名过滤突破
前言 出于上海大学生网络安全大赛的一道easysql,促使我积累这篇文章.因为放了大部分时间在Decade和Babyt5上,easysql一点没看,事后看了WP,发现看不懂怎么回事,于是了解了一番. ...
- 解析网站爬取腾讯vip视频
今天用油猴脚本vip一件解析看神奇队长.想到了问题,这个页面应该是找到了视频的api的接口,通过接口调用获取到了视频的地址. 那自己找腾讯视频地址多费劲啊,现在越来越多的参数,眼花缭乱的. 那我就找到 ...
- JavaScript表达式和运算符 —— 基础语法(4)
JavaScript基础语法(4) 运算符 运算符用于将一 个或者多个值变成结果值. 使用运算符的值称为操作数,运算符和操作数的组合称为表达式 JS中的运算符可以分成下面几类: 算术运算符 逻辑运算符 ...
- iview使用之怎样通过render函数在tabs组件中添加标签
在实际项目开发中我们通常会遇到一些比较'新颖'的需求,而这时iview库里往往没有现成可用的组件示例,所以我们就需要自己动手翻阅IviewAPI进行自定义一些组件,也可以说是将iview库里的多种组件 ...
- tensorflow1.0 变量加法
import tensorflow as tf state = tf.Variable(0,name='counter') print(state.name) one = tf.constant(1) ...