【Hadoop离线基础总结】Hadoop的架构模型
Hadoop的架构模型
1.x的版本架构模型介绍
架构图
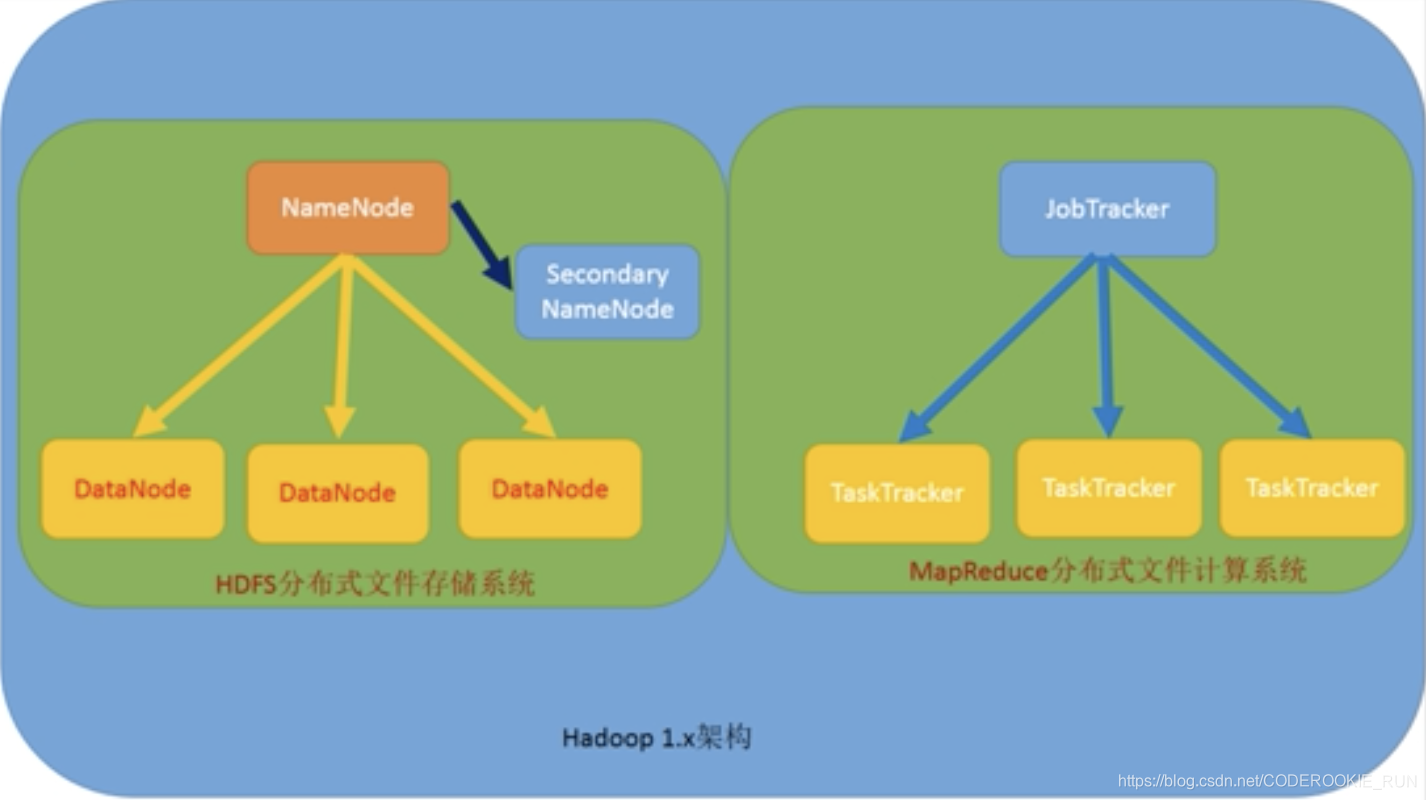
HDFS分布式文件存储系统(典型的主从架构)
NameNode:集群当中的主节点,主要用于维护集群当中的元数据信息,以及接受用户的请求,处理用户的请求
SecondaryNameNode:主要是辅助NameNode管理元数据信息
DataNode:集群当中的从节点,主要用于存储数据
什么是元数据?
元数据就是描述数据的数据。简单的来说,一个文件的存放位置、文件名称、打开方式、创建人、修改时间、文件大小、文件权限等这些都是描述性的数据,都可以称为元数据。拿到现实生活中来说,判断一个人是否是我们想要找到的人,他的样貌、身高、体型、穿着这些都是描述性的信息,也就是元数据。mapReduce分布式计算系统
JobTracker:主节点,接受用户请求,分配任务给taskTracker去执行
TaskTracker:从节点,主要用于接受jobTracker分配的任务
2.x的版本架构模型介绍
- 第一种:NameNode和ResourceManager单节点架构模型
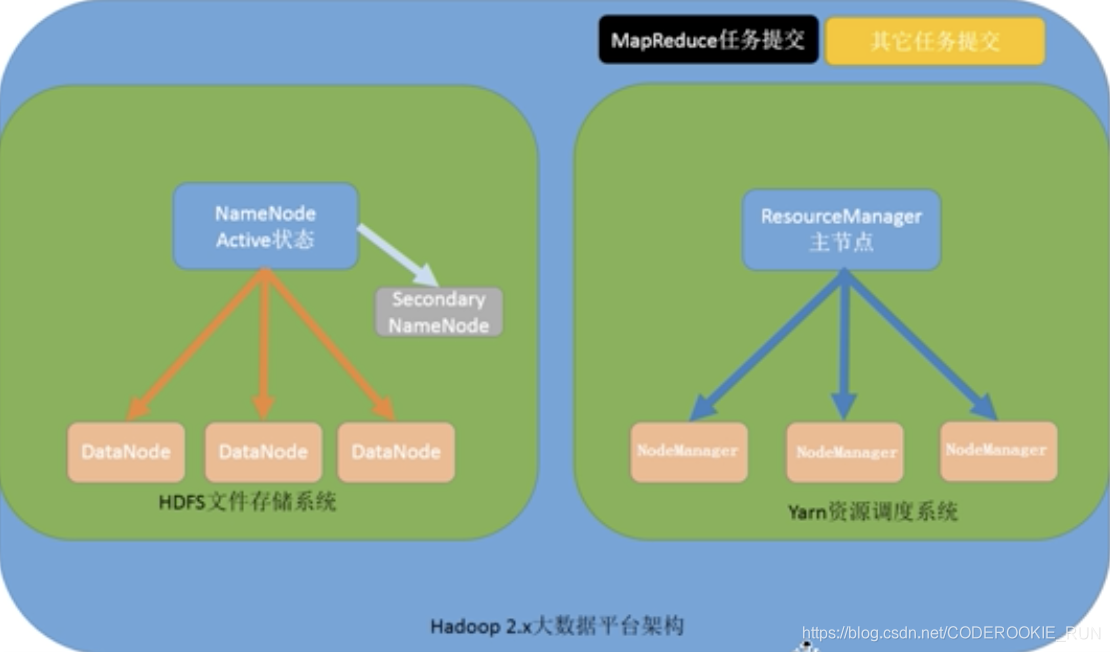
HDFS文件存储系统(典型的主从架构)
NameNode:集群当中的主节点,主要用于维护集群当中的元数据信息,以及接受用户的请求,处理用户的请求
SecondaryNameNode:主要是辅助NameNode管理元数据信息
DataNode:集群当中的从节点,主要用于存储数据
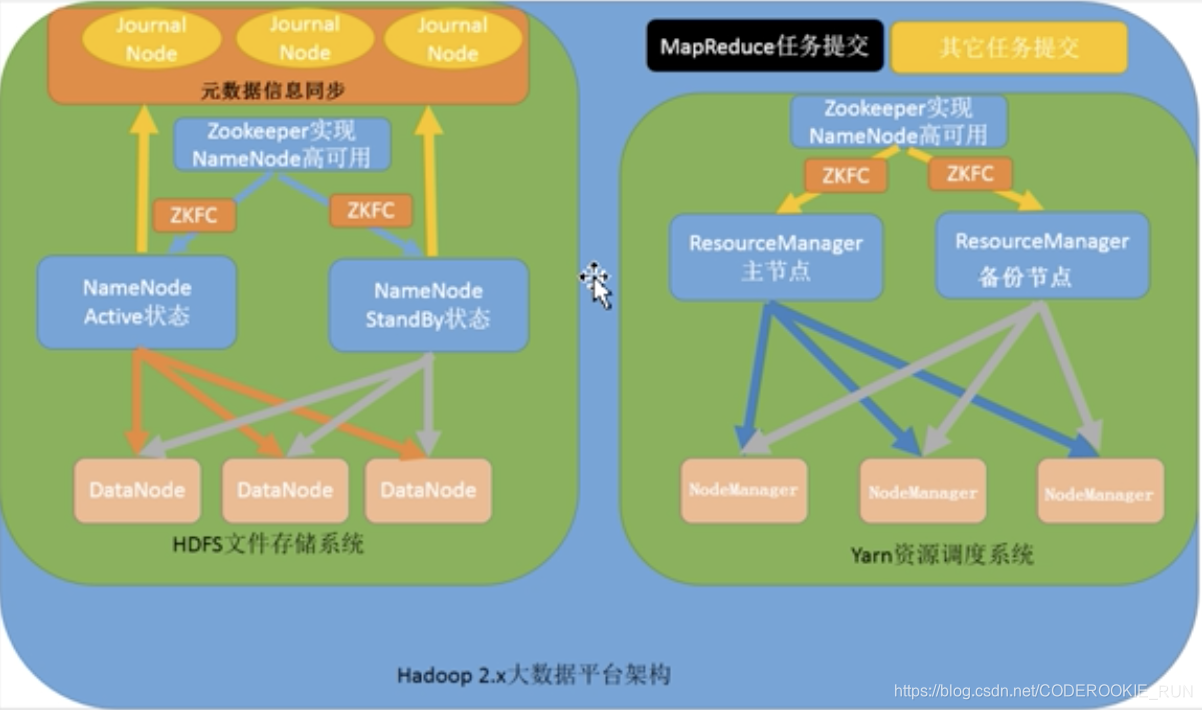
Yarn资源调度系统
ResourceManager:主节点,接受用户请求,分配资源(分配CPU、分配内存等)
NodeManager:从节点,主要用于处理计算任务
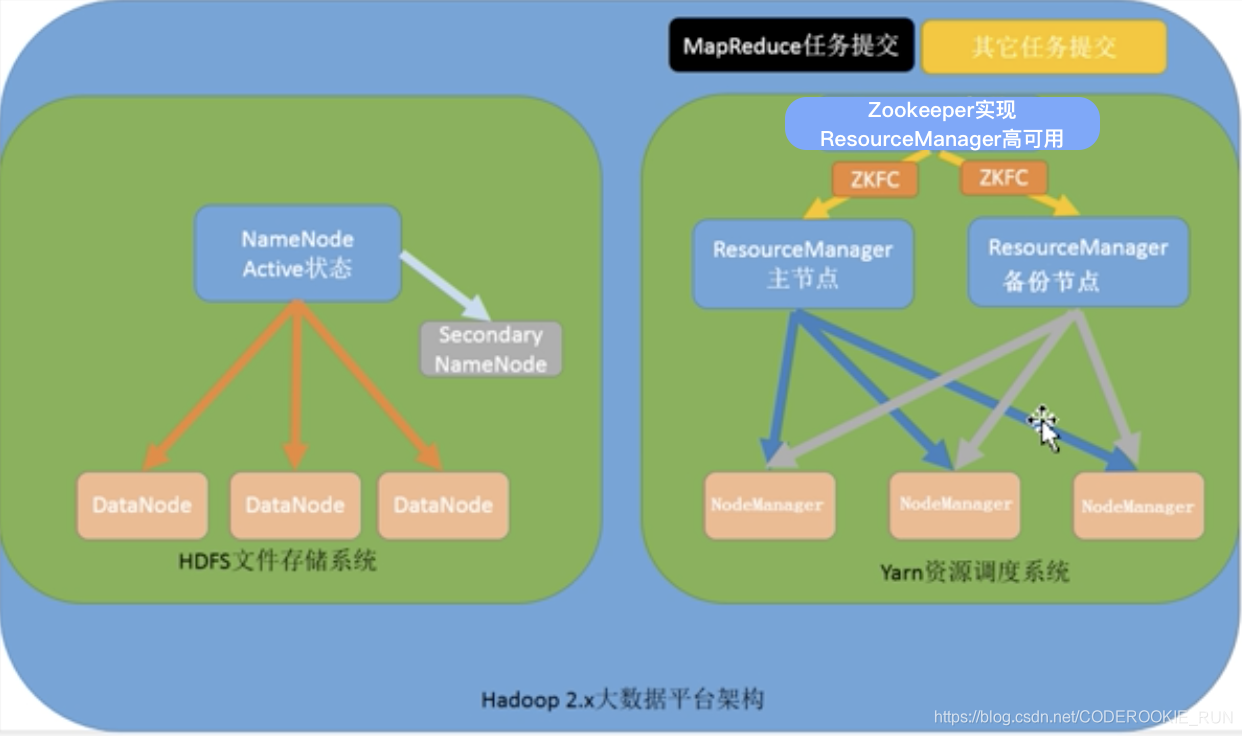
- 第二种:NameNode单节点和ResourceManager高可用架构模型
- 第三种:NameNode高可用和ResourceManager单节点架构模型
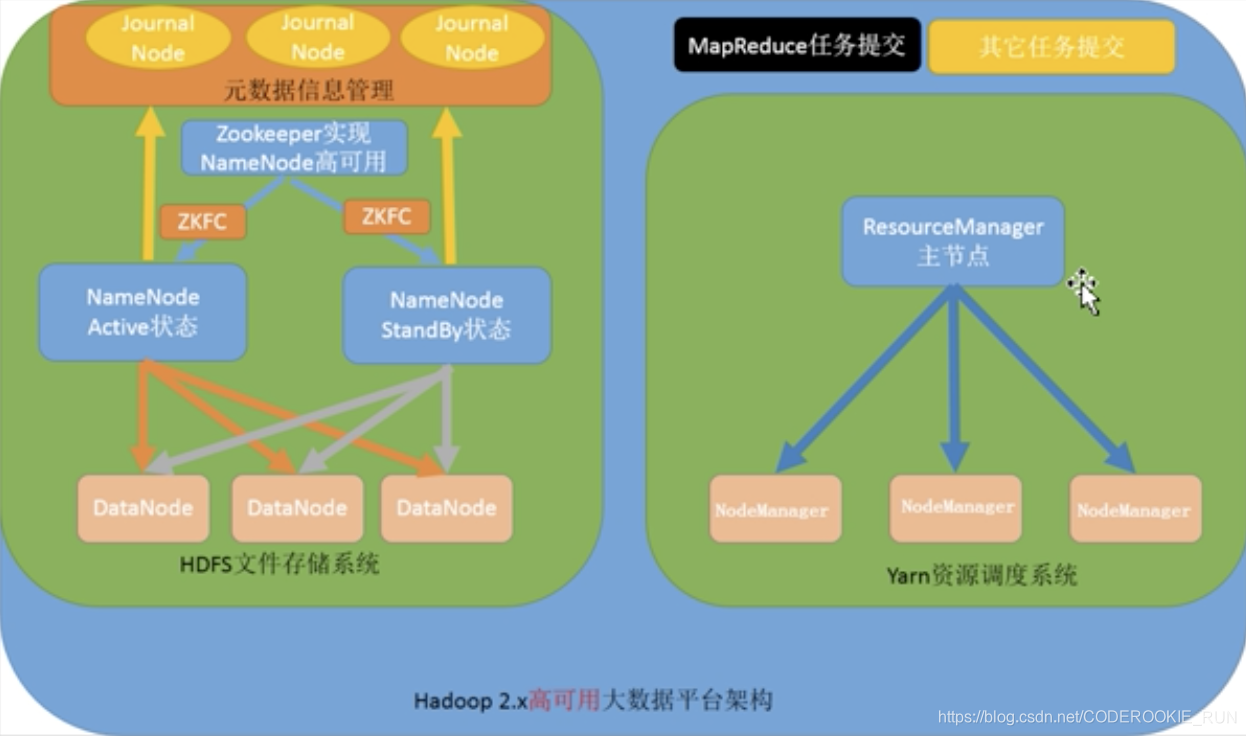
NameNode高可用
NameNode Active:处于活跃的主节点,处理用户请求,维护元数据信息
NameNode StandBy:处于待命的节点,当活跃的主节点出故障停止工作后,切换为活跃的主节点,对外提供服务
JournalNode:专门用于同步元数据信息(因为,如果NameNode高可用,就一定要保证两个NameNode的元数据信息一致,否则就会出现脑裂的问题。JournalNode机制就是用来解决这个问题的)
zkfc ( ZooKeeper FailLover Controller ):NameNode的守护进程,用于监听NameNode的状态,当NameNode Active出故障停机时,会立刻通知NameNode StandBy切换为活跃的主节点
- 第四种:NameNode高可用和ResourceManager高可用架构模型
【Hadoop离线基础总结】Hadoop的架构模型的更多相关文章
- 【Hadoop离线基础总结】流量日志分析网站整体架构模块开发
目录 数据仓库设计 维度建模概述 维度建模的三种模式 本项目中数据仓库的设计 ETL开发 创建ODS层数据表 导入ODS层数据 生成ODS层明细宽表 统计分析开发 流量分析 受访分析 访客visit分 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- 【Hadoop离线基础总结】impala简单介绍及安装部署
目录 impala的简单介绍 概述 优点 缺点 impala和Hive的关系 impala如何和CDH一起工作 impala的架构及查询计划 impala/hive/spark 对比 impala的安 ...
- 【Hadoop离线基础总结】Hue的简单介绍和安装部署
目录 Hue的简单介绍 概述 核心功能 安装部署 下载Hue的压缩包并上传到linux解压 编译安装启动 启动Hue进程 hue与其他框架的集成 Hue与Hadoop集成 Hue与Hive集成 Hue ...
- 【Hadoop离线基础总结】Sqoop常用命令及参数
目录 常用命令 常用公用参数 公用参数:数据库连接 公用参数:import 公用参数:export 公用参数:hive 常用命令&参数 从关系表导入--import 导出到关系表--expor ...
- 【Hadoop离线基础总结】Hive调优手段
Hive调优手段 最常用的调优手段 Fetch抓取 MapJoin 分区裁剪 列裁剪 控制map个数以及reduce个数 JVM重用 数据压缩 Fetch的抓取 出现原因 Hive中对某些情况的查询不 ...
- 【Hadoop离线基础总结】Hadoop High Availability\Hadoop基础环境增强
目录 简单介绍 Hadoop HA 概述 集群搭建规划 集群搭建 第一步:停止服务 第二步:启动所有节点的ZooKeeper 第三步:更改配置文件 第四步:启动服务 简单介绍 Hadoop HA 概述 ...
- 【Hadoop离线基础总结】关键路径转化率分析(漏斗模型)
关键路径转化 需求 在一条指定的业务流程中,各个步骤的完成人数及相对上一个步骤的百分比 模型设计 定义好业务流程中的页面标识 Step1. /item Step2. /category Step3. ...
- 【Hadoop离线基础总结】网站流量日志数据分析系统
目录 点击流数据模型 概述 点击流模型 网站流量分析 网站流量模型分析 网站流量来源 网站流量多维度细分 网站内容及导航分析 网站转化及漏斗分析 流量常见分析角度和指标分类 指标概述 指标分类 分析角 ...
随机推荐
- kworkerds 挖矿木马简单分析及清理
公司之前的开发和测试环境是在腾讯云上,部分服务器中过一次挖矿木马 kworkerds,本文为我当时分析和清理木马的记录,希望能对大家有所帮助. 现象 top 命令查看,显示 CPU 占用 100%,进 ...
- S7通信协议之你不知道的事儿
在电气学习的路上,西门子PLC应该是我的启蒙PLC,从早期的S7-300/400 PLC搭建Profibus-DP网络开始接触,到后来的S7-200Smart PLC,再到现在的S7-1200/150 ...
- sysbench安装和使用
sysbench是一款测试工具 主要包括以下几种方式的测试: 1.cpu性能 2.磁盘io性能 3.调度程式性能 4.内存分配及传输速度 5.POSIX线程性能 6.数据库性能(OLTP基准测试)现在 ...
- [转载]MySQL中int(11)最大长度是多少?
原文地址:https://blog.csdn.net/allenjay11/article/details/76549503 今天在添加数据的时候,发现当数据类型为 int(11) 时,我当时让用户添 ...
- [PHP] 文件创建、写入、读取
创建$p = fopen('text.txt','a+b'); 写入第一种方式//var_export方式存储数组到文件中 //这中方式存浮点型数据,存储后会多很多数字!只适合简单的存储吧!我感觉! ...
- redis: 持久化(十二)
RDB配置 RDB 是 Redis 默认的持久化方案.在指定的时间间隔内,执行指定次数的写操作,则会将内存中的数据写入到磁盘中.即在指定目录下生成一个dump.rdb文件.Redis 重启会通过加载d ...
- Python推荐系统框架:RecQ
RecQ是一个用于推荐系统的python库(python2.7.x),实现了一些state-of-the-art的推荐算法. github地址:https://github.com/Coder-Yu/ ...
- pytorch seq2seq模型训练测试
num_sequence.py """ 数字序列化方法 """ class NumSequence: """ ...
- mac使用brew安装mysql5.7
安装mysql5.7 brew install mysql@5.7 设置环境变量(可能安装完自动生成过了,可以cat ~/.zshrc看一下,有了就不用添加了 ) echo 'export PATH= ...
- QT踩坑记录1-多线程信号与槽
QT踩坑记录1-多线程信号与槽 QTC++Bugs 错误输出 无错误输出, 但是声明了信号的连接,但是无法使用 程序中就是无命令 介绍 QT 典型程序 #include <QObject> ...