sql 服务器统计信息简介
sql服务器统计是包含数据分布信息的系统对象.有时,在正则列值中。统计可以在任何支持比较操作的数据类型上创建,例如 > , < , =等。
列表2-15中,从dbo.books表中查看 IDX_BOOKS_ISBN 指数统计数据.您可以通过使用dbcc命令 SHOW_STATISTICS ('dbo.Books',IDX_BOOKS_ISBN )来实现这一点。如图3-1.
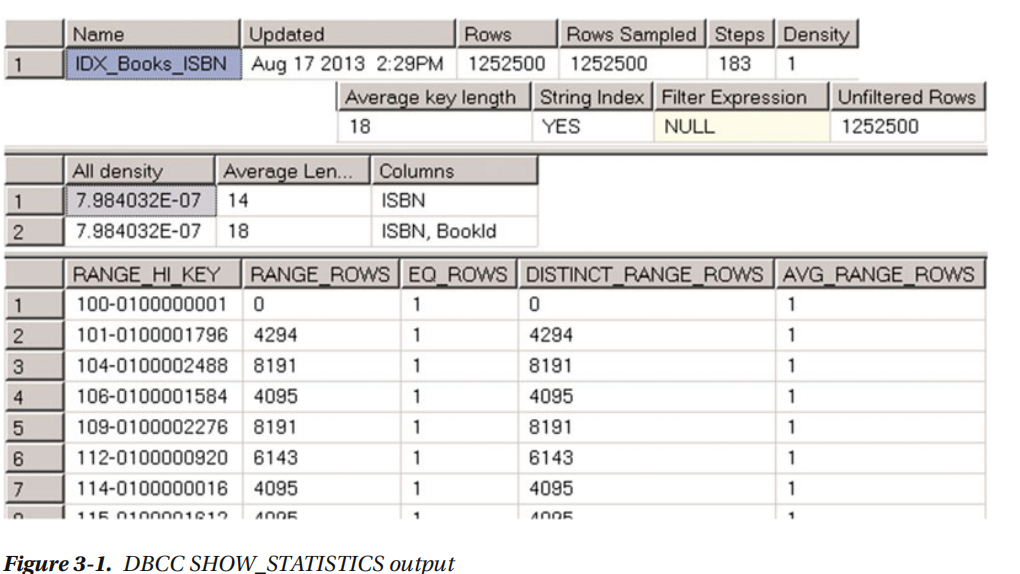
正如您所看到的,dbcc show_stums命令返回三个结果集。第一个包含关于统计的一般元数据信息,如名称、更新日期、更新统计时索引中的行数等等。第一个结果集中的步数列表示直方图中的步数/值(更多关于后面的部分)。该密度值不被查询优化器使用,仅用于向后兼容性目的。
第二个结果集,称为密度向量,包含了统计(指数)关键值组合的密度信息。它是根据一或多个不同的值公式计算的,并指示每个键值组合平均有多少行。
它是根据一或多个不同的值公式计算的,并指示每个键值组合平均有多少行。尽管IDX_Books_ISBN指针只定义了一个关键列,但它也包含了一个聚集的索引键,作为索引行的一部分。我们的表中有1,252,500种独特的 ISBN值, ISBN列的密度为1.0 / 1,252,500 = 7.984032E-07。所有的组合(ISBN,bookid)列也是独一无二的,并且具有相同的密度。
最后一个结果集称为直方图。直方图中的所有记录,称为直方图的步,在统计数据(索引)最左边的列中包括样例键值,以及关于从前面到当前范围键值范围内的数据分布的信息。让我们更深入地看直方图的列。 RANGE_HI_KEY列存储密钥的示例值。此值是直方图步骤定义的范围的上界键值。例如,在图3-1的直方图中,记录(步骤)#3的距离RANGE_HI_KEY = '104-0100002488' 存储了关于从 ISBN > '101-0100001796'到 ISBN <= '104-0100002488'。
RANGE_ROWS列估计区间内的行数。在我们的例子中,由记录(步骤)#3定义的间隔有8,191行。
EQ_ROWS指示有多少行的键值等于RANGE_HI_KEY的上界值。就我们的情况而言,只有一行的 ISBN = '104-0100002488' .
DISTINCT_RANGE_ROWS指示间隔内的键有多少个不同的值。在我们的例子中,所有的键的值都是唯一的,如 DISTINCT_RANGE_ROWS = RANGE_ROWS .
AVG_RANGE_ROWS表示区间内每个独立键值的平均行数。在我们的情况下,所有的键的值都是唯一的,所以 AVG_RANGE_ROWS = 1。
让我们在索引中插入一组重复的ISBN值,代码如图3-1。

现在,如果您再次运行SHOW_STATISTICS ('dbo.Books',IDX_BOOKS_ISBN ) 命令,您将看到图3-2所示的结果。
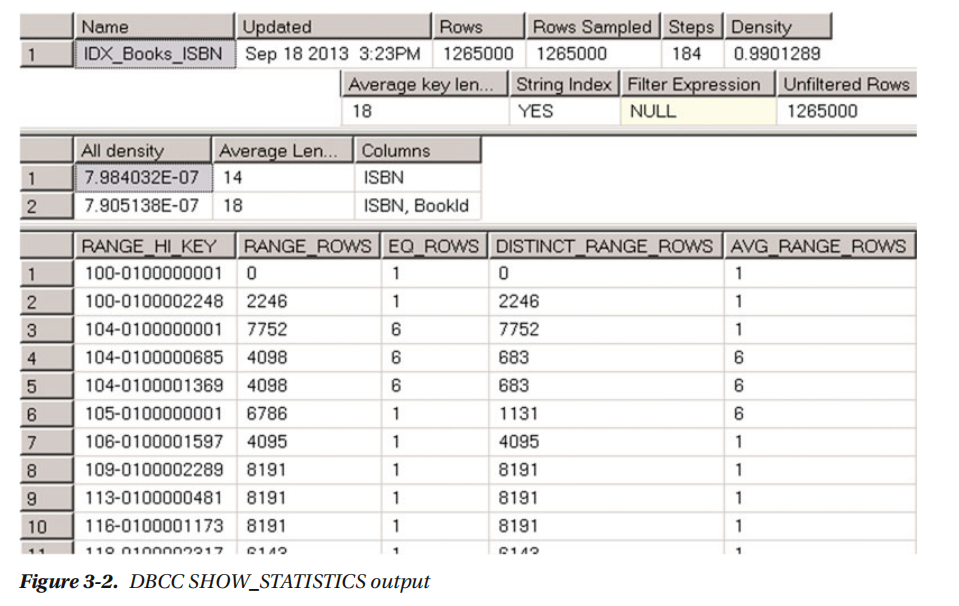
字首104的ISBN值现在有了重复,这影响了直方图。还值得一提的是,第二个结果集中的密度信息也被改变了。
具有重复值的ISBNS的密度高于(isbn,bookid)列的组合这个列是唯一的。
执行SELECT BookId, Title FROM dbo.Books WHERE ISBN LIKE ‘114%’语句,检查执行计划,如图3-3所示。
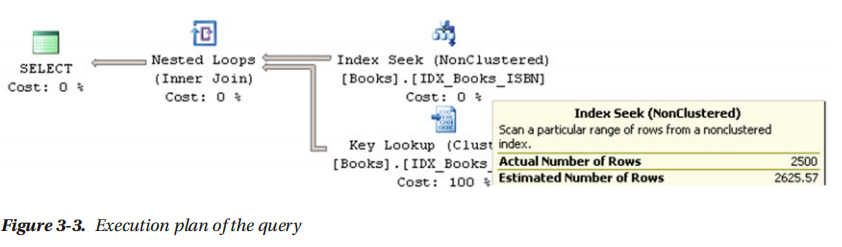
有两个重要的属性,大多数执行计划运算符都有。实际行数
指示在操作符执行期间处理了多少行。估计行数表示查询优化阶段sql服务器为该操作符估计的行数。sql服务器估计有2,625个行,ISNBS从114开始。如图3-2您将看到第10步存储有关isbn区间数据分布的信息,其中包括您选择的值。即使采用近似线性估计,估计出的行数接近sql服务器确定的行数。
关于统计,有两件事要记住。
- 直方图仅为最左边的统计数据(索引)列存储有关数据分布的信息。有关于统计中关键值的多列密度的信息,但仅此而已。直方图中的所有其他信息只涉及最左边统计列的数据分布。
- sql服务器在直方图中最多保留200步,不管表的大小,也不管表是否分区。每个直方图步骤覆盖的间隔随着表的增长而增加。过大的表会导致统计数据不太准确。
对于复合索引,当索引的所有列在所有查询中用作预测时,将密度较低/唯一值百分比较高的列定义为索引最左边的列是比较好的。这将使sql服务器能够更好地利用统计数据中的数据分布信息。然而,你应该考虑这些预测的限制搜索性(SARG)。例如,如果所有查询句中使用的都是 FirstName=@FirstName 和LastName=@LastName预测,那么最好将 LastName作为索引中最左边的列。尽管如此,对于FirstName=@FirstName and LastName<>@LastName,情况并非如此,在这些预测中, LastName 不是可以限制搜索的(SARG)。
统计和执行计划
sql服务器默认自动创建和更新统计数据。数据库中有两个选项控制此类行为的级别:
- 自动创建统计控制是否优化程序自动创建列级统计。这个选项不会产生影响,因为索引级统计始终会创建。默认情况下会启用自动创建统计数据库选项。
- 启用自动更新统计数据库选项时,sql服务器每次编译或执行查询时都会检查统计数据是否过时,并在需要时更新统计数据。默认情况下也会启用自动更新统计数据库选项。
提示:您可以通过使用统计计算(STATISTICS_NORECOMPUTE)索引选项来控制索引级别上的统计数据的自动更新行为。默认情况下,此选项将被关闭,意思就是说统计数据默认自动更新。在索引或表级别上改变自动更新行为的另一种方法是使用sp_autostats系统存储过程。
sql服务器根据插入、更新、删除和合并语句执行的影响统计列的更改次数确定统计是否过时。sql服务器计算统计列被更改的次数,而不是更改行的数目。例如,如果您将同一行更改100次,它将被算作100次更改,而不是1次更改。
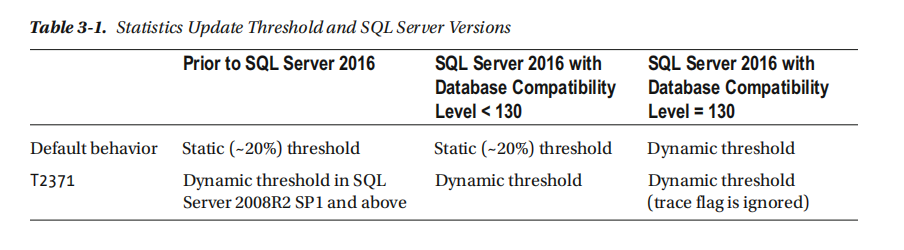
有三种不同的方案,称为统计更新阈值,有时也称为统计重新编译阈值,其中sql服务器将统计标记为过时。
- 当表为空时,当您将数据添加到表中时,sql服务器将超出统计数据。
- 当表的行少于500行时,每500次统计列的更改,sql服务器就会超出统计数据。
- 2016版sql服务器和之前的版本,具有数据库兼容性级别小于130.如果表中有500行或更多行,则在统计列每500+(占表中行总数的20%)发生变化后,sql服务器就会超出统计数据。
- 2016版sql服务器数据库兼容性级别等于130.大量表的统计数据更新阈值变成动态,而且取决于表的大小。表的行越多,阈值越低。在上百万行甚至数十亿行的大量表格中,统计更新阈值只能是表中行总数百分比的一小部分。此特征也可以在sql服务器2008R2 SP1及更高版本中启用跟踪标志T2371。
表3-1总结了不同版本的sql服务器的统计更新阈值行为。
这使我们得出一个非常重要的结论。
使用静态统计更新阈值,触发统计更新所需的统计列的更改数与表大小成正比。表格越大,自动更新的统计数据就越少。例如,在有10亿行的表的情况下,您需要对统计列执行约2亿项更改使统计数据过时。如果可以的话建议使用动态更新阈值。
让我们看看这种行为是如何影响我们的系统和执行计划的。在这一点上,该表dbo.Books有1265000行。我们把250,000行加上前缀999,如表3-5.在此示例中,我使用的是sql服务器2012,未启用T2371。如果启用动态统计更新阈值就可以看到不同的结果。此外,在sql服务器2014中引入的新的基数估计器也可以改变行为。我们会在后面章节中进行讨论。

我们执行SELECT * FROM dbo.Books WHERE ISBN LIKE '999%' 语句,它可以选择带有此前缀的所有行。
如果检查查询的执行计划,如图3-7所示,您将看到非集群索引查找和键查找操作。
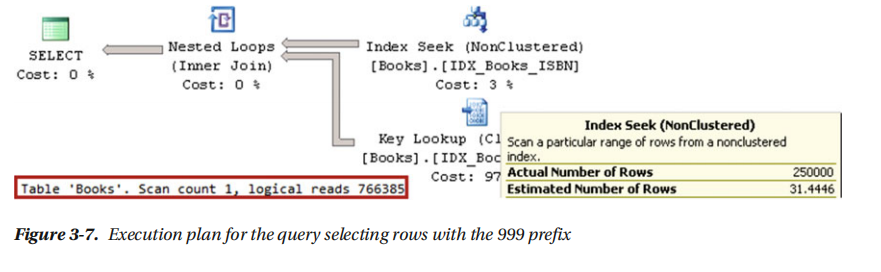
您还会在图3-7中注意到索引查找运算符的估计行数和实际行数之间存在巨大差异。sql服务器估计表中只有31.4行带有前缀999,实际有25万行带有这样的前缀。这就产生了一个非常低效的计划。
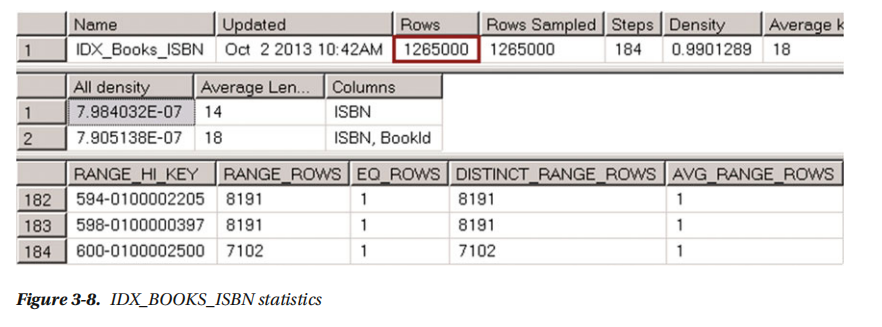
接下来,通过DBCC执行命令 SHOW_STATISTICS ('dbo.Books', IDX_BOOKS_ISBN) 看看 IDX_BOOKS_ISBN统计。输出如图3-8所示。如您所见,即使我们在表格中插入了25万行,统计数据也没有更新,而且直方图中没有关于999前缀的数据。第一个结果集中的行数相对应上一个统计期间表中的行数更新。它不包括刚刚插入的250,000行。
通过语句UPDATE STATISTICS dbo.Books IDX_Books_ISBN WITH FULLSCAN更新统计,然后重新执行 SELECT * FROM dbo.Books WHERE ISBN LIKE '999%' 语句。执行计划如3-9.现在估计的行数是正确的,而sql服务器最终采用了更高效的执行计划,使用的是集群索引扫描,比以前减少了大约17倍的输入/输出读取量。

如你所见,不正确的基数估计会导致执行计划效率低下。过时的统计数据也会是造成基数估计错误的最常见原因之一。您可以通过检查执行计划中的估计行和实际行数来确定其中的一些情况。这两个数值之间的巨大差异往往表明统计数字不正确。更新统计可以解决这个问题,产生更有效率的执行计划。
统计数据的维护
正如我已经提到的,sql服务器默认自动更新统计数据。这种行为对于少量表格是一般可以接受的。
但是,对于具有数百万或数十亿行的大量表,不应依赖自动统计更新,除非使用数据库兼容性为130或与跟踪标记T2371兼容的sql服务器2016。根据20%的统计数据更新阈值触发统计数据更新的话,所需的更改数量会非常大,因此,更新不会经常触发。在这种情况下建议您手动更新统计数据。选择最佳统计维护时,一定要分析表数据修改模式的大小和系统可用性。
例如,如果系统在工作时间以外没有很大的负载,您可以在夜间更新关键表的统计数据。
不要忘记统计或索引维护也会给sql服务器添加额外的负载。一定要分析它如何影响同一服务器和磁盘数组上的其他数据库。
在设计统计维护策略时,另一个需要考虑的重要因素就是怎么修改数据。在键值不断增加或减少的索引中,您要更经常地更新统计数据,例如当索引中最左边的列被定义为标识或用序列对象填充时。
如你所见,如果特定的键值在直方图之外,sql服务器就会低估行的数量。在2014至2016版的sql服务器中,这种行为可能有所不同,我们将在下文中讨论。
可以用 UPDATE STATISTICS命令升级统计。当sql服务器更新统计数据时,它会读取数据样本,而不是扫描整个索引。您可以使用全扫描选项来改变这种行为,该选项强制sql服务器读取和分析索引中的所有数据。正如您可能猜测的那样,该选项提供了最准确的结果,即使是在大量表下引入大量的输入输出。
在重建索引时,sql服务器会更新统计数据。我们将在第六章“索引碎片”中更详细地讨论索引维护。
您可以使用sp_dendests系统存储过程来更新数据库中的所有统计数据。建议您使用此存储过程,并在升级到新版本的sql服务器后更新数据库中的所有统计数据。您应该与DBCC更新使用存储过程一起运行,该过程将纠正目录视图中不正确的页和行计数信息。sys.dm_db_stats_properties DMV显示了自上次更新统计数据以来对统计数据列所做的修改数量。使用该 DMV的代码在列表3-9中。

如图3-11所示,查询结果表明,自上次更新统计数据以来,对统计数据栏进行了250 000项修改。您可以构建一个统计维护例程,该例程定期检查sys.dm_db_stats_属性dmv,并使用大的修改计数器(modification_ counter)值重新构建统计。

另一个与统计相关的数据库选项是异步自动更新统计。默认情况下,当sql服务器检测到统计数据过时时,它会暂停查询执行,同步更新统计,并在统计更新完成后生成新的执行计划。使用异步统计更新,sql服务器使用旧的执行计划执行查询,该计划基于过时的统计数据,同时异步更新背景中的统计数据。建议您保持同步统计更新,除非系统查询超时很短,在这种情况下,同步统计更新可以超时查询。
最后,创建新索引时,sql服务器不会自动删除列级统计数据。您应该手动删除多余的列级别统计对象
sql 服务器统计信息简介的更多相关文章
- 全废话SQL Server统计信息(1)——统计信息简介
当心空无一物,它便无边无涯.树在.山在.大地在.岁月在.我在.你还要怎样更好的世界?--张晓风<我在> 为什么要写这个内容? 随着工作经历的积累,越来越感觉到,大量的关系型数据库的性能问题 ...
- 全废话SQL Server统计信息(2)——统计信息基础
接上文:http://blog.csdn.net/dba_huangzj/article/details/52835958 我想在大地上画满窗子,让所有习惯黑暗的眼睛都习惯光明--顾城<我是一个 ...
- SQL Server统计信息:问题和解决方式
在网上看到一篇介绍使用统计信息出现的问题已经解决方式,感觉写的很全面. 在自己看的过程中顺便做了翻译. 因为本人英文水平有限,可能中间有一些错误. 假设有哪里有问题欢迎大家批评指正.建议英文好的直接看 ...
- SQL Server 统计信息更新时采样百分比对数据预估准确性的影响
为什么要写统计信息 最近看到园子里有人写统计信息,楼主也来凑热闹. 话说经常做数据库的,尤其是做开发的或者优化的,统计信息造成的性能问题应该说是司空见惯. 当然解决办法也并非一成不变,“一招鲜吃遍天” ...
- SQL Server 统计信息
SELECT * FROM SYS.stats _WA_Sys_00000009_00000062:统计对象的名称.不同的机器名称不同,自动创建的统计信息都以_WA_Sys开头,00000009表示的 ...
- SQL SERVER 统计信息概述(Statistics)
前言 查询优化器使用统计信息来创建可提高查询性能的查询计划,对于大多数查询,查询优化器已经为高质量查询计划生成必要的统计信息,但是在少数情况下,您需要创建附加的统计信息或者修改查询设计以得到最佳结果. ...
- SQL Server 统计信息的创建与更新
前期准备: 普通表.临时表:它两会有统计信息. 表变量: 不会有统计信息. ---------------------------------------------------- ...
- SQL Server统计信息偏差影响表联结方式案例浅析
我们知道数据库中的统计信息的准确性是非常重要的.它会影响执行计划.一直想写一篇关于统计信息影响执行计划的相关博客,但是都卡在如何构造一个合适的例子上,所以一直拖着没有写.巧合,最近在生产环境中遇到 ...
- SQL Server 统计信息(Statistics)-概念,原理,应用,维护
前言:统计信息作为sql server优化器生成执行计划的重要参考,需要数据库开发人员,数据库管理员对其有一定的理解,从而合理高效的应用,管理. 第一部分 概念 统计信息(statistics):描述 ...
随机推荐
- js强制浏览器重新渲染页面
今天遇到一个浏览器兼容性问题,大致原因就是在用某一个前端框架做分页时,由于是使用的jQuery的hide和show方法,其本质是为某个iframe加上一个display=none,这在chrome中是 ...
- [学习笔记]连通分量与Tarjan算法
目录 强连通分量 求割点 求桥 点双连通分量 模板题 Go around the Labyrinth 所以Tarjan到底怎么读 强连通分量 基本概念 强连通 如果两个顶点可以相互通达,则称两个顶点强 ...
- 使script.bin文件配置生效的驱动
1.问题:在全志方案中如果需要设置上拉或者下拉模式,需要在script.bin(先转换为script.fex)中配置gpio口 如: 但是配置好后是不会生效的,需要写一个驱动来通过读取这个文件的gp ...
- kaggle注册获取数据
安装谷歌访问助手,主要参考下面的作者写的 https://segmentfault.com/a/1190000020548973?utm_source=tag-newest 安装之后,打开蓝灯或其他翻 ...
- idea 为模块添加Tomcat依赖 解决: Intelij IDEA 创建WEB项目时没有Servlet的jar包
解决: Intelij IDEA 创建WEB项目时没有Servlet的jar包 今天创建SpringMVC项目时 用到HttpServletRequest时, 发现项目中根本没有Servlet这个包, ...
- Cobbler_自动装系统
Cobbler —自动装系统的操作步骤 Cobbler是一款自动化操作系统安装的实现,与PXE安装系统的区别就是可以同时部署多个版本的系统,而PXE只能选择一种系统. Cobbler 的安装 # 在一 ...
- 2019-2020-1 20199324《Linux内核原理与分析》第七周作业
第六章 进程的描述和进程的创建 知识点总结 进程的描述 操作系统内核实现操作系统的三大管理功能以及对应的抽象概念: 进程管理(最核心)-- 进程 内存管理 -- 虚拟内存 文件系统 -- 文件 进程是 ...
- 如何查看Linux系统下程序运行时使用的库?
Linux系统下程序运行会实时的用到相关动态库,某些场景下,比如需要裁剪不必要的动态库时,就需要查看哪些动态库被用到了. 以运行VLC为例. VLC开始运行后,首先查看vlc的PID,比如这次查到的V ...
- Xen入门系列三【Xen 管理工具 xm】
xm命令是管理Xen的最基本的工具,可以通过xm --help 来获得帮助. 1. 列出所有正在运行的虚拟操作系统 # xm list PS[1]:可缩写为 xm li 2. 启动虚拟机 # 通过配置 ...
- IDEA+selenium3+火狐/谷歌驱动 JAVA初步环境搭建 笔记
0 环境 系统环境:win7 selenium驱动 谷歌浏览器以及驱动 火狐浏览器以及驱动 1 驱动地址的下载 1.1 selenium jar包 https://www.seleniumhq.org ...