【Spark篇】---SparkStream初始与应用
一、前述
SparkStreaming是流式处理框架,是Spark API的扩展,支持可扩展、高吞吐量、容错的实时数据流处理,实时数据的来源可以是:Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,并且可以使用高级功能的复杂算子来处理流数据。例如:map,reduce,join,window 。最终,处理后的数据可以存放在文件系统,数据库等,方便实时展现。
二、SparkStreaming与Storm的区别
1、Storm是纯实时的流式处理框架,SparkStreaming是准实时的处理框架(微批处理)。因为微批处理,SparkStreaming的吞吐量比Storm要高。
2、Storm 的事务机制要比SparkStreaming的要完善。
3、Storm支持动态资源调度。(spark1.2开始和之后也支持)
4、SparkStreaming擅长复杂的业务处理,Storm不擅长复杂的业务处理,擅长简单的汇总型计算。
三、Spark初始

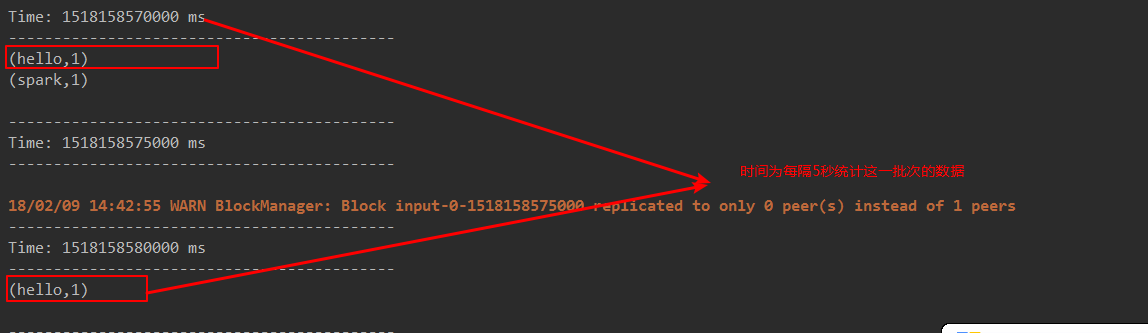
- receiver task是7*24小时一直在执行,一直接受数据,将一段时间内接收来的数据保存到batch中。假设batchInterval为5s,那么会将接收来的数据每隔5秒封装到一个batch中,batch没有分布式计算特性,这一个batch的数据又被封装到一个RDD中,RDD最终封装到一个DStream中。
例如:假设batchInterval为5秒,每隔5秒通过SparkStreamin将得到一个DStream,在第6秒的时候计算这5秒的数据,假设执行任务的时间是3秒,那么第6~9秒一边在接收数据,一边在计算任务,9~10秒只是在接收数据。然后在第11秒的时候重复上面的操作。
- 如果job执行的时间大于batchInterval会有什么样的问题?
如果接受过来的数据设置的级别是仅内存,接收来的数据会越堆积越多,最后可能会导致OOM(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟 )。
四、SparkStreaming代码
代码注意事项:
- 启动socket server 服务器:nc –lk 9999
- receiver模式下接受数据,local的模拟线程必须大于等于2,一个线程用来receiver用来接受数据,另一个线程用来执行job。
- Durations时间设置就是我们能接收的延迟度。这个需要根据集群的资源情况以及任务的执行情况来调节。
- 创建JavaStreamingContext有两种方式(SparkConf,SparkContext)
- 所有的代码逻辑完成后要有一个output operation类算子触发执行。
- JavaStreamingContext.start() Streaming框架启动后不能再次添加业务逻辑。
- JavaStreamingContext.stop() 无参的stop方法将SparkContext一同关闭,stop(false),不会关闭SparkContext,方便后面使用
- JavaStreamingContext.stop()停止之后不能再调用start。
package com.spark.sparkstreaming; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2;
/**
* 1、local的模拟线程数必须大于等于2 因为一条线程被receiver(接受数据的线程)占用,另外一个线程是job执行
* 2、Durations时间的设置,就是我们能接受的延迟度,这个我们需要根据集群的资源情况以及监控每一个job的执行时间来调节出最佳时间。
* 3、 创建JavaStreamingContext有两种方式 (sparkconf、sparkcontext)
* 4、业务逻辑完成后,需要有一个output operator
* 5、JavaStreamingContext.start()straming框架启动之后是不能在次添加业务逻辑
* 6、JavaStreamingContext.stop()无参的stop方法会将sparkContext一同关闭,stop(false) ,默认为true,会一同关闭
* 7、JavaStreamingContext.stop()停止之后是不能在调用start
*/ /**
* foreachRDD 算子注意:
* 1.foreachRDD是DStream中output operator类算子
* 2.foreachRDD可以遍历得到DStream中的RDD,可以在这个算子内对RDD使用RDD的Transformation类算子进行转化,但是一定要使用rdd的Action类算子触发执行。
* 3.foreachRDD可以得到DStream中的RDD,在这个算子内,RDD算子外执行的代码是在Driver端执行的,RDD算子内的代码是在Executor中执行。
*
*/
public class WordCountOnline {
@SuppressWarnings("deprecation")
public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WordCountOnline");
/**
* 在创建streaminContext的时候 设置batch Interval
*/
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
// JavaSparkContext sc = new JavaSparkContext(conf);
// JavaStreamingContext jsc = new JavaStreamingContext(sc,Durations.seconds(5));//两种办法得到StreamingContext
// JavaSparkContext sparkContext = jsc.sparkContext(); JavaReceiverInputDStream<String> lines = jsc.socketTextStream("node04", 9999);//监控socket端口9999 JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
/**
*
*/
private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String s) {
return Arrays.asList(s.split(" "));
}
}); JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
}); JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L; @Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
}); //outputoperator类的算子
counts.print();
/*counts.foreachRDD(new VoidFunction<JavaPairRDD<String,Integer>>() { *//**
* 这里写的代码是在Driver端执行的
*//*
private static final long serialVersionUID = 1L; @Override
public void call(JavaPairRDD<String, Integer> pairRDD) throws Exception { pairRDD.foreach(new VoidFunction<Tuple2<String,Integer>>() { *//**
*
*//*
private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Integer> tuple)
throws Exception {
System.out.println("tuple ---- "+tuple );
}
});
}
});*/
jsc.start();
//等待spark程序被终止
jsc.awaitTermination();
jsc.stop(false);
}
}
scala代码:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Durations object Operator_foreachRDD {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[2]").setAppName("foreachRDD")
val sc = new SparkContext(conf)
val jsc = new StreamingContext(sc,Durations.seconds(5)) val socketDStream = jsc.socketTextStream("node5", 9999)
socketDStream.foreachRDD { rdd => {
rdd.foreach { elem => {
println(elem)
} }
}} jsc.start()
jsc.awaitTermination()
jsc.stop(false)
}
}

【Spark篇】---SparkStream初始与应用的更多相关文章
- 【转帖】HBase读写的几种方式(二)spark篇
HBase读写的几种方式(二)spark篇 https://www.cnblogs.com/swordfall/p/10517177.html 分类: HBase undefined 1. HBase ...
- 【Spark篇】---SparkSQL初始和创建DataFrame的几种方式
一.前述 1.SparkSQL介绍 Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制. SparkSQL支持查询原 ...
- 【Spark篇】---Spark初始
一.前述 Spark是基于内存的计算框架,性能要优于Mapreduce,可以实现hadoop生态圈中的多个组件,是一个非常优秀的大数据框架,是Apache的顶级项目.One stack rule ...
- HBase读写的几种方式(二)spark篇
1. HBase读写的方式概况 主要分为: 纯Java API读写HBase的方式: Spark读写HBase的方式: Flink读写HBase的方式: HBase通过Phoenix读写的方式: 第一 ...
- 【Spark篇】---SparkStreaming算子操作transform和updateStateByKey
一.前述 今天分享一篇SparkStreaming常用的算子transform和updateStateByKey. 可以通过transform算子,对Dstream做RDD到RDD的任意操作.其实就是 ...
- 【Spark篇】---Spark中广播变量和累加器
一.前述 Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量. 累机器相当于统筹大变量,常用于计数,统计. 二.具体原理 ...
- HBase 中加盐之后的表如何读取:Spark 篇
在 <HBase 中加盐之后的表如何读取:协处理器篇> 文章中介绍了使用协处理器来查询加盐之后的表,本文将介绍第二种方法来实现相同的功能. 我们知道,HBase 为我们提供了 hbase- ...
- Oozie分布式任务的工作流——Spark篇
Spark是现在应用最广泛的分布式计算框架,oozie支持在它的调度中执行spark.在我的日常工作中,一部分工作就是基于oozie维护好每天的spark离线任务,合理的设计工作流并分配适合的参数对于 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
随机推荐
- nginx配置负载均衡
本教程不讲解nginx的安装,若安装请看博客 http://www.cnblogs.com/hqjy/p/8092983.html 本教程不讲解tomcat的安装,若安装请看博客 http://www ...
- PLS:利用PLS(两个主成分的贡献率就可达100%)提高测试集辛烷值含量预测准确度并《测试集辛烷值含量预测结果对比》—Jason niu
load spectra; temp = randperm(size(NIR, 1)); P_train = NIR(temp(1:50),:); T_train = octane(temp(1:50 ...
- macof python攻击脚本
#!/usr/bin/python import sys from scapy.all import * import time iface="eth0" if len(sys.a ...
- VS Code做项目的笔记
需要自己研究的东西:http://www.bootcss.com/ 画页面时的布局插件:http://blog.chinaunix.net/uid-22414998-id-2878529.html v ...
- linux去除\r(window中编辑的文本)
vim -b file 二进制贷款文件:%s/^M//g # 注意这里使用Ctrl+V+M输入^M 上面的方法我就不行,但是下面的可以: 如果不行可以使用 :%s/\r//
- python 多线程 及多线程通信,互斥锁,线程池
1.简单的多线程例子 import threading,timedef b_fun(i): print "____________b_fun start" time.sleep(7 ...
- Egret的容器--删除对象,遮罩
class P91F extends egret.Sprite { public constructor() { super(); this.addEventListener(egret.Event. ...
- 使用jq 仿 swper 图片左右滚动
<div> <div /</div> <div class="box"> <div class="box-ul" ...
- node 重新安装依赖模块
rm -rf node_modules rm package-lock.json npm cache clear --force npm install
- web 11
Obtaining the JSON: 1.首先,我们将把要检索的JSON的URL存储在变量中. 2.要创建请求,我们需要使用new关键字从XMLHttpRequest构造函数创建一个新的请求对象实例 ...