[Spark內核] 第41课:Checkpoint彻底解密:Checkpoint的运行原理和源码实现彻底详解
本课主题
- Checkpoint 运行原理图
- Checkpoint 源码解析
引言
Checkpoint 到底是什么和需要用 Checkpoint 解决什么问题:
- Spark 在生产环境下经常会面临 Transformation 的 RDD 非常多(例如一个Job 中包含1万个RDD) 或者是具体的 Transformation 产生的 RDD 本身计算特别复杂和耗时(例如计算时常超过1个小时) , 可能业务比较复杂,此时我们必需考虑对计算结果的持久化。
- Spark 是擅长多步骤迭代,同时擅长基于 Job 的复用。这个时候如果曾经可以对计算的过程进行复用,就可以极大的提升效率。因为有时候有共同的步骤,就可以免却重复计算的时间。
- 如果采用 persists 把数据在内存中的话,虽然最快速但是也是最不可靠的;如果放在磁盘上也不是完全可靠的,例如磁盘会损坏,系统管理员可能会清空磁盘。
- Checkpoint 的产生就是为了相对而言更加可靠的持久化数据,在 Checkpoint 可以指定把数据放在本地并且是多副本的方式,但是在正常生产环境下放在 HDFS 上,这就天然的借助HDFS 高可靠的特征来完成最大化的可靠的持久化数据的方式。
- Checkpoint 是为了最大程度保证绝对可靠的复用 RDD 计算数据的 Spark 的高级功能,通过 Checkpoint 我们通过把数据持久化到 HDFS 上来保证数据的最大程度的安任性
- Checkpoint 就是针对整个RDD 计算链条中特别需要数据持久化的环节(后面会反覆使用当前环节的RDD) 开始基于HDFS 等的数据持久化复用策略,通过对 RDD 启动 Checkpoint 机制来实现容错和高可用;
Checkpoint 运行原理图
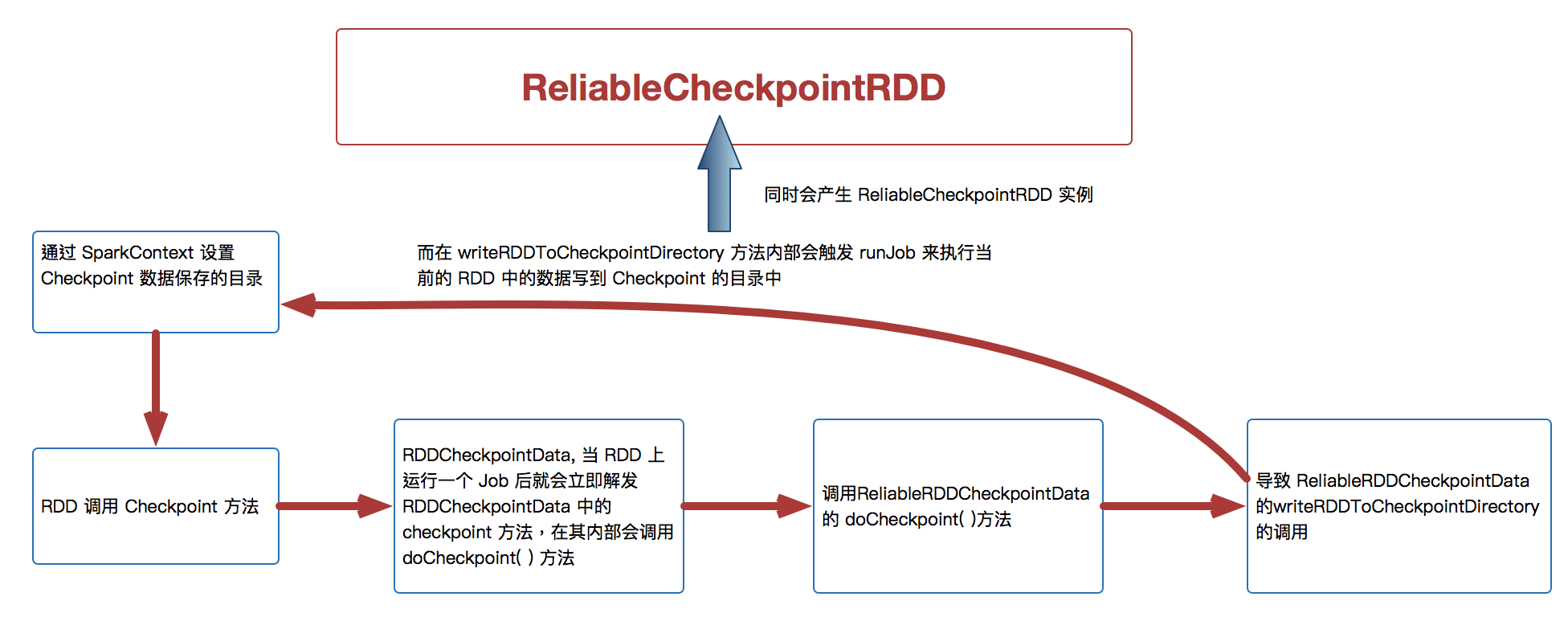
[下图是 Checkpoint 运行原理图]
Checkpoint 源码解析
- 回顾上一节的 RDD.iterator 方法,它会先在缓存中查看数据 (内部会查看 Checkpoint 有没有相关数据),然后再从 CheckPoint 中查看数据。
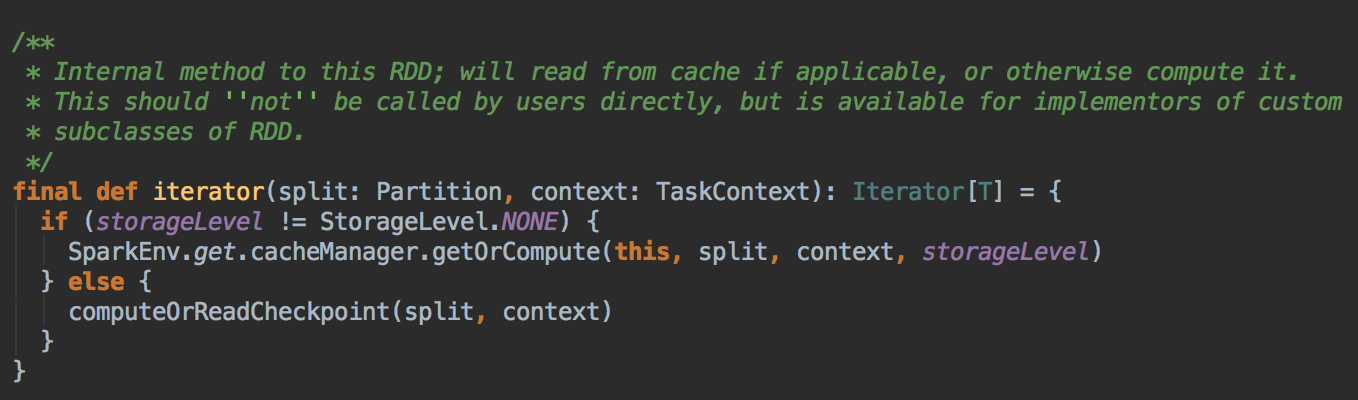
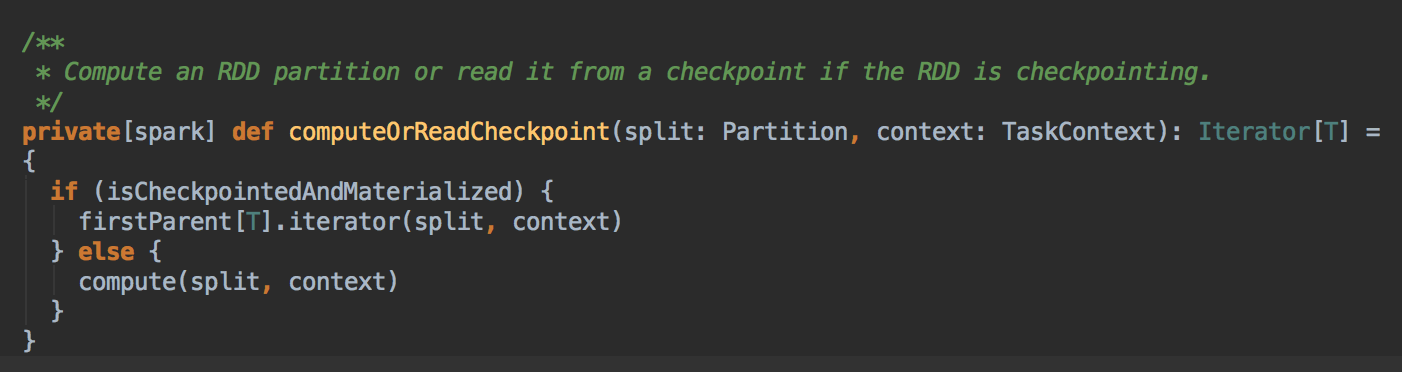
Checkpoint 有两种方法,一种是 reliably 和 一种是 locally
[下图是 RDD.scala 中的 isCheckpointed 变量和 isCheckpointedAndMaterialized 方法]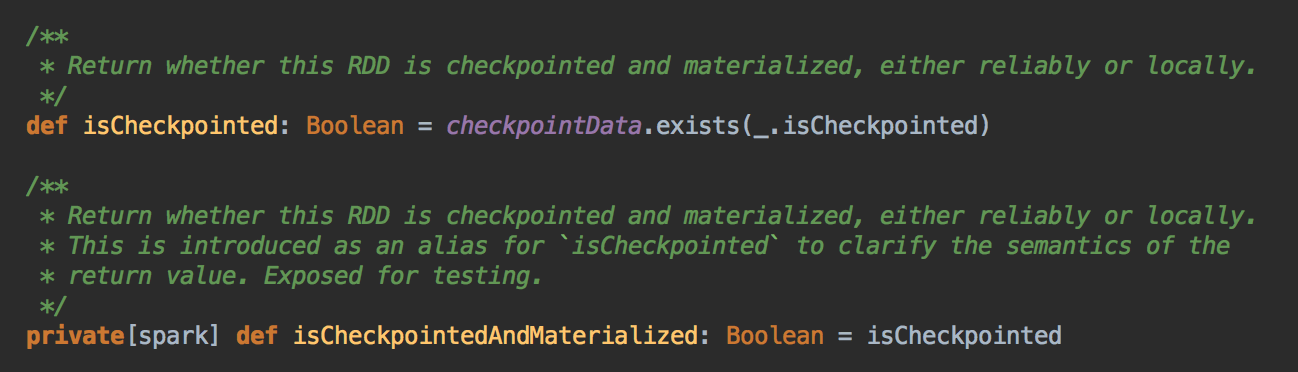
- 通过调用 SparkContext.setCheckpointDir 方法来指定进行 Checkpoint 操作的 RDD 把数据放在那里,在生产集群中是放在 HDFS 上的,同时为了提高效率在进行 Checkpoint 的时候可以指定很多目录
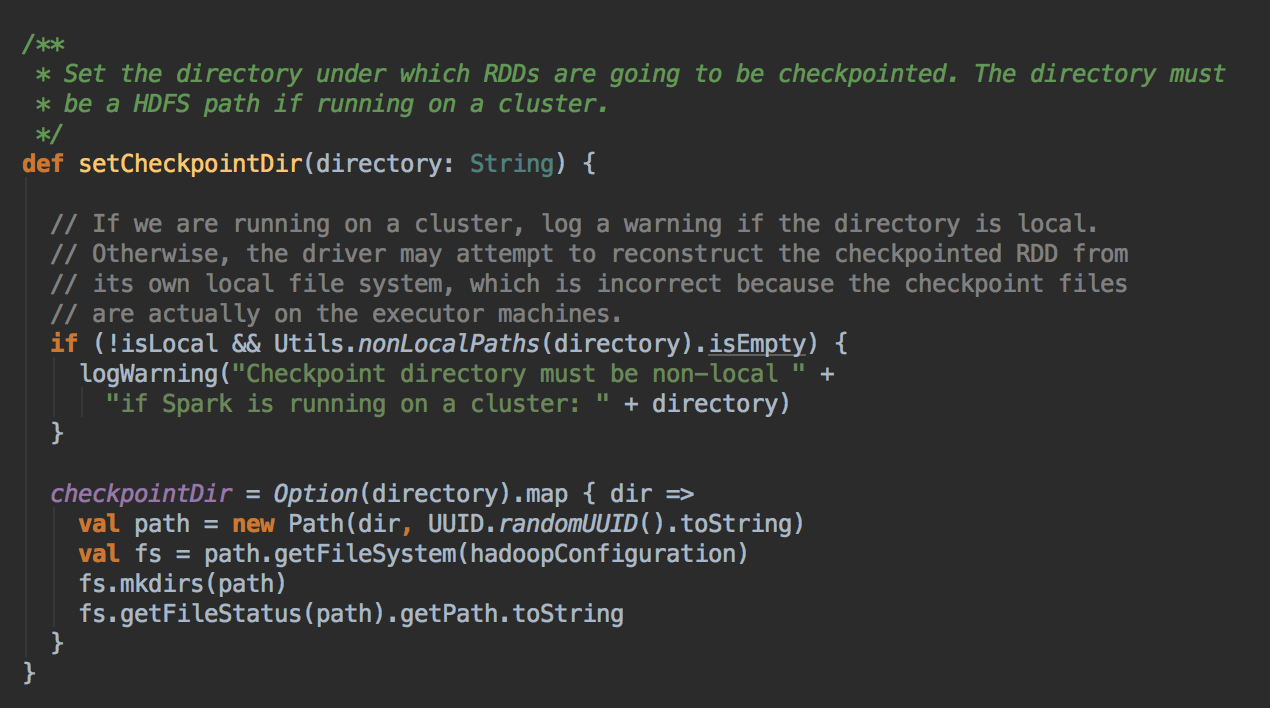
- 在进行 RDD 的 Checkpoint 的时候,其所依赖的所有 RDD 都会清空掉;官方建议如果要进行 checkpoint 时,必需先缓存在内存中。但实际可以考虑缓存在本地磁盘上或者是第三个组件,e.g. Taychon 上。在进行 checkpoint 之前需要通过 SparkConetxt 设置 checkpoint 的文件夹
[下图是 RDD.scala 中的 checkpoint 方法]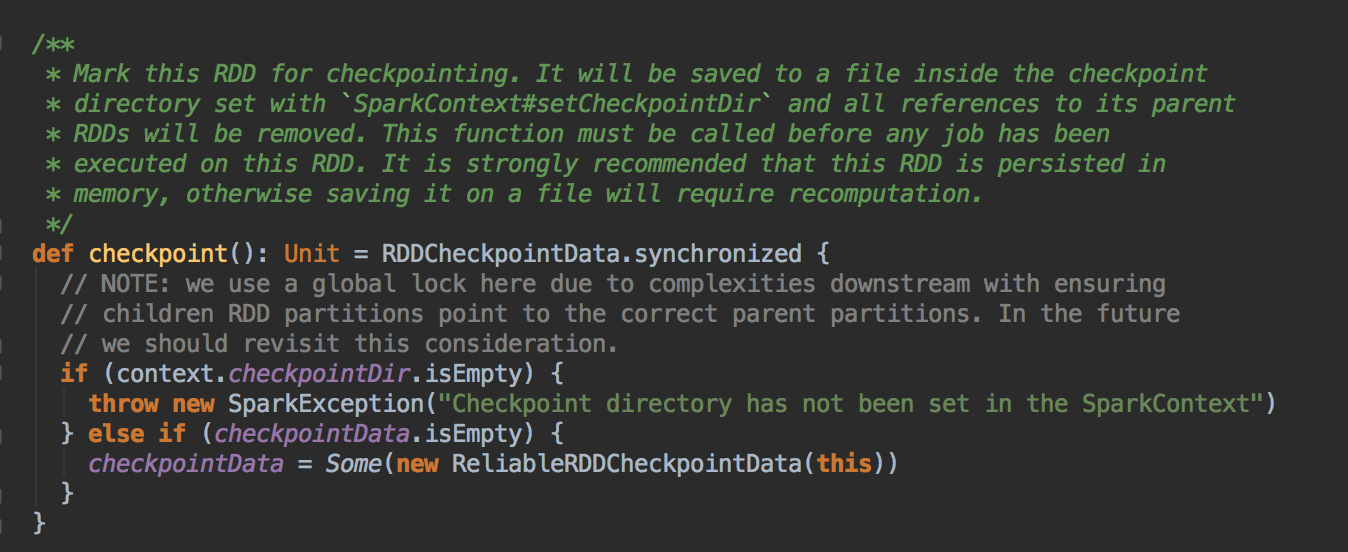
- 作为最住实际,一般在进行 checkpoint 方法调用前通过都要进行 persists 来把当前 RDD 的数据持久化到内存或者是上,这是因为 checkpoint 是 lazy 级别,必需有 Job 的执行且在Job 执行完成后才会从后往前回溯那个 RDD 进行了Checkpoint 标指,然后对该标记了要进行 Checkpoint 的 RDD 新启动一个Job 执行具体 Checkpoint 的过程;
- Checkpoint 改变了 RDD 的 Lineage
- 当我们调用了checkpoint 方法要对RDD 进行Checkpoint 操作的话,此时框架会自动生成 RDDCheckpointData

- 当 RDD 上运行一个Job 后就会立即解发 RDDCheckpointData 中的 checkpoint 方法,在其内部会调用 doCheckpoint( )方法,实际上在生产环境上会调用 ReliableRDDCheckpointData 的 doCheckpoint( )方法
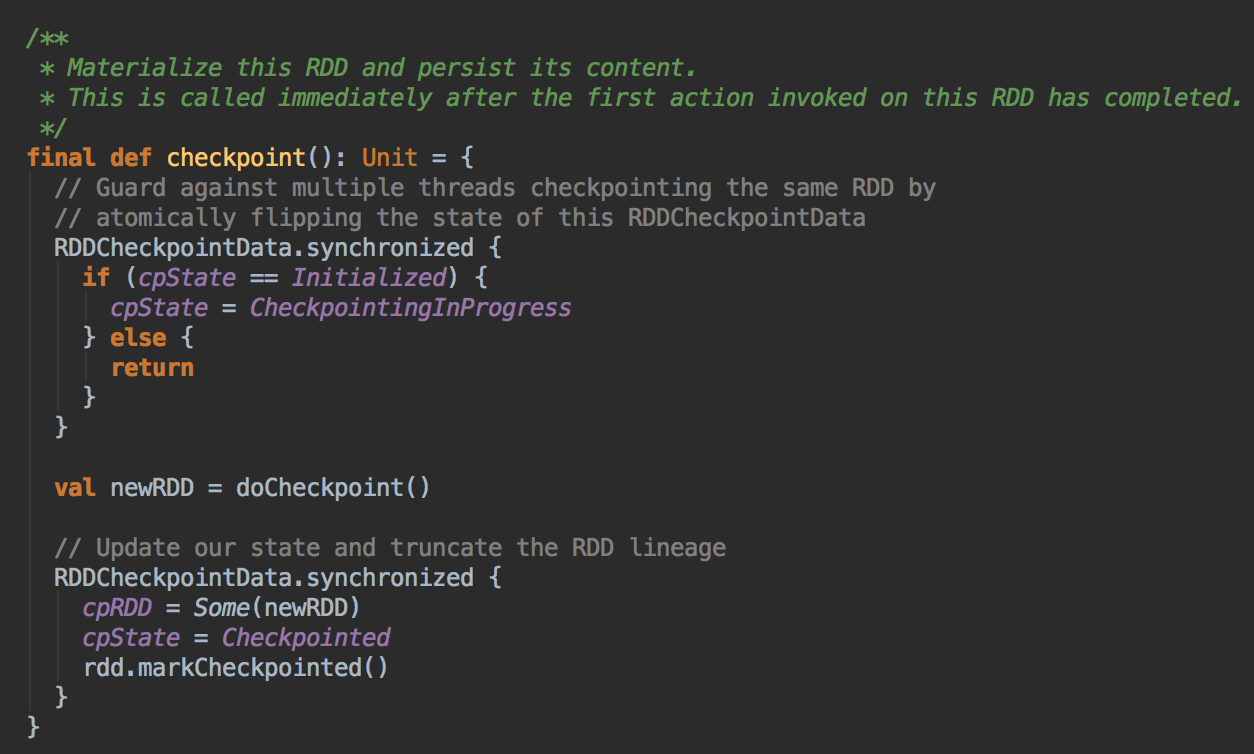
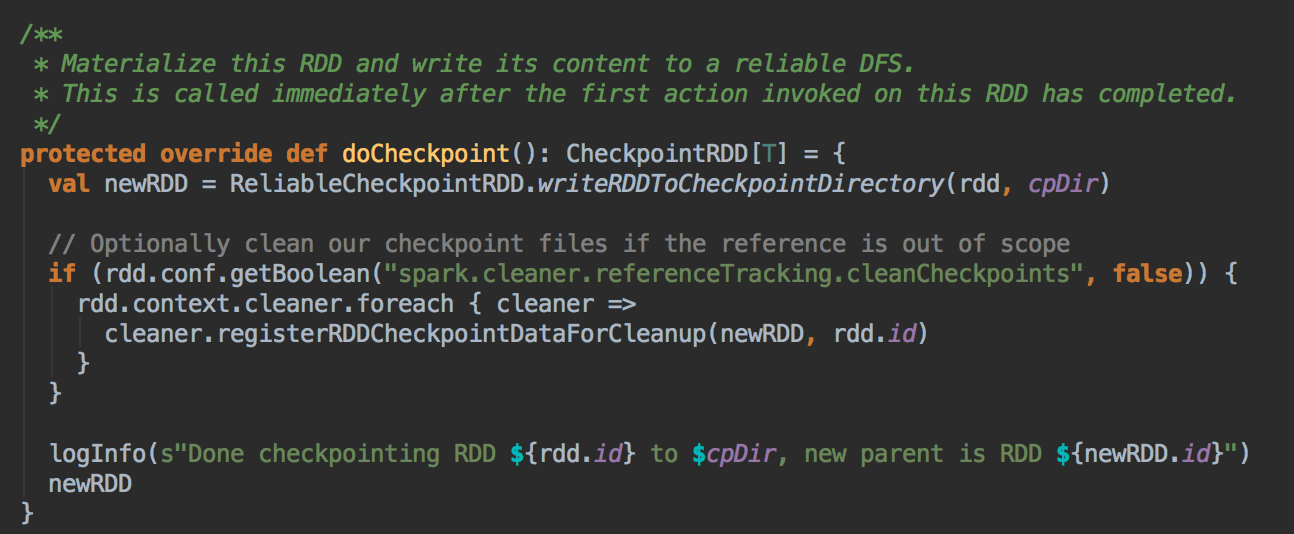
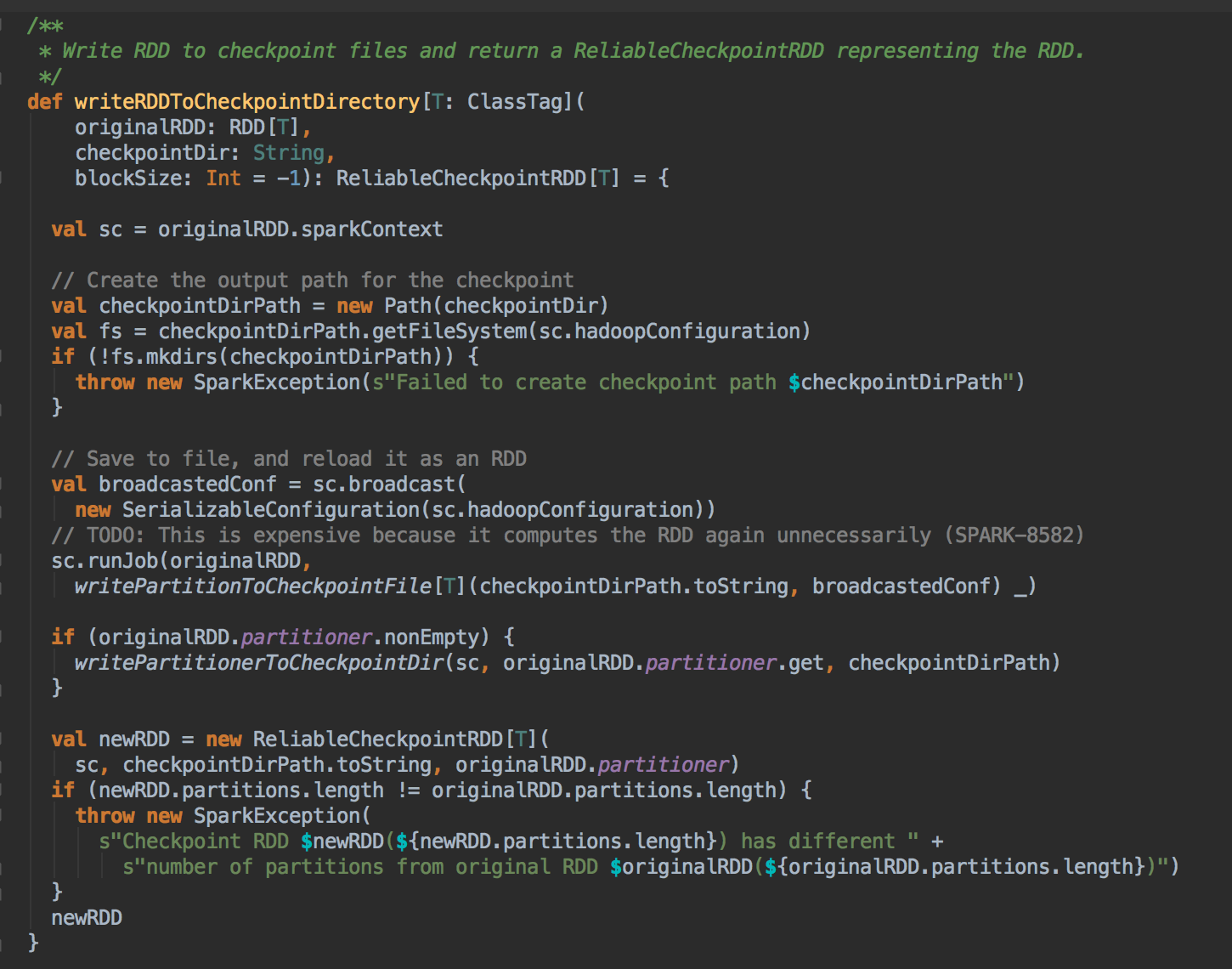
- 在生产环境下会导致 ReliableRDDCheckpointData 的 writeRDDToCheckpointDirectory 的调用,而在 writeRDDToCheckpointDirectory 方法内部会触发runJob 来执行当前的RDD 中的数据写到Checkpoint 的目录中,同时会产生ReliableCheckpointRDD 实例
參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第41课:Checkpoint彻底解密:Checkpoint的运行原理和源码实现彻底详解
Spark源码图片取自于 Spark 1.6.0版本
[Spark內核] 第41课:Checkpoint彻底解密:Checkpoint的运行原理和源码实现彻底详解的更多相关文章
- [Spark內核] 第42课:Spark Broadcast内幕解密:Broadcast运行机制彻底解密、Broadcast源码解析、Broadcast最佳实践
本课主题 Broadcast 运行原理图 Broadcast 源码解析 Broadcast 运行原理图 Broadcast 就是将数据从一个节点发送到其他的节点上; 例如 Driver 上有一张表,而 ...
- Checkpoint的运行原理和源码实现
引言 Checkpoint 到底是什么和需要用 Checkpoint 解决什么问题: Spark 在生产环境下经常会面临 Transformation 的 RDD 非常多(例如一个Job 中包含1万个 ...
- [Spark内核] 第40课:CacheManager彻底解密:CacheManager运行原理流程图和源码详解
本课主题 CacheManager 运行原理图 CacheManager 源码解析 CacheManager 运行原理图 [下图是CacheManager的运行原理图] 首先 RDD 是通过 iter ...
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
- [Spark内核] 第38课:BlockManager架构原理、运行流程图和源码解密
本课主题 BlockManager 运行實例 BlockManager 原理流程图 BlockManager 源码解析 引言 BlockManager 是管理整个Spark运行时的数据读写的,当然也包 ...
- Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本课主题 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 Spark Worke ...
- Spark Mllib里如何将trainDara训练数据的分类特征字段转换为数值字段(图文详解)
不多说,直接上干货! 字段3 是分类特征字段,但是呢,在分类算法里不能直接用.所以,必须要转换为数值字段才能够被分类算法使用. 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的 ...
- 第二十二课:js事件原理以及addEvent.js的详解
再看这篇博客之前,希望你已经对js高级程序编程一书中的事件模块进行了详读,不然我只能呵呵了. document.createEventObject,在IE下创建事件对象event. elem.fire ...
- Spark框架详解
一.引言 作者:Albert陈凯链接:https://www.jianshu.com/p/f3181afec605來源:简书 Introduction 本文主要讨论 Apache Spark 的设计与 ...
随机推荐
- Material使用01 侧边栏MdSidenavModule、工具栏MdTollbarModule
前提准备: 构建好一个Angular2应用 熟悉CSS的flex布局风格 1 利用flex进行布局 1.1 创建三个组件 app-header app-main app-footer 1.2 在主组件 ...
- 【LeetCode-面试算法经典-Java实现】【053-Maximum Subarray(最大子数组和)】
[053-Maximum Subarray(最大子数组和)] [LeetCode-面试算法经典-Java实现][全部题目文件夹索引] 原题 Find the contiguous subarray w ...
- B. Order Book(Codeforces Round #317 )
B. Order Book time limit per test 2 seconds memory limit per test 256 megabytes input standard input ...
- 《github一天一道算法题》:并归排序
看书.思考.写代码! /******************************************* * copyright@hustyangju * blog: http://blog.c ...
- ajax_get/post_两级联动
使用ajax实现菜单联动 通常情况下,GET请求用于从服务器上获取数据,POST请求用于向服务器发送数据. 需求:选择第一个下拉框的值,根据第一个下拉框的值显示第二个下拉框的值 首先使用GET方式. ...
- 为什么MOBA、“吃鸡”游戏不推荐用tcp协议——实测数据
欢迎大家前往云加社区,获取更多腾讯海量技术实践干货哦~ 作者:腾讯云游戏行业资深架构师 余国良 MOBA类和"吃鸡"游戏为什么对网络延迟要求高? 我们知道,不同类型的游戏因为玩法. ...
- Requests模块 HTTP for Humans
安装方式 $ pip install requests 基本GET请求(headers参数 和 parmas参数) 1.最基本的GET请求可以直接用get方法 response = requests. ...
- Ubuntu安装微信开发者工具
参考教程:https://ruby-china.org/topics/30339 1.下载nw sdk $ wget -c http://dl.nwjs.io/v0.15.3/nwjs-sdk-v0. ...
- 配置Meld为git的默认比较工具
1. 安装 meld sudo apt-get install meld 2. 创建 git_meld.sh 脚本 cd /bin vim git-meld.sh #!/bin/sh meld $2 ...
- 【java】扫描流Scanner接收输入示例
多用Scanner少用InputStream 多用BufferedReader少用Reader 多用PrintStream少用OutputStream 多用PrintWriter少用Writer pa ...