MySQL索引与Index Condition Pushdown
实际上,这个页面所讲述的是在MariaDB 5.3.3(MySQL是在5.6)开始引入的一种叫做Index Condition Pushdown(以下简称ICP)的查询优化方式。由于本身不是一个层面的东西,前文中说的是Index Access,而这里是Query Optimization,所以并不构成对前文正确性的影响。在写前文时,MySQL还没有ICP,所以文中没有涉及相关内容,但考虑到新版本的MariaDB或MySQL中ICP的启用确实影响了一些查询行为的外在表现。所以决定写这篇文章详细讲述一下ICP的原理以及对索引使用方式的优化。
实验
先从一个简单的实验开始直观认识ICP的作用。
安装数据库
首先需要安装一个支持ICP的MariaDB或MySQL数据库。我使用的是MariaDB 5.5.34,如果是使用MySQL则需要5.6版本以上。
Mac环境下可以通过brew安装:
- brew install mairadb
其它环境下的安装请参考MariaDB官网关于下载安装的文档。
导入示例数据
与前文一样,我们使用Employees Sample Database,作为示例数据库。完整示例数据库的下载地址为:https://launchpad.net/test-db/employees-db-1/1.0.6/+download/employees_db-full-1.0.6.tar.bz2。
将下载的压缩包解压后,会看到一系列的文件,其中employees.sql就是导入数据的命令文件。执行
- mysql -h[host] -u[user] -p < employees.sql
就可以完成建库、建表和load数据等一系列操作。此时数据库中会多一个叫做employees的数据库。库中的表如下:
- MariaDB [employees]> SHOW TABLES;
- +---------------------+
- | Tables_in_employees |
- +---------------------+
- | departments |
- | dept_emp |
- | dept_manager |
- | employees |
- | salaries |
- | titles |
- +---------------------+
- 6 rows in set (0.00 sec)
我们将使用employees表做实验。
建立联合索引
employees表包含雇员的基本信息,表结构如下:
- MariaDB [employees]> DESC employees.employees;
- +------------+---------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +------------+---------------+------+-----+---------+-------+
- | emp_no | int(11) | NO | PRI | NULL | |
- | birth_date | date | NO | | NULL | |
- | first_name | varchar(14) | NO | | NULL | |
- | last_name | varchar(16) | NO | | NULL | |
- | gender | enum('M','F') | NO | | NULL | |
- | hire_date | date | NO | | NULL | |
- +------------+---------------+------+-----+---------+-------+
- 6 rows in set (0.01 sec)
这个表默认只有一个主索引,因为ICP只能作用于二级索引,所以我们建立一个二级索引:
- ALTER TABLE employees.employees ADD INDEX first_name_last_name (first_name, last_name);
这样就建立了一个first_name和last_name的联合索引。
查询
为了明确看到查询性能,我们启用profiling并关闭query cache:
- SET profiling = 1;
- SET query_cache_type = 0;
- SET GLOBAL query_cache_size = 0;
然后我们看下面这个查询:
- MariaDB [employees]> SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';
- +--------+------------+------------+-----------+--------+------------+
- | emp_no | birth_date | first_name | last_name | gender | hire_date |
- +--------+------------+------------+-----------+--------+------------+
- | 254642 | 1959-01-17 | Mary | Botman | M | 1989-11-24 |
- | 471495 | 1960-09-24 | Mary | Dymetman | M | 1988-06-09 |
- | 211941 | 1962-08-11 | Mary | Hofman | M | 1993-12-30 |
- | 217707 | 1962-09-05 | Mary | Lichtman | F | 1987-11-20 |
- | 486361 | 1957-10-15 | Mary | Oberman | M | 1988-09-06 |
- | 457469 | 1959-07-15 | Mary | Weedman | M | 1996-11-21 |
- +--------+------------+------------+-----------+--------+------------+
根据MySQL索引的前缀匹配原则,两者对索引的使用是一致的,即只有first_name采用索引,last_name由于使用了模糊前缀,没法使用索引进行匹配。我将查询联系执行三次,结果如下:
- +----------+------------+---------------------------------------------------------------------------+
- | Query_ID | Duration | Query |
- +----------+------------+---------------------------------------------------------------------------+
- | 38 | 0.00084400 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- | 39 | 0.00071800 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- | 40 | 0.00089600 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- +----------+------------+---------------------------------------------------------------------------+
然后我们关闭ICP:
- SET optimizer_switch='index_condition_pushdown=off';
在运行三次相同的查询,结果如下:
- +----------+------------+---------------------------------------------------------------------------+
- | Query_ID | Duration | Query |
- +----------+------------+---------------------------------------------------------------------------+
- | 42 | 0.00264400 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- | 43 | 0.01418900 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- | 44 | 0.00234200 | SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man' |
- +----------+------------+---------------------------------------------------------------------------+
有意思的事情发生了,关闭ICP后,同样的查询,耗时是之前的三倍以上。下面我们用explain看看两者有什么区别:
- MariaDB [employees]> EXPLAIN SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+
- | 1 | SIMPLE | employees | ref | first_name_last_name | first_name_last_name | 44 | const | 224 | Using index condition |
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+
- 1 row in set (0.00 sec)
- MariaDB [employees]> EXPLAIN SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-------------+
- | 1 | SIMPLE | employees | ref | first_name_last_name | first_name_last_name | 44 | const | 224 | Using where |
- +------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-------------+
- 1 row in set (0.00 sec)
前者是开启ICP,后者是关闭ICP。可以看到区别在于Extra,开启ICP时,用的是Using index condition;关闭ICP时,是Using where。
其中Using index condition就是ICP提高查询性能的关键。下一节说明ICP提高查询性能的原理。
原理
ICP的原理简单说来就是将可以利用索引筛选的where条件在存储引擎一侧进行筛选,而不是将所有index access的结果取出放在server端进行where筛选。
以上面的查询为例,在没有ICP时,首先通过索引前缀从存储引擎中读出224条first_name为Mary的记录,然后在server段用where筛选last_name的like条件;而启用ICP后,由于last_name的like筛选可以通过索引字段进行,那么存储引擎内部通过索引与where条件的对比来筛选掉不符合where条件的记录,这个过程不需要读出整条记录,同时只返回给server筛选后的6条记录,因此提高了查询性能。
下面通过图两种查询的原理详细解释。
关闭ICP
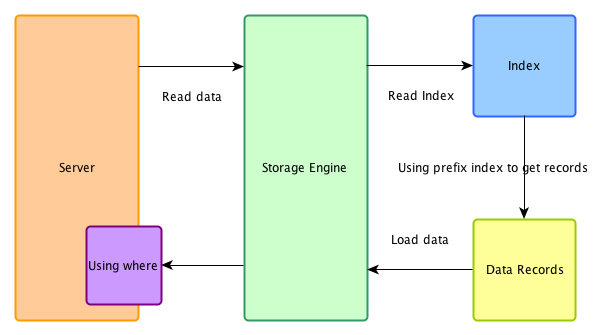
在不支持ICP的系统下,索引仅仅作为data access使用。
开启ICP
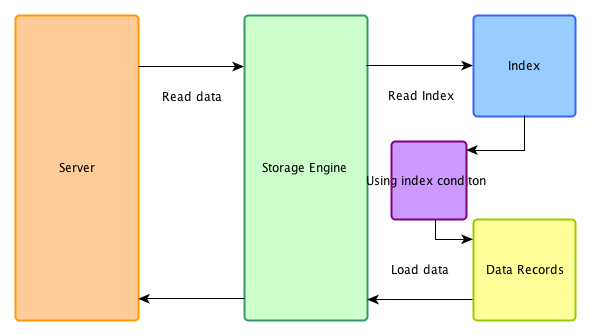
在ICP优化开启时,在存储引擎端首先用索引过滤可以过滤的where条件,然后再用索引做data access,被index condition过滤掉的数据不必读取,也不会返回server端。
注意事项
有几个关于ICP的事情要注意:
- ICP只能用于二级索引,不能用于主索引。
- 也不是全部where条件都可以用ICP筛选,如果某where条件的字段不在索引中,当然还是要读取整条记录做筛选,在这种情况下,仍然要到server端做where筛选。
- ICP的加速效果取决于在存储引擎内通过ICP筛选掉的数据的比例。
【参考资料】
1、http://blog.codinglabs.org/articles/index-condition-pushdown.html
MySQL索引与Index Condition Pushdown的更多相关文章
- MySQL索引与Index Condition Pushdown(二)
实验 先从一个简单的实验开始直观认识ICP的作用. 安装数据库 首先需要安装一个支持ICP的MariaDB或MySQL数据库.我使用的是MariaDB 5.5.34,如果是使用MySQL则需要5.6版 ...
- MySQL索引与Index Condition Pushdown(employees示例)
实验 先从一个简单的实验开始直观认识ICP的作用. 安装数据库 首先需要安装一个支持ICP的MariaDB或MySQL数据库.我使用的是MariaDB 5.5.34,如果是使用MySQL则需要5.6版 ...
- 浅析MySQL中的Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化
本文出处:http://www.cnblogs.com/wy123/p/7374078.html(保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错误 ...
- MySQL 查询优化之 Index Condition Pushdown
MySQL 查询优化之 Index Condition Pushdown Index Condition Pushdown限制条件 Index Condition Pushdown工作原理 ICP的开 ...
- 【mysql】关于Index Condition Pushdown特性
ICP简介 Index Condition Pushdown (ICP) is an optimization for the case where MySQL retrieves rows from ...
- MySQL 5.6 Index Condition Pushdown
ICP(index condition pushdown)是mysql利用索引(二级索引)元组和筛字段在索引中的where条件从表中提取数据记录的一种优化操作.ICP的思想是:存储引擎在访问索引的时候 ...
- MySQL ICP(Index Condition Pushdown)特性
一.SQL的where条件提取规则 在ICP(Index Condition Pushdown,索引条件下推)特性之前,必须先搞明白根据何登成大神总结出一套放置于所有SQL语句而皆准的where查询条 ...
- MySQL 中Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化
一.ICP优化原理 Index Condition Pushdown (ICP),也称为索引条件下推,体现在执行计划的上是会出现Using index condition(Extra列,当然Extra ...
- MySQL 优化之 ICP (index condition pushdown:索引条件下推)
ICP技术是在MySQL5.6中引入的一种索引优化技术.它能减少在使用 二级索引 过滤where条件时的回表次数 和 减少MySQL server层和引擎层的交互次数.在索引组织表中,使用二级索引进行 ...
随机推荐
- VUE实现请求数据
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- NOIP初赛 之 哈夫曼树
哈夫曼树 种根据我已刷的初赛题中基本每套的倒数第五或第六个不定项选择题就有一个关于哈夫曼树及其各种应用的题,占:0-1.5分:然而我针对这个类型的题也多次不会做,so,今晚好好研究下哈夫曼树: 概念: ...
- sublime Text 正则替换
我遇到一个文章,需要把所有的 (数字) 换为 [数字] 于是我使用 Sublime Text的替换 首先,我们需要打开正则使用"Alt+R" 或打开"Ctrl+h&quo ...
- putty 的美化
1. 中文乱码问题. 这个问题由来已久,每当我查看 mount到linux下的windows 中文目录的时候,都是一堆乱码, putty 也拒绝我输入中文, 一句话,这玩意,对中文过敏. ...
- 【NOIP2015提高组】 Day1 T3 斗地主
[题目描述] 牛牛最近迷上了一种叫斗地主的扑克游戏.斗地主是一种使用黑桃.红心.梅花.方片的A到K加上大小王的共54张牌来进行的扑克牌游戏.在斗地主中,牌的大小关系根据牌的数码表示如下:3<4& ...
- 【NOIP模拟】的士碰撞(二分答案)
Description
- eclipse创建一个文件夹
如何给eclipse创建一个文件夹,便于项目的管理:有时我们的eclipse中会有很多项目的,有的是公司的如Project1,Project2,Project3....还有的呢, 也可能是自己平时做的 ...
- css雪碧图(css splite)
将很多小的背景图片放在一起,可以减少http请求. 这些图片通常是一类的. 所以使用雪碧图. 雪碧图即为: 测试一下减少了多长时间 0 = 0
- Ubuntu on win10
大家看到这个题目应该都知道这个东西吧,或许也都知道咋安装啥的,我只是想分享一下自己安装它的过程同时可以对那些有需要的人给予帮助!!! 1. 打开开发者模式(如下图) 像上面这样打开开发人员模式,过程会 ...
- 视频加载logo
最近工作需要,收集了一些视频卡顿或加载时的透明PNG图片.