网络爬虫及openyxl模块
网络爬虫及openyxl模块
一、第三方模块简介
1.第三方模块的用处
python之所以在这么多的编程语言中脱颖而出的优点是有众多的第三方库函数,可以更高效率的实现开发
2.第三方模块的使用
1.第三方模块必须下载才能使用
格式:pip install 模块名 -i 源地址
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
2.可在终端借助pip工具下载
格式:
下载第三方模块的句式:pip install 模块名
下载第三方模块临时切换仓库的句式:pip install 模块名 -i 仓库地址
下载第三方模块指定版本(不指定默认是最新版):pip install 模块名 == 版本号 -i 仓库地址
注:在下载解释器pip解释器工具的时候,电脑上有多个版本的解释器时一定要注意到底用的是哪一个,在使用或者添加的时候一定要看清楚对应的版本号
3.在pycharm中也可以直接下载
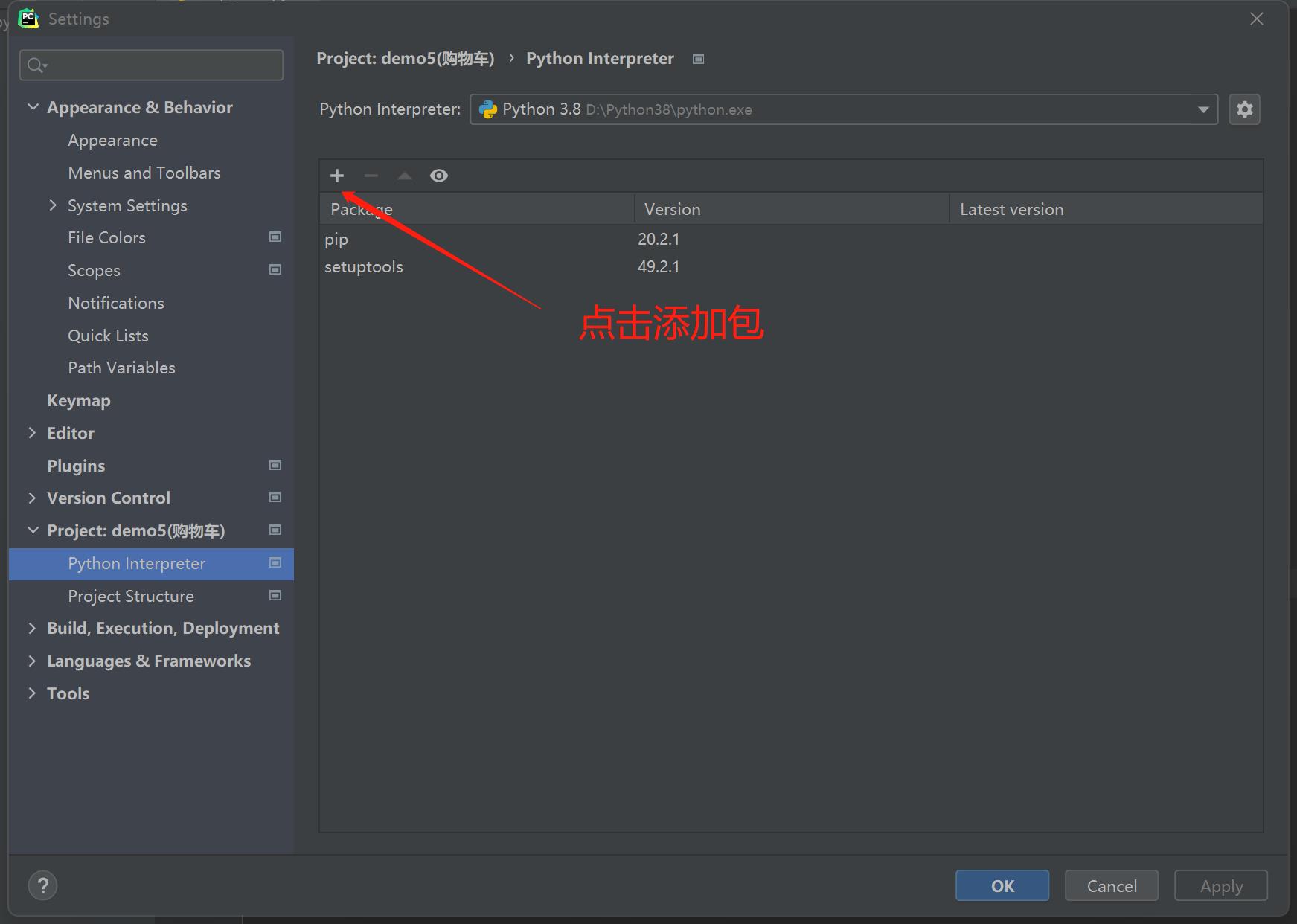
3.下载第三方模块的注意点
1.pip版本过低并有警告信息
# WARNING: You are using pip version 20.3.1;
原因是pip版本过低,只需要输入命令行更新模块就好了
python -m pip install --upgrade pip
2.报错含有Timeout关键字
说明当前计算机的网络不稳定,只需要换网或者程序执行几次即可
3.报错没有关键字
将关键字复制到百度进行搜索,然后进行解决
4.下载速度很慢
pip默认下载的仓库地址是国外的 python.org
我们可以切换下载的地址
pip install 模块名 -i 仓库地址
pip的仓库地址有很多 百度查询即可
二、网络爬虫基础实战
import requests
import re
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
res = requests.get('http://www.redbull.com.cn/about/branch', headers=headers)
data = res.text
res.encoding = 'utf-8' # 可以直接用utf-8对数据进行转码
with open(r'hn.html', 'wb') as f:
f.write(res.content)
# 1.获取所有的分公司名称
company_name_list = re.findall('<h2>(.*?)</h2>', data)
# 2.获取所有的分公司地址
company_addr_list = re.findall("<p class='mapIco'>(.*?)</p>", data)
# 3.获取所有的分公司邮箱
company_email_list = re.findall("<p class='mailIco'>(.*?)</p>", data)
# 4.获取所有的分公司电话
company_phone_list = re.findall("<p class='telIco'>(.*?)</p>", data)
# 5.将上述四个列表中的数据按照位置整合
res = zip(company_name_list, company_addr_list, company_email_list, company_phone_list)
# 6.处理数据(展示 保存 excel)
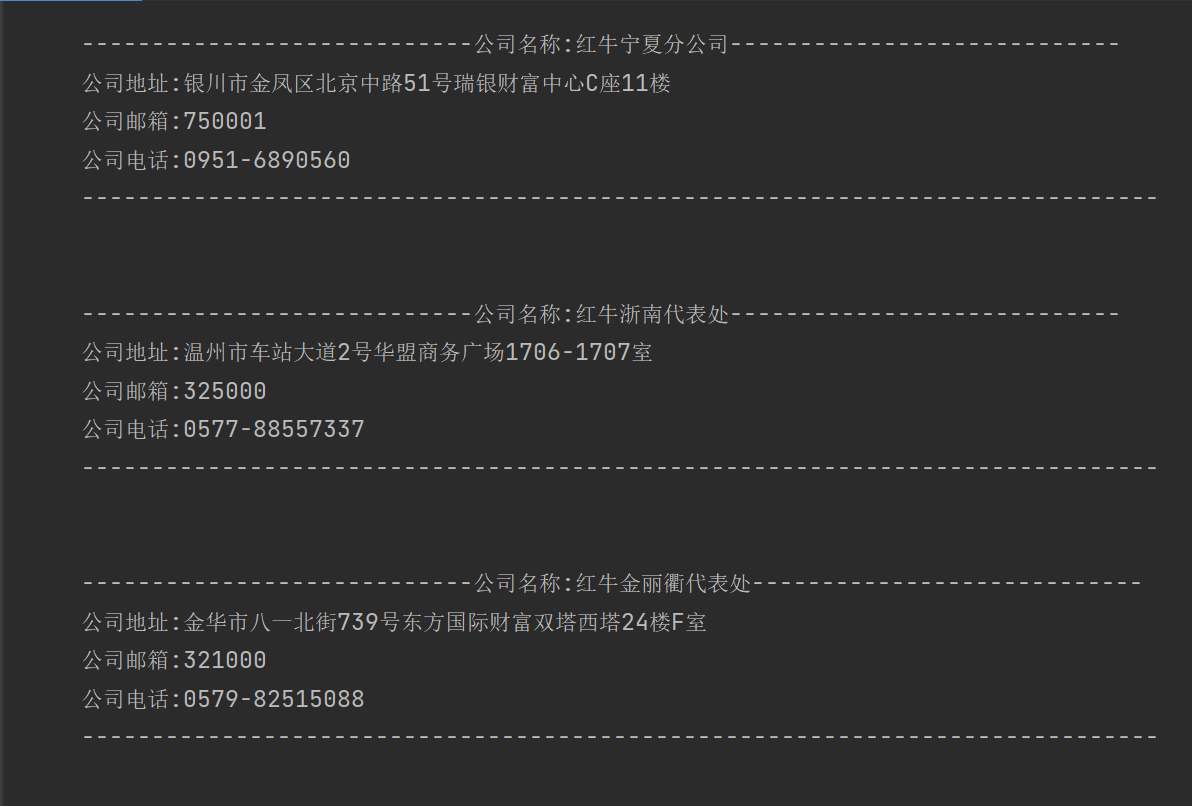
for i in res:
print("""
----------------------------公司名称:%s----------------------------
公司地址:%s
公司邮箱:%s
公司电话:%s
-----------------------------------------------------------------------------
""" % i)
三、openpyxl模块
1.openpyxl模块的作用
主要用于操作excel表格,实现自动化办公
2.Excel文件的后缀名的问题
03版本之前 ---->>> .xls
03版本之后 ---->>> .xlsx
3.操作excel表格的第三方模块
xlwt往表格写入数据、wlrd从表格读取数据
兼容性强
openpyxl最近几年比较火热的操作excel表格的模块
03版本之前的兼容性较差
实战:
from openpyxl import Workbook
user_excel = Workbook() # 创建excel
grades = user_excel.create_sheet('成绩表') #成绩表
physique = user_excel.create_sheet('体质表') #体质表
name = user_excel.create_sheet('姓名表',0) #姓名表
physique.title = '体能表'
name.sheet_properties.tabColor = '8B0000' #修改姓名表的颜色
# 第一种写入方式
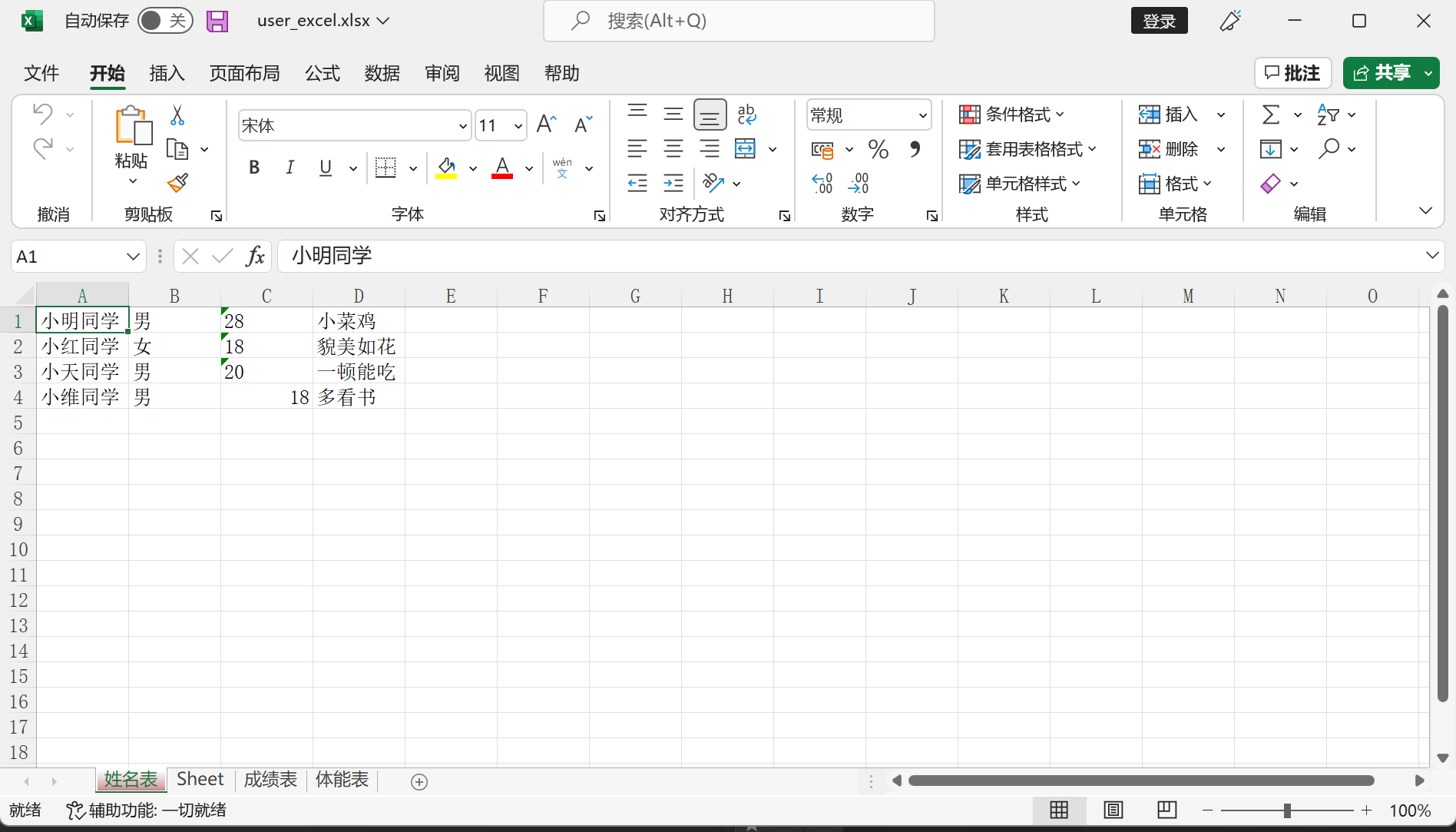
name['A1'] = '小明同学'
name['B1'] = '男'
# 第二种写入方式
name.cell(row=1, column=3, value='28')
name.cell(row=1, column=4, value='小菜鸡')
# 第三种写入方式(批量写入)
name.append(['小红同学', '女', '18', '貌美如花'])
name.append(['小天同学','男', '20', '一顿能吃'])
name.append(['小维同学', '男', 18, '多看书'])
user_excel.save(r'user_excel.xlsx') # 保存文件
网络爬虫及openyxl模块的更多相关文章
- 04.Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- 04,Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- 06.Python网络爬虫之requests模块(2)
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- Python网络爬虫之requests模块(2)
session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 有些时候,我们在使用爬 ...
- Python网络爬虫之requests模块
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- Python网络爬虫之BeautifulSoup模块
一.介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮 ...
- 网络爬虫之Selenium模块和Xpath表达式+Lxml解析库的使用
实际生产环境下,我们一般使用lxml的xpath来解析出我们想要的数据,本篇博客将重点整理Selenium和Xpath表达式,关于CSS选择器,将另外再整理一篇! 一.介绍: selenium最初是一 ...
- 网络爬虫之requests模块的使用+Github自动登入认证
本篇博客将带领大家梳理爬虫中的requests模块,并结合Github的自动登入验证具体讲解requests模块的参数. 一.引入: 我们先来看如下的例子,初步体验下requests模块的使用: ...
- 【网络爬虫入门03】爬虫解析利器beautifulSoup模块的基本应用
[网络爬虫入门03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.B ...
随机推荐
- 【lwip】07-链路层收发以太网数据帧源码分析
目录 前言 7.1 链路层概述 7.2 MAC地址的基本概念 7.3 以太网帧结构 7.4 以太网帧结构 7.5 以太网帧报文数据结构 7.6 发送以太网数据帧 7.7 接收以太网数据帧 7.8 虚拟 ...
- mybatis-增删改查和配置
加入log4j日志功能 加入依赖 <!-- log4j日志 --> <dependency> <groupId>log4j</groupId> < ...
- Vue 实现小小记事本
1.实现效果 用户输入后按回车,输入的内容自动保存,下方会显示记录的条数,鼠标移动到文字所在div上,会显示删除按钮,点击按钮,相应记录会被删除,下方的记录条数会相应变化,点击clear,所有记录会被 ...
- 解决“fast-forward, aborting”问题
1. 现象 对某一个远程仓库 git pull 过程中,报错如下: # zl @ srv123 in ~/git/radxa/kernel [14:09:54] $ git pull remote: ...
- [leetcode] 994. Rotting Oranges
题目 You are given an m x n grid where each cell can have one of three values: 0 representing an empty ...
- MediatRPC - 基于MediatR和Quic通讯实现的RPC框架,比GRPC更简洁更低耦合,开源发布第一版
大家好,我是失业在家,正在找工作的博主Jerry.作为一个.Net架构师,就要研究编程艺术,例如SOLID原则和各种设计模式.根据这些原则和实践,实现了一个更简洁更低耦合的RPC(Remote Pro ...
- JS基础笔记合集(1-3)
JavaScript合集 1. JS入门基础 2. JS数据类型 3. JS运算符 4. JS流程控制 5. JS对象 6. JS函数 7. JS面向对象 8. JS数组 9. JS内置对象 我追求理 ...
- 第2-4-10章 规则引擎Drools实战(3)-保险产品准入规则
目录 9.3 保险产品准入规则 9.3.1 决策表 9.3.2 规则介绍 9.3.3 实现步骤 9.3 保险产品准入规则 全套代码及资料全部完整提供,点此处下载 9.3.1 决策表 前面我们编写的规则 ...
- 《不一般的 DFT》阅读随笔
感觉上前置知识是毛啸 16 年的论文? 我手头也有,到时候发现有 at 到的地方就插一嘴说一句 srds 先这篇是因为有纸质版的这篇 感觉上大篇幅在讲复杂度模数大小相关的做法. 1 引言 我这写个啥? ...
- Zabbix技术分享——docker组件编译使用教程
docker是一个开源的应用容器引擎,基于Go语言并遵从Apache2.0协议开源,它可以让开发者打包他们的应用以及依赖包到一个轻量级.可移植的容器中,然后发布到任何流行的Linux机器上,还可以实现 ...