scrapy框架爬取豆瓣读书(1)
1.scrapy框架
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
主要组件:

2.快速开始
scrapy startproject douban
cd到douban根目录下执行 scrapy genspider Douban book.douban.com
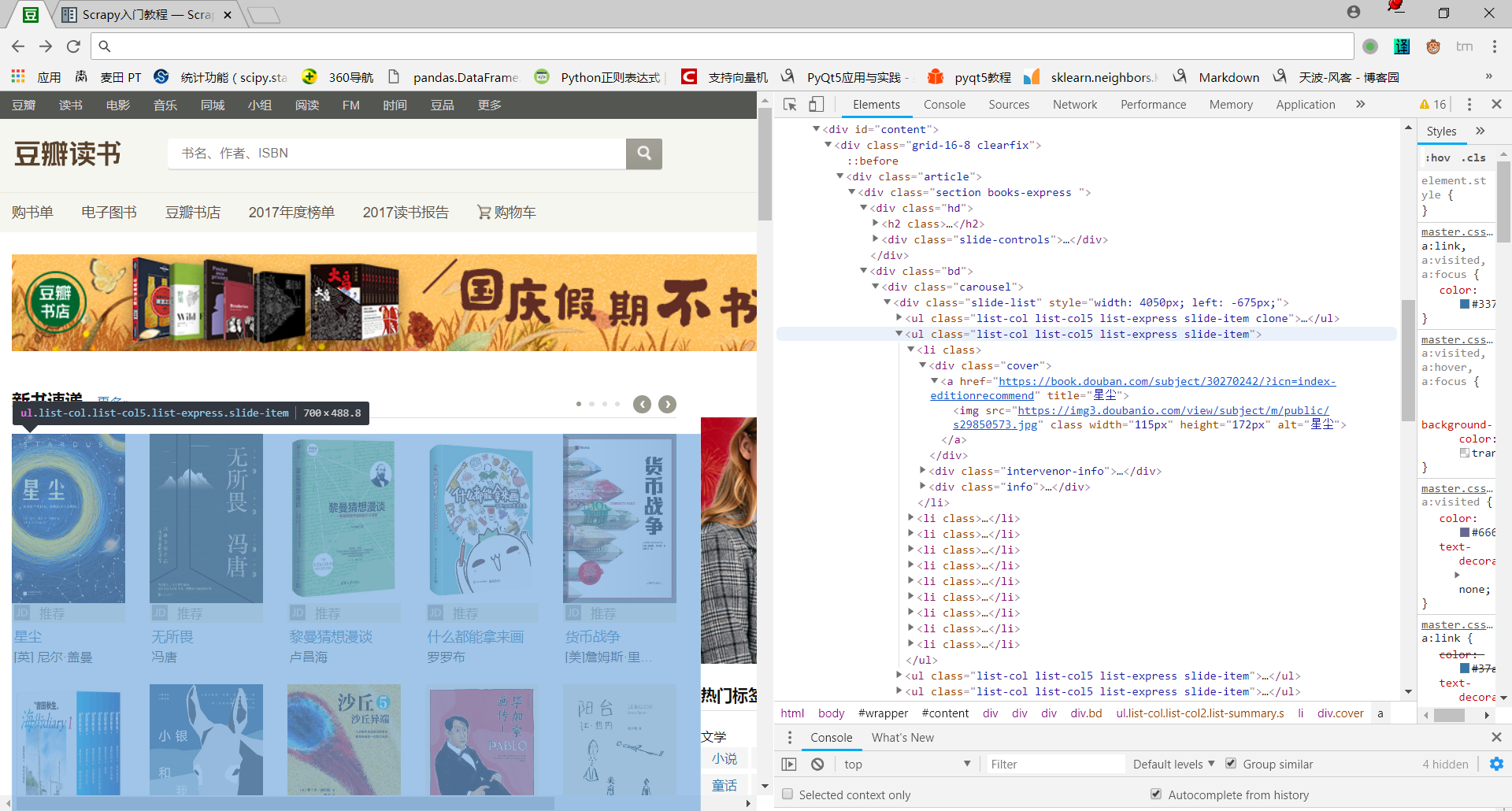
原网页结构
3.xpath提取
xpath是基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。
xpath初探:
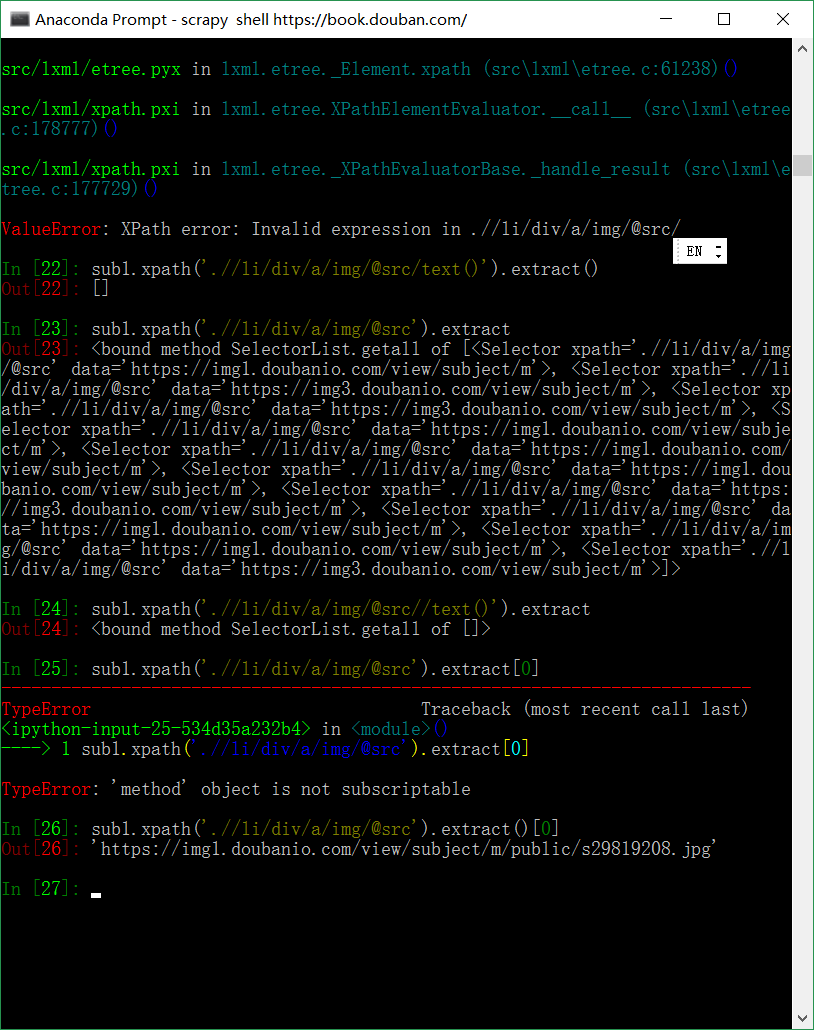
提取书籍排行榜图片链接,以备后续保存
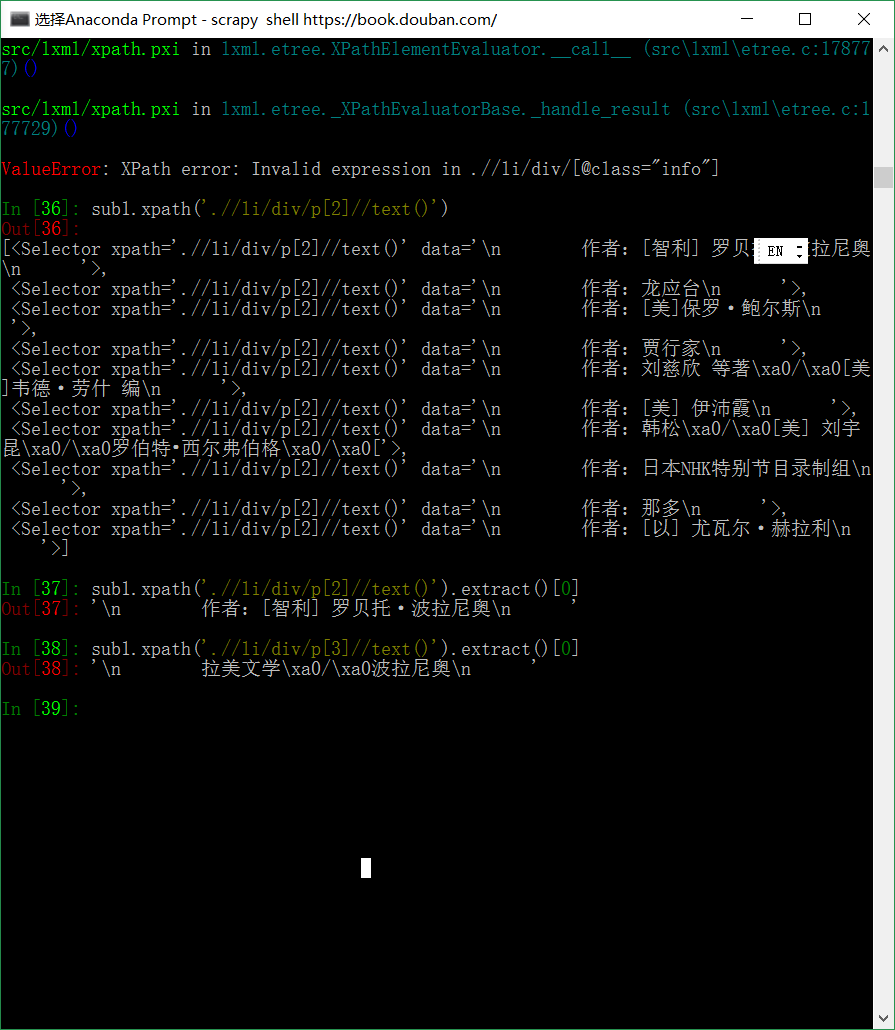
提取作者,所在地区
4.Douban.py代码
import scrapy
from douban.items import DoubanBookItem
class BookSpider(scrapy.Spider):
name = 'douban-book'
allowed_domains = ['douban.com']
start_urls = [
'https://book.douban.com'
]
def parse(self, response):
# 请求第一页
yield scrapy.Request(response.url, callback=self.parse_next)
#爬取其他页面
for page in response.xpath('//div[@class="paginator"]/a'):
link = page.xpath('@href').extract()[0]
yield scrapy.Request(link, callback=self.parse_next)
def parse_next(self, response):
for item in response.xpath('//tr[@class="item"]'):
book = DoubanBookItem()
book['name'] = item.xpath('td[2]/div[1]/a/@title').extract()[0]
book['content'] = item.xpath('td[2]/p/text()').extract()[0]
book['ratings'] = item.xpath('td[2]/div[2]/span[2]/text()').extract()[0]
yield book
5.明天继续更新items.py、pipelines(管道数据流)、middlewaares(中间件)编写

scrapy框架爬取豆瓣读书(1)的更多相关文章
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- python scrapy框架爬取豆瓣
刚刚学了一下,还不是很明白.随手记录. 在piplines.py文件中 将爬到的数据 放到json中 class DoubanmoviePipelin2json(object):#打开文件 open_ ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- 使用scrapy框架爬取自己的博文(3)
既然如此,何不再抓一抓网页的文字内容呢? 谷歌浏览器有个审查元素的功能,就是按树的结构查看html的组织形式,如图: 这样已经比较明显了,博客的正文内容主要在div 的class = cnblogs_ ...
随机推荐
- 用jsp开发web应用并不是一个高效率的选择
1. Android里有办法让js使用java方法像使用自己的方法一样方便,和flex的很相似,flex里面使用java方法就像使用自己的方法一样. 2. 用Flex开发准确的说就是用as ...
- Netty源码学习(六)ChannelPipeline
0. ChannelPipeline简介 ChannelPipeline = Channel + Pipeline,也就是说首先它与Channel绑定,然后它是起到类似于管道的作用:字节流在Chann ...
- 前台vue的使用简单小结
前台vue的使用简单小结 本项目要求:安装有node.js 6.0以及以上安装npm使用vue.js官方安装方法初始化项目npm install安装VueResurce:npm install vue ...
- hdu6053
hdu6053 题意 给出 \(A\) 数组,问有多少种 \(B\) 数组满足下面条件. \(1≤ B_i ≤ A_i\) For each pair \(( l , r ) \ (1≤l≤r≤n) ...
- #423 Div2 C
#423 Div2 C 题意 给出 n 个字符串以及他们在 S 串中出现的位置,求字典序最小的 S 串.保证给出的字符串不会冲突. 分析 模拟就好.用并查集思想优化,数组 nxt[i] 表示从 i 开 ...
- Codeforces 1010D Mars rover
题目大意:对于一个不完全二分图,根节点为1,叶节点值为0或1,非叶节点包含一个操作(and,or,xor,not),求改变各个叶节点的值时(即0改为1,1改为0),根节点的值是多少 解法:遍历图求各节 ...
- 线段树【p1607】[USACO09FEB]庙会班车Fair Shuttle
Description 逛逛集市,兑兑奖品,看看节目对农夫约翰来说不算什么,可是他的奶牛们非常缺乏锻炼--如果要逛完一整天的集市,他们一定会筋疲力尽的.所以为了让奶牛们也能愉快地逛集市,约翰准备让奶牛 ...
- Qt如何学习(参考官方文档)
Designers who are familiar with web development can start with QML 一共有四种安装工具 You have following opti ...
- [LOJ6208]树上询问
题目大意: 有一棵n节点的树,根为1号节点.每个节点有两个权值ki,ti,初始值均为0. 给出三种操作: 1.Add(x,d)操作:将x到根的路径上所有点的ki←ki+d 2.Mul(x,d)操作:将 ...
- Codeforces Round #535 (Div. 3) [codeforces div3 难度测评]
hhhh感觉我真的太久没有接触过OI了 大约是前天听到JK他们约着一起刷codeforces,假期里觉得有些颓废的我忽然也心血来潮来看看题目 今天看codeforces才知道居然有div3了,感觉应该 ...