[MIT6.006] 7. Counting Sort, Radix Sort, Lower Bounds for Sorting 基数排序,基数排序,排序下界
在前6节课讲的排序方法(冒泡排序,归并排序,选择排序,插入排序,快速排序,堆排序,二分搜索树排序和AVL排序)都是属于对比模型(Comparison Model)。对比模型的特点如下:
- 所有输入items是黑箱(ADTs, Abstract Data Types);
- 允许的操作只有对比(<,≤,>,≥,=);
- 时间消耗 = #对比。
之前绝大部分的对比模型是以决策树的结构出现的,这是因为任何对比模型都可以被认做所有可能对比、它们的结果和答案下的一棵树(原话:Decision Tree: any comparison algorithm can be viewed as a tree of all possible comparisons and their outcomes, and resulting answer.)
例如下图的二分查找树:
对比决策树结构和算法本身,它们各成分的对应情况如下:
问:查找最低下限是多大呢?
答:在n个预处理的items中, 用对比模型查找到指定的item,最坏情况下是Ω(log2n)。因为对比模型为决策树且它为2分结构(binary),另外由上面举例的二分查找树也能发现叶子节点数一定是 ≥n 的,因此树的高度h ≥ log2n。
问:排序最低下限是多大呢?
答:Ω(nlog2n),原因见下图:
扩展(资料来源:https://www.cnblogs.com/jin-nuo/p/5293554.html):
就时间复杂度而言,排序分以下为四类:
| 排序分类 | 排序方法 |
| 平方阶O(n2) | 直接插入、直接选择和冒泡排序 |
| 线性对数阶O(nlog2n) | 快速排序、堆排序、归并排序,BST排序和AVL排序 |
| O(n1+§),§是介于0和1之间的常数 | 希尔排序(还没讲到) |
| 线性阶O(n) | 基数排序 |
这节课的重点就是讲解线性阶时间复杂度的基数排序,在此之前,我们先了解下线性排序(Linear-time Sorting, integer sorting):
- 假设n个键排序是整型,其属于{0, 1, ..., k-1}(每个跟一个word刚好合配,这里的word相当于一个内存地址似的概念);
- 除了对比,可以做其他操作;
- 对于k,可以排序的时间复杂度为O(n)。
讲师讲了两个线性排序:计数排序(Counting Sort)和基数排序(Radix Sort)。
一、计数排序(Counting Sort)
个人感觉计数排序就是顺序字典计数 + 顺序输出。具体例子可以参考下:https://www.cnblogs.com/kyoner/p/10604781.html

二、计数排序(Radix Sort)
由于课程时间剩下不多,讲师没有详细展开这块内容,但要理解并不太难,首先,我引用博文https://blog.csdn.net/wolinxuebin/article/details/7488280的例子讲解下主要思路,基数排序的例子如下:
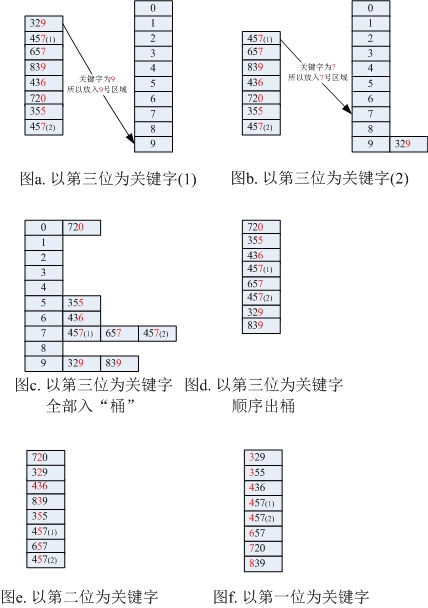
如果待排数组为[329, 457, 657, 839, 436, 720, 355, 457],假设这里采用低位优先排序方式(Least significant digital, LSD)进行排序:
- 由于待排数组中元素各位上的最大值不超过10, 那么这里建个10个桶[0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
- 以个位数字为桶编号依次入桶,全部入桶后再全部顺序出桶;
- 以十位数字为桶编号依次入桶,全部入桶后再全部顺序出桶;
- 以百位数字为桶编号依次入桶,全部入桶后再全部顺序出桶;
- 完毕。
上面提到的低位优先排序方式LSD是以个位->十位->百位的顺序,而还有个高位优先排序方式(Most significant digital, MSD)是从百位->十位->个位。时间复杂度的计算:假设有n个d位数,每位数有k种(例如像上面的例子,每位数的范围是0-9,则k=10)则时间复杂度为Ο((n + k) x d) (注:n指分配n个数要n次,k指构建k个桶,d为低位/高位优先排序次数,即位数)。
[MIT6.006] 7. Counting Sort, Radix Sort, Lower Bounds for Sorting 基数排序,基数排序,排序下界的更多相关文章
- [MIT6.006] 6. AVL Trees, AVL Sort AVL树,AVL排序
之前第5节课留了个疑问,是关于"时间t被安排进R"的时间复杂度能不能为Ο(log2n)?"和BST时间复杂度Ο(h)的关系.第6节对此继续了深入的探讨.首先我们知道BST ...
- [MIT6.006] 4. Heaps and Heap Sort 堆,堆排序
第4节课仍然是讲排序,但介绍的是一种很高效的堆排序. 在编程过程中,有时候会需要进行extrat_max的操作,即从一个数列里挨个抽取最大值并将其它从原数列中移除.而排序问题也可以看作是一个extra ...
- [MIT6.006] 3. Insertation Sort, Mege Sort 插入排序,归并排序
关于第2节课<Models of Computation, Document Distance>由于内容过于简单,所以不在这里进行记录,它主要就是讲了Python很多操作是constant ...
- 基数排序(radix sort)
#include<iostream> #include<ctime> #include <stdio.h> #include<cstring> #inc ...
- [Algorithms] Radix Sort
Radix sort is another linear time sorting algorithm. It sorts (using another sorting subroutine) the ...
- 经典排序算法 - 基数排序Radix sort
经典排序算法 - 基数排序Radix sort 原理类似桶排序,这里总是须要10个桶,多次使用 首先以个位数的值进行装桶,即个位数为1则放入1号桶,为9则放入9号桶,临时忽视十位数 比如 待排序数组[ ...
- Radix Sort
为了完成二维数据快速分类,最先使用的是hash分类. 前几天我突然想,既然基数排序的时间复杂度也不高,而且可能比hash分类更稳定,所以不妨试一下. 在实现上我依次实现: 1.一维数组基数排序 基本解 ...
- 排序算法七:基数排序(Radix sort)
上一篇提到了计数排序,它在输入序列元素的取值范围较小时,表现不俗.但是,现实生活中不总是满足这个条件,比如最大整形数据可以达到231-1,这样就存在2个问题: 1)因为m的值很大,不再满足m=O(n) ...
- 基数排序(Radix Sort)
基数排序(Radix Sort) 第一趟:个位 收集: 第二趟:十位 第三趟:百位 3元组 基数排序--不是基于"比较"的排序算法 递增就是把收集的过程返过来 算法效率分析 需要r ...
随机推荐
- oracle 11g linux 导入中文字符乱码问题解决
1. 涉及的字符集 这个可以分成三块,数据库服务器字符集(server).实例字符集(instance), 会话字符集(session) 2. 乱码的原因 session 的字符集和 server 的 ...
- AMBuild
什么是AMBuild? AMBuild是构建软件项目和创建发布包的工具.它是针对C++项目的,当然也可以用于其它任何语言的项目,它主要针对解决大多数构建工具所解决不了的三个大问题: 1.准确性:不需要 ...
- python的PEP8代码规范
一.缩进:每级缩进用4个空格.如果缩进不正确或缩进格式不统一,一般错误信息会明确告诉你,但有时也会出现invalid syntax报错.所谓缩进不正确,python的缩进是四个空格或一个TAB,如果缩 ...
- 多测师讲解自动化测试 _如何解决验证码的问题_高级讲师肖sir
自动化测试如何解决验证码的问题对于web应用来说,大部分的系统在用户登录时都要求用户输入验证码,验证码的类型的很多,有字母数字的,有汉字的,甚至还要用户输入一条算术题的答案的,对于系统来说使用验证码可 ...
- K8S节点异常怎么办?TKE"节点健康检查和自愈"来帮忙
节点健康检测 意义 在K8S集群运行的过程中,节点常常会因为运行时组件的问题.内核死锁.资源不足等各种各样的原因不可用.Kubelet默认对节点的PIDPressure.MemoryPressure. ...
- 资源管理神器Clover
开开心心地上班,这时你得打开我的电脑,点进D盘,打开某个项目;然后还得打开XX文档,还有.... 最后的最后,你的桌面便成了这个样子 每天你都得天打开多个文件夹,切换时找文件找的晕头转向而烦恼. 每天 ...
- 调试与优化:一次数据中心看板 T+1 改 T+0 优化过程
背景 团队目前在做一个用户数据看板(下面简称看板),基本覆盖用户的所有行为数据,并生成分析数据,用户行为数据来源于多个数据源(餐饮.生活日用.充值消费.交通出行.通讯物流.交通出行.医疗保健.住房物业 ...
- php 数组与URL相互转换
php为了数组与url参数相互转换提供了两个函数: 1,数组转换为带&的URL的字符串 例如: $arr =['title'=>'我是小白','name'=>'真的很白','tex ...
- centos8平台用ffprobe获取视频文件信息(ffmpeg4.2.2)
一,ffprobe的作用 ffprobe是强大的视频分析工具, 用于从多媒体流中获取相关信息或查看文件格式信息, 并以可读的方式打印 说明:刘宏缔的架构森林是一个专注架构的博客,地址:https:// ...
- centos8平台使用ip命令代替ifconfig管理网络
一,为什么建议使用ip命令代替ifconfig? 1,ifconfig所属的net-tools包已经不再被维护了 虽然可以用,但会发生看不到部分ip等情况, [root@centos8 liuhong ...