hadoop伪分布式平台组件搭建
第一部分:系统基础配置
系统基础配置中主完成了安装大数据环境之前的基础配置,如防火墙配置和安装MySQL、JDK安装等
第一步:关闭防火墙
Hadoop与其他组件的服务需要通过端口进行通信,防火墙的存在会阻拦这些访问,在初学阶段建议将防火墙全部 关闭,命令如下。
systemctl stop firewalld.service
vi /etc/selinux/config #
Selinux策略 SELINUX=disabled #更改为disabled关闭状态
第二步:安装JDK
JDK安装包已经定制在环境当中的“/usr/local”目录中,直接使用即可
cd /usr/local/
rpm -ivh jdk-8u144-linux-x64.rpm
java -version
第三步:安装MySQL
由于Hive数据仓库需要使用MySQL作为元数据库,所以在基础环境配置过程中我们需要安装MySQL安装过程如下
(1)安装mysql,命令如下。
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql57-community-release-el7-10.noarch.rpm #安装MySQL服务器
yum -y install mysql-community-server
systemctl start mysqld.service
(2)MySql5.7安装完成后会有一个初始密码必须使用初始密码登录,并修改初始密码后才能够使用该数据库,查 看数据库默认密码命令如下所示。
cat /var/log/mysqld.log | grep 'password'
密码格式:
root@localhost: XXXXX
(3)修改默认密码设置新密码,新密码简单容易记忆即可,生产环境下要严格按照要求设置,修改密码命令如下 所示。
[root@master ~]# mysql -uroot –p #使用默认密码登陆mysql
#密码共有三个级别0:只检查长度,1:检查长度、数字、大小写,2:检查长度、数字、大小写、特殊字符字典文件
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4; #设置密码最小长度
mysql> set password='123456'; #将密码设置为123456
(3)配置数据库远程连接,一般情况下操作数据库不不会到服务器环境下操作,通常会使用远程连接,配置可远 程连接命令如下所示。
grant all privileges on *.* to 'root'@'%'identified by '123456' with grant option;
第二部分:Hadoop分布式系统配置
本案例主要讲解的是Hadoop生态体系的搭建,因为其他组件会使用到HDFS做存储如Hive等,所以搭建大数据环 境时首先需要部署Hadoop。
第一步:解压安装包
Hadoop安装包已经定制到环境中的“/usr/local”目录下,解压并将解压后的文件名称重命名为Hadoop,命令如 下。
tar zxvf hadoop-2.7.2.tar.gz
mv hadoop-2.7.2 hadoop
第二步:配置文件修改
(1)进入/hadoop/etc/hadoop目录并修改hadoop-env.sh配置文件,添加配置JDK的安装目录,命令如下所示
cd ./hadoop/etc/hadoop/
vi hadoop-env.sh #在该配置文件的export JAVA_HOME处输入如下内容
/usr/java/jdk1.8.0_144
(2)在当前目录下打开core-site.xml配置文件,在该配置文件中设置集群名称并配置HDFS端口以及临时文件存储 目录,命令如下。
vi core-site.xml
#在该配置文件的<configuration>标签中输入如下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
(3)在当前目录下打开hdfs-site.xml配置文件,在该配置文件中配置HDFS文件的副本数、原数据的保存位置和数 据保存路径,命令如下所示。
vi hdfs-site.xml
#在该配置文件的<configuration>标签中输入如下内容
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
(4)在当前目录下复制mapred-site.xml.template配置模板文件并重命名为mapred-site.xml,并在mapredsite.xml配置文件中修改mapreduce程序的运行参数,命令如下。
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
#在该配置文件的<configuration>标签中输入如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)在当前目录下打开yarn-site.xml配置文件,在该配置文件中设置运行ResourceManager机器所在的节点位置 和配置成mapreduce_shuffle,命令如下。
vi yarn-site.xml
#在该配置文件的<configuration>标签中输入如下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
第三步:启动Hadoop
配置Hadoop环境变量,并格式化namenode,最后启动Hadoop进程,命令如下所示。
vi ~/.bashrc
#在该配置文件末尾添加如下内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
(7)配置Hadoop环境变量,并格式化namenode,最后启动Hadoop进程,命令如下所示。
vi ~/.bashrc
#在该配置文件末尾添加如下内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
hadoop namenode -format start-all.sh
jps
第三部分:HBase配置
第一步:解压安装包
HBase安装包已经定制到环境中的“/usr/local”目录下,解压并将解压后的文件名称重命名为HBase,命令如下。
tar -zxvf hbase-1.2.6-bin.tar.gz
mv hbase-1.2.6 hbase
第二步:配置文件修改
(1)进入HBase根目录下的conf目录中,修改hbase-env.sh配置文件,在该文件中配置Java的环境变量,设置日 志输出路径等,命令如下。
cd ./hbase/conf/
vi hbase-env.sh #将如下内容输入到配置文件中
export JAVA_HOME=/usr/java/jdk1.8.0_144
export HBASE_MANAGES_ZK=true
export HBASE_LOG_DIR=/usr/local/hbase/hbase-logs
(2)在当前目录下,打开hbase-site.xml配置文件,在该文件中设置持久保存目录、设置是否为分布式、 zookeeper数据目录等,命令如下。
vi hbase-site.xml
#在该配置文件的<configuration>标签中输入如下内容
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/hbase/zk_data</value>
</property>
第三步:启动HBase
配置HBase环境变量,然后启动HBase进程并使用jps命令查看进程是否启动成功,命令如下。
vi ~/.bashrc
#在配置文件末尾输入如下内容
export HBASE_HOME=/usr/local/hbase
export PATH=$HBASE_HOME/bin:$PATH
source ~/.bashrc start-hbase.sh
jps
##第四部分:Hive分布式数据仓库配置
第一步:解压安装包
Hive安装包已经定制到了“/usr/local”目录下,将其解压并重命名为hive,命令如下。
tar -zxvf apache-hive-2.2.0-bin.tar.gz
mv apache-hive-2.2.0-bin hive
第二步:修改配置文件
进入Hive安装目录中的conf目录,复制配置模板文件hive-default.xml.template,并将其重命名为hive-site.xml后 对其进行修改,修改hive-site.xml时需要根据给出配置在配置文件重查找进行修改,命令如下所示。
cd ./hive/conf/
cp ./hive-default.xml.template hive-site.xml
vi hive-site.xml #在配置文件中找到对应位置修改如下内容
<property>
<name>hive.exec.scratchdir</name> #设置HDFS路径
<value>/usr/local/hive/iotmp/hive</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name> #远程文件系统中添加资源的临时本地目录
<value>/usr/local/hive/iotmp<value>
</property>
<property>
<name>hive.exec.local.scratchdir</name> #作业的本地暂存空间
<value>/usr/local/hive/iotmp</value>
</property>
<property>
<name>hive.querylog.location</name> #运行时结构的日志文件位置
<value>/usr/local/hive/iotmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name> #设置hive数据库和表在HDFS中存放的文件夹的位置
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.server2.thrift.port</name> #设置HiveServer2远程连接的端口
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name> #hiveserver2所在集群的IP地址
<value>lcoalhost</value>
</property>
<property>
<name>hive.server2.long.polling.timeout</name> #设置超时时间
<value>5000</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name> #设置Hive的元数据库
<value>jdbc:mysql://localhost:3306/hive_metadata? createDatabaseIfNotExist=true&useSSL=false</value> #首先在mysql新建hive_metadata
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name> #描述一个JDBC驱动程序类的名称
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name> #连接元数据库用户名
<value>root</value> #根据mysql用户名进行修改
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name> #连接元数据库密码
<value>123456</value> #根据mysql密码进行修改
</property>
第三步:启动Hive
将mysql-connector-java-5.1.39.jar(该包已经定制到了“/usr/local”目录下)驱动包上传到Hive安装目录中的lib目 录下,修改环境变量并启动hive,命令如下。
vi ~/.bashrc
#在该配置文件中输入如下内容
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin source ~/.bashrc /usr/local/hive/bin/schematool -initSchema -dbType mysql #首次启动时需要初始化源数据库
hive
第四部分:Flume部署
第一步:解压安装包
Flume安装包已经定制到了环境的“/usr/local”目录下,并重命名为Flume,命令如下。
tar -zxvf apache-flume-1.7.0-bin.tar.gz
mv apache-flume-1.7.0-bin flume
第二步:配置环境变量
配置Flume环境变量并通过查看版本方式检查Flume是否安装成功,命令如下。
vi ~/.bashrc
#在该配置文件中输入如下内容
export FLUME_HOME=/usr/local/flume
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=.:$PATH:$FLUME_HOME/bin source ~/.bashrc flume-ng version
第五部分:Sqoop部署
###第一步:解压安装包 Sqoop安装包已经定制到了环境的“/usr/local”目录下,并重命名为Sqoop,命令如下。
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop
###第二步:修改配置文件
(1)配置Sqoop的环境变量,命令如下所示。
vi ~/.bashrc
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
[root@master local]# source ~/.bashrc
(2)配置sqoop-env.sh文件,指定Hadoop、Hbase与Hive工作目录,命令如下所示。
cp /usr/local/sqoop/conf/sqoop-env-template.sh /usr/local/sqoop/conf/sqoop-env.sh
vi /usr/local/sqoop/conf/sqoop-env.sh
#编辑内容如下:
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/usr/local/hadoop #Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/usr/local/hadoop #set the path to where bin/HBase is available
export HBASE_HOME=/usr/local/hbase #Set the path to where bin/hive is available
#export HIVE_HOME=/usr/local/hive
#查看Sqoop版本,来验证是否安装成功
###第三步:验证 将mysql-connector-java-5.1.39-bin.jar驱动包拷贝到/sqoop/lib目录下并查看sqoop版本,命 令如下所示。
cp /usr/local/mysql-connector-java-5.1.39.jar /usr/local/sqoop/lib/
sqoop version
##第六部分:Scala环境安装
###第一步:解压安装包 scala安装包已经定制到了环境的“/usr/local”目录下,并重命名为scala,命令如下。
tar -zxvf scala-2.11.4.tgz
mv scala-2.11.4 scala
###第二步:配置scala环境变量并验证 将scala工作环境配置到环境变量中,并查看scala功能是否可用,命令如 下。
vi ~/.bashrc #在该配置文件中输入如下内容
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin source ~/.bashrc
scala -version
##第七部分:部署Spark环境
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz
mv spark-2.2.0-bin-hadoop2.7 spark
###第一步:解压安装包 spark安装包已经定制到了环境的“/usr/local”目录下,并重命名为spark,命令如下。
第二步:配置文件修改
(1)进入spark/conf目录,复制一份spark-env.sh.template并更改文件名为spark-env.sh,同时对spark-env.sh 文件进行编辑,命令如下。
cd /usr/local/spark/conf/
cp spark-env.sh.template spark-env.sh
vi spark-env.sh #再该配置文件末尾添加如下配置
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_EXECUTOR_CORES=1
export SPARK_CONF_DIR=/usr/local/spark/conf
export SPARK_LOG_DIR=/usr/local/spark/logs
export SPARK_LOCAL_IP=localhost
(2)将mysql-connector-java-5.1.39.jar包拷贝到spark的/jars目录下,命令如下所示。
cp /usr/local/mysql-connector-java-5.1.39.jar /usr/local/spark/jars/
(3)将hive-site.xml从hive的/conf目录下拷贝到/spark/conf目录下,命令如下所示。
cp /usr/local/hive/conf/hive-site.xml /usr/local/spark/conf/
(4)修改/usr/lcoal/spark/conf目录下的spark-config.sh文件,在改文件中添加jdk路径,命令如下所示。
vi /usr/local/spark/sbin/spark-config.sh #在该配置文件中添加如下内容
export JAVA_HOME=/usr/java/jdk1.8.0_144
第四步:启动Spark
进入spark/sbin目录,运行命令:./start-all.sh 来启动Spark,命令如下所示。
cd /usr/local/spark/sbin/
./start-all.sh
jps
##第八部分:kakfa部署 第一步:解压安装包
kafka安装包已经定制到了环境的“/usr/local”目录下,并重命名为kafka,命令如下。
tar -zxvf kafka_2.11-0.11.0.1.tgz
mv kafka_2.11-0.11.0.1 kafka
第二步:赋予kafka工作目录权限
chmod 777 -R kafka
第三步:启动kafka
(1)启动kafka自带的zookeeper,如果已经启动zookeeper进程则不需要执行此步骤,命令如下所示。
cd /usr/local/kafka/bin/
./zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties 1>/dev/null 2>&1 &
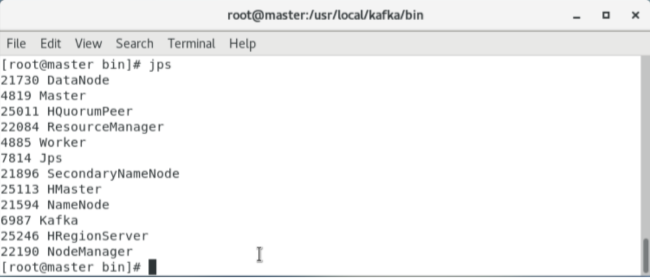
jps
(2)启动kafka进程,命令如下。
cd /usr/local/kafka/bin/
./kafka-server-start.sh /usr/local/kafka/config/server.properties >/dev/null 2>&1 &
jps
结果如图所示:
完结。。。。
hadoop伪分布式平台组件搭建的更多相关文章
- hadoop伪分布式平台搭建(centos 6.3)
最近要写一个数据量较大的程序,所以想搭建一个hbase平台试试.搭建hbase伪分布式平台,需要先搭建hadoop平台.本文主要介绍伪分布式平台搭建过程. 目录: 一.前言 二.环境搭建 三.命令测试 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop2.0伪分布式平台环境搭建
一.搭建环境的前提条件 环境:ubuntu-16.04 hadoop-2.6.0 jdk1.8.0_161.这里的环境不一定需要和我一样,基本版本差不多都ok的,所需安装包和压缩包自行下载即可. 因 ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- Hadoop伪分布式集群搭建
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 1.下载Hadoop压缩包 wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop- ...
- hadoop伪分布式平台搭建
1. 安装jdk1.7 JAVA_HOME=/home/hadoop/app/jdk1.7.0 vi /etc/profile.d CLASSPATH=.:$JAVA_HOME/lib/dt.jar: ...
- Hadoop伪分布式环境快速搭建
Hadoop分支 Apache Cloudera Hortonworks 本文是采用Cloudera分支的hadoop. 下载cdh-5.3.6 版本 下载地址:http://archive.clou ...
- Hadoop伪分布式HDFS环境搭建和使用
1.环境要求 Java版本不低于Hadoop要求,并配置环境变量 2.安装 1)在网站hadoop.apache.org下载稳定版本的Hadoop包 2)解压压缩包 检查Hadoop是否可用 hado ...
随机推荐
- 基于vue(element ui) + ssm + shiro 的权限框架
zhcc 基于vue(element ui) + ssm + shiro 的权限框架 引言 心声 现在的Java世界,各种资源很丰富,不得不说,从分布式,服务化,orm,再到前端控制,权限等等玲琅满目 ...
- 【Alpha冲刺阶段】Scrum Meeting Daily2
[Alpha冲刺阶段]Scrum Meeting Daily2 1.会议简述 会议开展时间 2020/5/23 8:30-9:00 PM 会议基本内容摘要 讨论了基础的分工,以及明确了各自模块需要完成 ...
- NOIP2020 浙江 游记
day - ? 由于 CSP-S 的失利,感觉这一次 NOIP 的心态反而是非常的淡定,感觉反正已经炸过一次了,再炸一次好像也没什么,就抱着这样的心态去考试的. day 1 考试当天起晚了,到考场的时 ...
- 01_02_py
1基础知识 1.自然语言 (natural language) 是人们交流所使用的语言,例如英语.西班牙语和法语.它们不是人为设计出来的(尽管有人试图这样做):而是自然演变而来. 2.形式语言 (fo ...
- rsync 参数说明及使用参数笔记
第1章 rsync 命令简介 rsync 是一款开源的.快速的.多功能的.可实现全量及增量的本地或远程数据镜像同步备份的优秀工具. 1.1.1 语法格式 三种模式: 1)本地模式 rsync [选项] ...
- xlwt:python的写excel模块
最近工作时碰到了将数据导出,生成一个excel表,对其中的部分数据进行统计,并给其中部分符合条件的数据添加对应的背景颜色的功能需求,于是乎,对Python中写excel的模块xlwt研究了一下,在工作 ...
- uni-app中封装统一请求函数
封装统一请求函数有利于项目的维护 整体功能简单实用,但小编遇到一个巨坑,项目中在vue文件使用跳转方法,url参数输入 "/" 后工具提示的路径为 "/pages/log ...
- Springboot 项目 无法读取resources下的mapper文件夹的.xml文件
之前学习的时候遇到的一个问题 org.springframework.beans.factory.BeanCreationException: Error creating bean with nam ...
- 如何用Python 制作词云-对1000首古诗做词云分析
公号:码农充电站pro 主页:https://codeshellme.github.io 今天来介绍一下如何使用 Python 制作词云. 词云又叫文字云,它可以统计文本中频率较高的词,并将这些词可视 ...
- SQL Server NULL值用法及处理详解
用法如下: 1.如果表中的某个列是可选的,那么我们可以在不向该列添加值的情况下插入新记录或更新已有的记录,这意味着该字段将以 NULL 值保存. 2.NULL 用作未知的或不适用的值的占位符. 3.定 ...