基于 MPI 的快速排序算法的实现
完整代码:
#include <iostream>
#include <cstdlib>
#include <ctime>
#include <algorithm>
#include <cmath>
#include <mpi.h>
using namespace std;
struct Pair {
int left;
int right;
};
const int MAX_PROCESS = 128;
const int NUM = 8000;
const int MAX = 1000000;
const int MIN = 0;
int arr[NUM];
int temp[NUM];
Pair pairs[MAX_PROCESS];
int counter = -1;
void swap(int A[], int i, int j) {
int temp = A[i];
A[i] = A[j];
A[j] = temp;
}
int findpivot(int i, int j) {
return (i + j) / 2;
}
int partition(int A[], int l, int r, int pivot) {
do {
while (A[++l] < pivot);
while ((r != 0 && (A[--r] > pivot)));
swap(A, l, r);
} while (l < r);
swap(A, l, r);
return l;
}
void quicksort(int A[], int i, int j, int currentdepth, int targetdepth) {
if (currentdepth == targetdepth) {
int rank = ++counter;
pairs[rank].left = i;
pairs[rank].right = j;
cout << pairs[rank].left << " and " << pairs[rank].right << " : rank " << rank << endl;
return;
}
if (j <= i) return;
int pivotindex = findpivot(i, j);
swap(A, pivotindex, j);
int k = partition(A, i - 1, j, A[j]);
swap(A, k, j);
quicksort(A, i, k - 1, currentdepth + 1, targetdepth);
quicksort(A, k + 1, j, currentdepth + 1, targetdepth);
}
void quicksort(int A[], int i, int j) {
if (j <= i) return;
int pivotindex = findpivot(i, j);
swap(A, pivotindex, j);
int k = partition(A, i - 1, j, A[j]);
swap(A, k, j);
quicksort(A, i, k - 1);
quicksort(A, k + 1, j);
}
int main(int argc, char* argv[]) {
MPI_Init(&argc, &argv);
int RANK, SIZE, targetdepth, left, right, REAL_SIZE;
MPI_Comm_rank(MPI_COMM_WORLD, &RANK);
MPI_Comm_size(MPI_COMM_WORLD, &SIZE);
REAL_SIZE = SIZE;
if (RANK == 0) {
cout << "Quick sort start..." << endl;
cout << "Generate random data... ";
memset(arr, 0, NUM * sizeof(arr[0]));
srand(time(NULL));
for (int i = 0; i < NUM; i++) {
arr[i] = MIN + rand() % (MAX - MIN);
}
cout << "Done." << endl;
targetdepth = log2(SIZE);
cout << "Rank: " << RANK << endl;
cout << "Sorting... ";
quicksort(arr, 0, NUM - 1, 0, targetdepth);
REAL_SIZE = counter + 1;
for (int i = 1; i < SIZE; i++) {
int left = pairs[i].left;
int right = pairs[i].right;
MPI_Send(&REAL_SIZE, 1, MPI_INT, i, 99, MPI_COMM_WORLD);
MPI_Send(&left, 1, MPI_INT, i, 0, MPI_COMM_WORLD);
MPI_Send(&right, 1, MPI_INT, i, 1, MPI_COMM_WORLD);
MPI_Send(&arr, NUM, MPI_INT, i, 2, MPI_COMM_WORLD);
}
left = pairs[0].left;
right = pairs[0].right;
quicksort(arr, left, right);
cout << "Process " << RANK <<" done."<< endl;
}
for (int process = 1; process < REAL_SIZE; process++) {
if (RANK == process) {
MPI_Status status;
MPI_Recv(&REAL_SIZE, 1, MPI_INT, 0, 99, MPI_COMM_WORLD, &status);
MPI_Recv(&left, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);
MPI_Recv(&right, 1, MPI_INT, 0, 1, MPI_COMM_WORLD, &status);
MPI_Recv(&arr, NUM, MPI_INT, 0, 2, MPI_COMM_WORLD, &status);
if (process < REAL_SIZE) {
quicksort(arr, left, right);
MPI_Send(&arr, NUM, MPI_INT, 0, 0, MPI_COMM_WORLD);
cout << "Process " << RANK << " done." << endl;
}
}
}
if (RANK == 0) {
for (int i = 1; i < REAL_SIZE; i++) {
//cout << "Master is ready to receive data from process " << i << endl;
MPI_Status status;
MPI_Recv(&temp, NUM, MPI_INT, i, 0, MPI_COMM_WORLD, &status);
for (int j = pairs[i].left; j <= pairs[i].right; j++) {
arr[j] = temp[j];
}
//cout << "Master has combined data from process " << i << endl;
}
cout << "Done." << endl;
cout << "Result:" << endl;
int counter = 1;
int row = 20;
for (int i = 0; i < NUM; i++, counter++) {
cout << arr[i] << " ";
if (arr[i] < arr[max(i - 1, 0)]) {
cerr << "Invalid! " << arr[i] << " > "<< arr[max(i - 1, 0)] <<" i is "<< i << endl;
}
if (counter % row == 0) cout << endl;
}
}
MPI_Finalize();
}
运行截图:
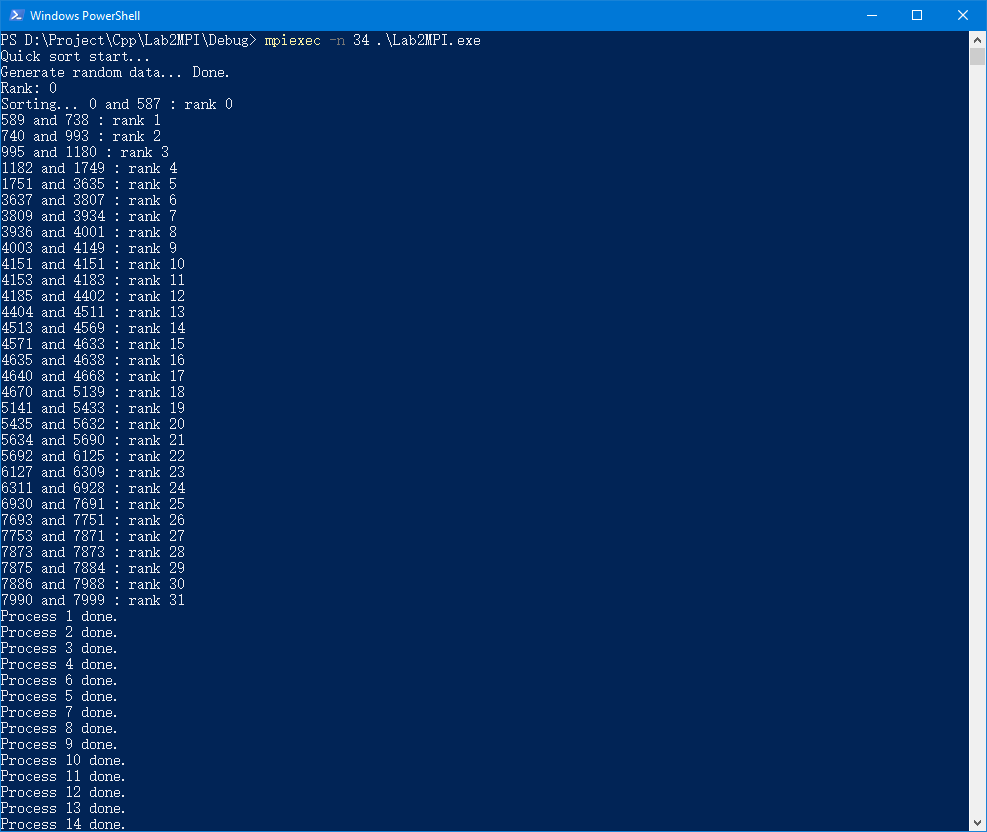
基于 MPI 的快速排序算法的实现的更多相关文章
- 基于c++的ostu算法的实现
图像二值化算法是图像处理的基础.一般来说,二值化算法可以分为两个类别:全局二值化和局部二值化.全局二值化是指通过某种算法找到一个全局的阈值T,对图像中坐标为(x,y)的像素值做如下处理: Ostu就是 ...
- 快速排序算法的实现 && 随机生成区间里的数 && O(n)找第k小 && O(nlogk)找前k大
思路:固定一个数,把这个数放到合法的位置,然后左边的数都是比它小,右边的数都是比它大 固定权值选的是第一个数,或者一个随机数 因为固定的是左端点,所以一开始需要在右端点开始,找一个小于权值的数,从左端 ...
- Python八大算法的实现,插入排序、希尔排序、冒泡排序、快速排序、直接选择排序、堆排序、归并排序、基数排序。
Python八大算法的实现,插入排序.希尔排序.冒泡排序.快速排序.直接选择排序.堆排序.归并排序.基数排序. 1.插入排序 描述 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得 ...
- 基于思岚A1激光雷达+OpenGL+VS2017的Ramer-Douglas-Peucker算法的实现
时隔两年 又借到了之前的那个激光雷达,最老版本的思岚A1,甚至不支持新的固件,并且转接板也不见了,看了下淘宝店卖¥80,但是官方提供了一个基于STM32的实现方式,于是我估摸着这个转接板只是一个普通的 ...
- Canny边缘检测算法的实现
图像边缘信息主要集中在高频段,通常说图像锐化或检测边缘,实质就是高频滤波.我们知道微分运算是求信号的变化率,具有加强高频分量的作用.在空域运算中来说,对图像的锐化就是计算微分.由于数字图像的离散信号, ...
- SSE图像算法优化系列十三:超高速BoxBlur算法的实现和优化(Opencv的速度的五倍)
在SSE图像算法优化系列五:超高速指数模糊算法的实现和优化(10000*10000在100ms左右实现) 一文中,我曾经说过优化后的ExpBlur比BoxBlur还要快,那个时候我比较的BoxBlur ...
- C++基础代码--20余种数据结构和算法的实现
C++基础代码--20余种数据结构和算法的实现 过年了,闲来无事,翻阅起以前写的代码,无意间找到了大学时写的一套C++工具集,主要是关于数据结构和算法.以及语言层面的工具类.过去好几年了,现在几乎已经 ...
- 排序算法的实现之Javascript(常用)
排序算法的实现之Javascript 话不多说,直接代码. 1.冒泡排序 1.依次比较相邻的两个数,如果前一个比后一个大,则交换两者的位置,否则位置不变 2.按照第一步的方法重复操作前length-1 ...
- Alink漫谈(六) : TF-IDF算法的实现
Alink漫谈(六) : TF-IDF算法的实现 目录 Alink漫谈(六) : TF-IDF算法的实现 0x00 摘要 0x01 TF-IDF 1.1 原理 1.2 计算方法 0x02 Alink示 ...
随机推荐
- BJWC2011 禁忌
题目链接 题解 多模式匹配首先建 AC 自动机,看到 \(len \le 10^9\) 想到矩阵乘法优化. 朴素 DP 关于分割的最大值,可以贪心,只要走到一个能匹配串的点立刻返回根继续匹配就行,一定 ...
- AcWing 404. 婚礼
大型补档计划 题目链接 根据题意,显然只有新郎这边可能存在矛盾,考虑这边怎么放即可,新娘那边的放法与这边正好相反且一一对应. 显然对于两个约束条件是一对矛盾,开始我以为可以用并查集,后来发现输出方案的 ...
- STL——容器(Map & multimap)的插入与迭代器
1. 容器(Map & multimap)的插入 map.insert(...); //往容器插入元素,返回pair<iterator,bool> map中插入元素的四种方式 ...
- Bootstrap 的基本使用
一.Bootstrap简介 Bootstrap 是目前受欢迎的前端框架之一,是基于HTML,CSS,JavaScript的,它简洁灵活,使web开发更加快捷 中文官网:http://www.bootc ...
- 从零到一快速搭建个人博客网站(域名备案 + https免费证书)(一)
环境介绍 资源 说明 centos v7.2 docker 快速部署项目环境 nginx 反向代理,同时配置https证书 halo v1.4.2,开源博客项目 Let's Encrypt 免费证书 ...
- SpringBoot + Layui + JustAuth +Mybatis-plus实现可第三方登录的简单后台管理系统
1. 简介 在之前博客:SpringBoot基于JustAuth实现第三方授权登录 和 SpringBoot + Layui +Mybatis-plus实现简单后台管理系统(内置安全过滤器)上改造 ...
- SpringBoot集成基于tobato的fastdfs-client实现文件上传下载和删除
1. 简介 基于tobato的fastdfs-client是一个功能完善的FastDFS客户端工具,它是在FastDFS作者YuQing发布的客户端基础上进行了大量的重构,提供了上传.下载.删除. ...
- Docker部署FastDFS(附示例代码)
1. FastDFS简介 FastDFS是一个开源的分布式文件系统,它对文件进行管理,功能包括:文件存储.文件同步.文件访问(文件上传.文件下载)等,解决了大容量存储和负载均衡的问题.特别适合以文 ...
- Web常用编码以及攻击绕过笔记
一.URL编码形式:"%"加上ASCII码(先将字符转换为两位ASCII码,再转为16进制),其中加号"+"在URL编码中和"%20"表示一 ...
- 【收藏】关于元数据(Metadata)和元数据管理,这是我的见过最全的解读!
本文主要从元数据的定义.作用.元数据管理现状.管理标准和元数据管理功能等方面讲述了我对元数据(Metadata)和元数据管理的认知及理解. 元数据管理 一.元数据的定义 按照传统的定义,元数据(Met ...