SUSE Ceph 增加节点、减少节点、 删除OSD磁盘等操作 - Storage6
学习 SUSE Storage 系列文章
(1)SUSE Storage6 实验环境搭建详细步骤 - Win10 + VMware WorkStation
(2)SUSE Linux Enterprise 15 SP1 系统安装
(4)SUSE Ceph 增加节点、减少节点、 删除OSD磁盘等操作 - Storage6
(5)深入理解 DeepSea 和 Salt 部署工具 - Storage6
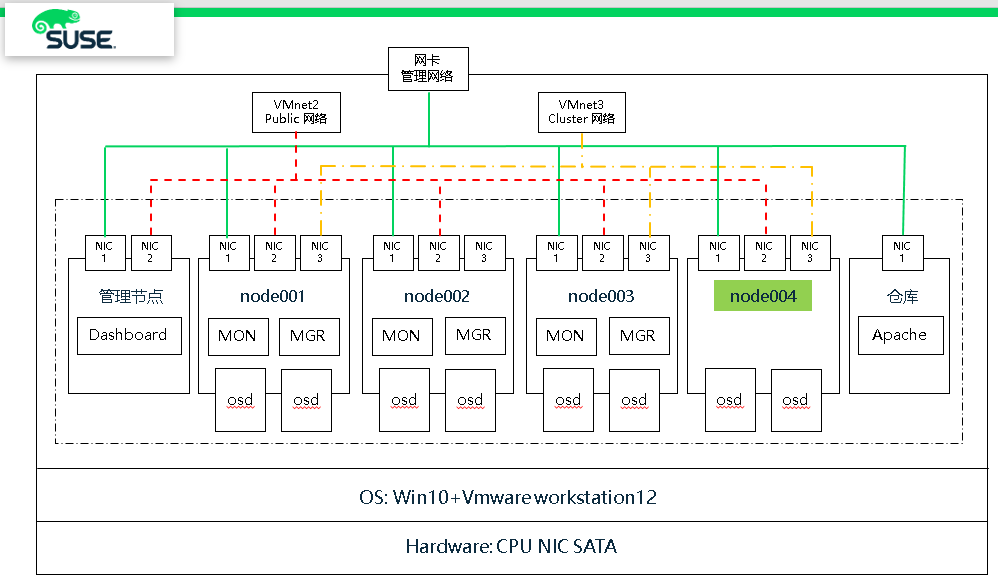
一、测试环境描述
之前我们已快速部署好一套Ceph集群(3节点),现要测试在现有集群中在线方式增加节点
- 如下表中可以看到增加节点node004具体配置
|
主机名 |
Public网络 |
管理网络 |
集群网络 |
说明 |
|
admin |
192.168.2.39 |
172.200.50.39 |
--- |
管理节点 |
|
node001 |
192.168.2.40 |
172.200.50.40 |
192.168.3.40 |
MON,OSD |
|
node002 |
192.168.2.41 |
172.200.50.41 |
192.168.3.41 |
MON,OSD |
|
node003 |
192.168.2.42 |
172.200.50.42 |
192.168.3.42 |
MON,OSD |
|
node004 |
192.168.2.43 |
172.200.50.43 |
192.168.3.43 |
OSD |
- 测试集群架构图
可以看到架构图中增加了node004节点,并且node004节点只是作为OSD节点,并无MON或MGR服务
二、增加集群节点 node004
1、收集集群信息
(1)集群状态
# ceph -s
cluster:
id: f7b451b3-4a4c--a4ef-4b5359242a92
health: HEALTH_OK services:
mon: daemons, quorum node001,node002,node003 (age 90m)
mgr: node001(active, since 89m), standbys: node002, node003
osd: osds: up (since 90m), in (since 23h) data:
pools: pools, pgs
objects: objects, B
usage: GiB used, GiB / GiB avail
pgs:
(2)集群OSD磁盘信息
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.05878 root default
- 0.01959 host node001
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node002
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node003
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
(3)查看新增节点磁盘
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda : 20G disk
├─sda1 : 1G part /boot
└─sda2 : 19G part
├─vgoo-lvswap : 2G lvm [SWAP]
└─vgoo-lvroot : 17G lvm /
sdb : 10G disk
sdc : 10G disk
sr0 : 1024M rom
nvme0n1 : 20G disk
nvme0n2 : 20G disk
nvme0n3 : 20G disk
2、初始化操作系统
(1)初始化步骤
参考快速部署 storage6 文档
(2)显示仓库
# zypper lr
Repository priorities are without effect. All enabled repositories share the same priority. # | Alias | Name | Enabled | GPG Check | Refresh
---+----------------------------------------------------+----------------------------------------------------+---------+-----------+--------
1 | SLE-Module-Basesystem-SLES15-SP1-Pool | SLE-Module-Basesystem-SLES15-SP1-Pool | Yes | (r ) Yes | No
2 | SLE-Module-Basesystem-SLES15-SP1-Upadates | SLE-Module-Basesystem-SLES15-SP1-Upadates | Yes | (r ) Yes | No
3 | SLE-Module-Legacy-SLES15-SP1-Pool | SLE-Module-Legacy-SLES15-SP1-Pool | Yes | (r ) Yes | No
4 | SLE-Module-Legacy-SLES15-SP1-Updates | SLE-Module-Legacy-SLES15-SP1-Updates | Yes | ( p) Yes | No
5 | SLE-Module-Server-Applications-SLES15-SP1-Pool | SLE-Module-Server-Applications-SLES15-SP1-Pool | Yes | (r ) Yes | No
6 | SLE-Module-Server-Applications-SLES15-SP1-Upadates | SLE-Module-Server-Applications-SLES15-SP1-Upadates | Yes | (r ) Yes | No
7 | SLE-Product-SLES15-SP1-Pool | SLE-Product-SLES15-SP1-Pool | Yes | (r ) Yes | No
8 | SLE-Product-SLES15-SP1-Updates | SLE-Product-SLES15-SP1-Updates | Yes | (r ) Yes | No
9 | SUSE-Enterprise-Storage-6-Pool | SUSE-Enterprise-Storage-6-Pool | Yes | (r ) Yes | No
10 | SUSE-Enterprise-Storage-6-Updates | SUSE-Enterprise-Storage-6-Updates | Yes | (r ) Yes | No
(3)hosts文件
192.168.2.39 admin.example.com admin
192.168.2.40 node001.example.com node001
192.168.2.41 node002.example.com node002
192.168.2.42 node003.example.com node003
192.168.2.43 node004.example.com node004
192.168.2.44 node005.example.com node005
3、安装 satlt-minion
- node004节点
zypper -n in salt-minion
sed -i '17i\master: 192.168.2.39' /etc/salt/minion
systemctl restart salt-minion.service
systemctl enable salt-minion.service
systemctl status salt-minion.service
- admin节点
# salt-key
Accepted Keys:
admin.example.com
node001.example.com
node002.example.com
node003.example.com
Denied Keys:
Unaccepted Keys:
node004.example.com <==== 新加节点
Rejected Keys:
- 接受key
# salt-key -A
- 测试node004
# salt "node004*" test.ping
node004.example.com:
True
4、预防集群数据平衡
- 以前增加节点的时候,一直使用norebalance方式来预防数据平衡,这种方式比较简单粗暴,(不建议使用)
# ceph osd set norebalance
norebalance is set
admin:/etc/salt/pki/master # ceph -s
cluster:
id: f7b451b3-4a4c--a4ef-4b5359242a92
health: HEALTH_WARN
norebalance flag(s) set
services:
mon: 3 daemons, quorum node001,node002,node003 (age 2h)
mgr: node001(active, since 2h), standbys: node002, node003
osd: 6 osds: 6 up (since 2h), 6 in (since 24h)
flags norebalance data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 12 GiB used, 48 GiB / 60 GiB avail
pgs:
- 建议使用 “osd_crush_initial_weight”参数,结合salt工具批量执行
(1)新建 global.conf 文件(admin节点)
# vim /srv/salt/ceph/configuration/files/ceph.conf.d/global.conf
osd_crush_initial_weight =
(2)创建新配置文件(admin节点)
# salt '*' state.apply ceph.configuration.create
注意:执行时有报错,可忽略
node003.example.com:
Name: /var/cache/salt/minion/files/base/ceph/configuration - Function: file.absent -
Result: Changed Started: - ::45.362265 Duration: 22.133 ms
----------
ID: /srv/salt/ceph/configuration/cache/ceph.conf
Function: file.managed
Result: False
Comment: Unable to manage file: Jinja error: 'select.minions'
Traceback (most recent call last):
File "/usr/lib/python3.6/site-pack
(3)执行新配置文件,并且只在node001 node002 node003节点上生效 (admin节点)
# salt 'node00[1-3]*' state.apply ceph.configuration
(4)检查个节点配置文件 (node001,node002,node003)
# cat /etc/ceph/ceph.conf
osd crush initial weight =
5、执行stage0 1 2 (admin节点)
# salt-run state.orch ceph.stage.
# salt-run state.orch ceph.stage.
# salt-run state.orch ceph.stage.
# salt 'node004*' pillar.items # 查看pillar设置是否正确
public_network:
192.168.2.0/
roles:
- storage # 仅仅是 storage 角色
time_server:
admin.example.com
6、检查生成 OSD 报告(admin节点)
# salt-run disks.report
node004.example.com:
|_
-
-
Total OSDs: Solid State VG:
Targets: block.db Total size: 19.00 GB
Total LVs: Size per LV: 1.86 GB
Devices: /dev/nvme0n2 Type Path LV Size % of device
-------------------------------------------------------------------------
[data] /dev/sdb 9.00 GB 100.0%
[block.db] vg: vg/lv 1.86 GB %
-------------------------------------------------------------------------
[data] /dev/sdc 9.00 GB 100.0%
[block.db] vg: vg/lv 1.86 GB %
7、运行stage3, 把node004节点添加进来,并自动创建OSD (admin节点)
# salt-run state.orch ceph.stage.
8、执行后检查集群OSD状态 (admin节点)
可以发现新增节点权重都是0,这是由于之前配置的“osd_crush_initial_weight”参数,预防新增节点或磁盘进来时进行数据平衡。
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.05878 root default
- 0.01959 host node001
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node002
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node003
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- host node004
hdd 0 osd. up 1.00000 1.00000 <=== 新增节点OSD权重为0
hdd 0 osd. up 1.00000 1.00000
9、手动增加OSD磁盘权重 (admin节点)
注意:生产环境请在变更时间执行,执行时会数据平衡,影响读写。当然也可以通过Ceph参数或QOS来控制读写速率,后续文档中会提到。
# ceph osd crush reweight osd. 0.00980
# ceph osd crush reweight osd. 0.00980
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.07837 root default
- 0.01959 host node001
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node002
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node003
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node004
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
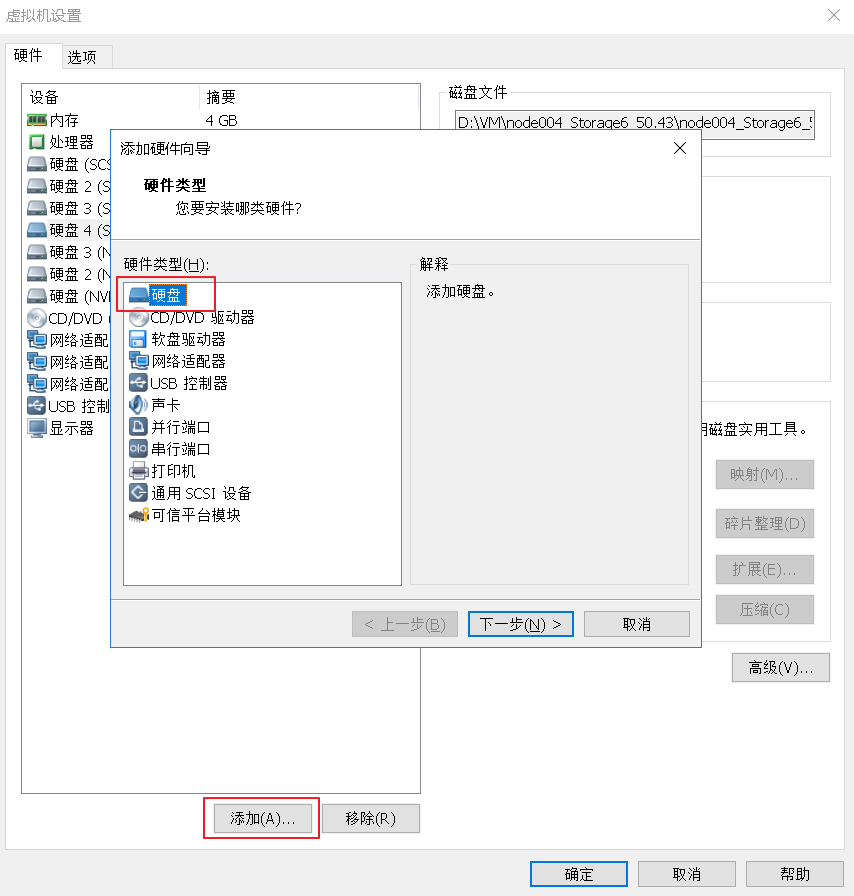
三、增加 OSD 磁盘操作
1、首先我们通过 VMware workstation 的虚拟机 node004 节点上添加一块10G大小的磁盘
2、开启虚拟机后,node004主机终端中查看新增磁盘
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda : 20G disk
├─sda1 : 1G part /boot
└─sda2 : 19G part
├─vgoo-lvroot : 17G lvm /
└─vgoo-lvswap : 2G lvm [SWAP]
sdb : 10G disk
└─ceph--block--0515f9d7----46a5-- : 9G lvm
sdc : 10G disk
└─ceph--block--9f7394b2--3ad3--4cd8-- : 9G lvm
sdd : 10G disk <== 新增磁盘
sr0 : 1024M rom
nvme0n1 : 20G disk
nvme0n2 : 20G disk
├─ceph--block--dbs--57d07a01---- : 1G lvm
└─ceph--block--dbs--57d07a01---- : 1G lvm
nvme0n3 : 20G disk
3、查看 VG LV 信息
# lvs
LV VG Attr LSize
osd-block-9a914f7d-ae9c-451a-ac7e-bcb6cb1fc926 ceph-block-0515f9d7-3407-46a5-be68-db80fc789dcc -wi-ao---- 9.00g
osd-block-79f5920f-b41c-4dd0-94e9-dc85dbb2e7e4 ceph-block-9f7394b2-3ad3-4cd8-8267-7e5993af1271 -wi-ao---- 9.00g
osd-block-db-2244293e-ca96-4847-a5cb-9112f59836fa ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-ao---- 1.00g
osd-block-db-2b295cc9-caff-45ad-a179-d7e3ba46a39d ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-ao---- 1.00g
osd-block-db-test ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-a----- 2.00g
lvroot vgoo -wi-ao---- 17.00g
lvswap vgoo -wi-ao---- 2.00g
4、创建 OSD 磁盘的 VG 和 LV
# vgcreate ceph-block- /dev/sdd
# lvcreate -l %FREE -n block- ceph-block-
5、在已在nvme0n2磁盘上创建的 VG 上创建 LV
我们从第3个步骤中可以看到,nvme0n2磁盘已经被 VG ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586所使用,我们要在该VG上创建LV,因为一般一块PCIE SSD磁盘可以承担10块OSD数据磁盘,作为他们WAL和DB加速磁盘使用。
# lvcreate -L 2GB -n db- ceph-block-dbs-57d07a01---b44c-eae536613586
6、显示 VG LV 信息
# lvs
LV VG Attr LSize
block-0 ceph-block-0 -wi-a----- 10.00g
osd-block-9a914f7d-ae9c-451a-ac7e-bcb6cb1fc926 ceph-block-0515f9d7-3407-46a5-be68-db80fc789dcc -wi-ao---- 9.00g
osd-block-79f5920f-b41c-4dd0-94e9-dc85dbb2e7e4 ceph-block-9f7394b2-3ad3-4cd8-8267-7e5993af1271 -wi-ao---- 9.00g
db-0 ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-a----- 2.00g
osd-block-db-2244293e-ca96-4847-a5cb-9112f59836fa ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-ao---- 1.00g
osd-block-db-2b295cc9-caff-45ad-a179-d7e3ba46a39d ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-ao---- 1.00g
lvroot vgoo -wi-ao---- 17.00g
lvswap vgoo -wi-ao---- 2.00g
7、使用 ceph-volume 方式创建
- 这次我们通过另一种方式来创建,而不是使用 drive group 方式,因为你需要了解到一旦自动化工具出现问题时如何处理和创建OSD
# ceph-volume lvm create --bluestore --data ceph-block-/block- --block.db ceph-block-dbs-57d07a01---b44c-eae536613586/db-
- 管理节点上,查看OSD输出信息
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.07837 root default
- 0.01959 host node001
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node002
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node003
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node004
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
hdd osd. up 1.00000 1.00000 <==== 可以看到 osd.8 被创建出来
8、设置权重
注意:生产环境操作时,会数据平衡会影响到读写性能。
# ceph osd crush reweight osd. 0.00980
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.08817 root default
- 0.01959 host node001
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node002
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node003
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.02939 host node004
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
四、删除OSD磁盘
语法: salt-run osd.remove OSD_ID
1、批量删除 node004 节点上 OSD.7 OSD.8
admin:~ # ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.08817 root default
- 0.01959 host node001
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node002
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node003
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.02939 host node004
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
admin:~ # salt-run osd.remove
Removing osd on host node004.example.com
Draining the OSD
Waiting for ceph to catch up.
osd. is safe to destroy
Purging from the crushmap
Zapping the device Removing osd on host node004.example.com
Draining the OSD
Waiting for ceph to catch up.
osd. is safe to destroy
Purging from the crushmap
Zapping the device
2、显示 osd 信息,node004主机上 osd.7 和 osd.8 已被删除
admin:~ # ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.06857 root default
- 0.01959 host node001
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node002
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node003
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.00980 host node004
hdd 0.00980 osd. up 1.00000 1.00000
3、删除 OSD 其他命令
(1)删除节点上所有osd
# salt-run osd.remove OSD_HOST_NAME
(2)当 WAL 或 DB 设备损坏时,移除破损的磁盘
# salt-run osd.remove OSD_ID force=True
四、减少集群节点
从集群中移出node004 osd节点,移除前请确保集群有足够的空间容纳node004上的数据
1、手动方式
(1)管理节点查看 OSD 信息
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.06857 root default
- 0.01959 host node001
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node002
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node003
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.00980 host node004
hdd 0.00980 osd. up 1.00000 1.00000
(2)node004 节点上停止OSD服务
# systemctl stop ceph-osd@.service
# systemctl stop ceph-osd.target
(3)node004 节点上,卸载挂载目录
# umount /var/lib/ceph/osd/ceph-
(4)admin节点上,移除OSD
# ceph osd out
# ceph osd crush remove osd.
# ceph osd rm osd.
# ceph auth del osd.
(5)admin节点上,从CRUSH MAP上移除节点信息
# ceph osd crush rm node004
(6)检查集群是否清理干净node004
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.05878 root default
- 0.01959 host node001
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node002
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
- 0.01959 host node003
hdd 0.00980 osd. up 1.00000 1.00000
hdd 0.00980 osd. up 1.00000 1.00000
(7)node004节点,删除所有相关 VG LV 信息
- 查看node004节点 VG LV 信息
node004:~ # vgs
VG #PV #LV #SN Attr VSize VFree
ceph-block-0515f9d7--46a5-be68-db80fc789dcc wz--n- .00g
ceph-block-dbs-57d07a01---b44c-eae536613586 wz--n- .00g .00g
vg00 wz--n- .00g 0
node004:~ # lvs
LV VG Attr LSize
osd-block-9a914f7d-ae9c-451a-ac7e-bcb6cb1fc926 ceph-block-0515f9d7-3407-46a5-be68-db80fc789dcc -wi-a----- 9.00g
osd-block-db-2b295cc9-caff-45ad-a179-d7e3ba46a39d ceph-block-dbs-57d07a01-4440-4892-b44c-eae536613586 -wi-a----- 1.00g
lvroot vg00 -wi-ao---- 17.00g
lvswap vg00 -wi-ao---- 2.00g
- 删除相关VG LV
# for i in `vgs | grep ceph- | awk '{ print $1 }'`; do vgremove -f $i; done
- 删除后查看VG LV 信息
node004:~ # lvs
LV VG Attr LSize
lvroot vg00 -wi-ao---- .00g
lvswap vg00 -wi-ao---- .00g
node004:~ # vgs
VG #PV #LV #SN Attr VSize VFree
vg00 wz--n- .00g
2、DeepSea 方式
(1)管理节点上修改 policy.cfg 文件
vim /srv/pillar/ceph/proposals/policy.cfg
## Cluster Assignment
#cluster-ceph/cluster/*.sls <=== 注释掉
cluster-ceph/cluster/node00[1-3]*.sls <=== 匹配 target
cluster-ceph/cluster/admin*.sls <=== 匹配 target ## Roles
# ADMIN
role-master/cluster/admin*.sls
role-admin/cluster/admin*.sls # Monitoring
role-prometheus/cluster/admin*.sls
role-grafana/cluster/admin*.sls # MON
role-mon/cluster/node00[1-3]*.sls # MGR (mgrs are usually colocated with mons)
role-mgr/cluster/node00[1-3]*.sls # COMMON
config/stack/default/global.yml
config/stack/default/ceph/cluster.yml # Storage # 定义为 storage 角色
#role-storage/cluster/node00*.sls <=== 注释掉
role-storage/cluster/node00[1-3]*.sls <=== 匹配 target
(2)修改 drive_group.yml 文件
# vim /srv/salt/ceph/configuration/files/drive_groups.yml
# This is the default configuration and
# will create an OSD on all available drives
drive_group_hdd_nvme:
target: 'node00[1-3]*' <== 匹配 target
data_devices:
size: '9GB:12GB'
db_devices:
rotational:
limit:
block_db_size: '2G'
(3)执行salt命令,stage2和stage5
# salt-run state.orch ceph.stage.
# salt-run state.orch ceph.stage.

SUSE Ceph 增加节点、减少节点、 删除OSD磁盘等操作 - Storage6的更多相关文章
- Linux LVM逻辑卷配置过程详解(创建,增加,减少,删除,卸载)
Linux LVM逻辑卷配置过程详解 许多Linux使用者安装操作系统时都会遇到这样的困境:如何精确评估和分配各个硬盘分区的容量,如果当初评估不准确,一旦系统分区不够用时可能不得不备份.删除相关数据, ...
- jQuery的节点添加、删除、替换等操作
//几种添加节点的方法 //$("p").append("<b>你好吗?</b>");//向p元素中追加<b> //$(&q ...
- SUSE Ceph 快速部署 - Storage6
学习 SUSE Storage 系列文章 (1)SUSE Storage6 实验环境搭建详细步骤 - Win10 + VMware WorkStation (2)SUSE Linux Enterpri ...
- 使用DOM解析XML文件,、读取xml文件、保存xml、增加节点、修改节点属性、删除节点
使用的xml文件 <?xml version="1.0" encoding="GB2312" ?> <PhoneInfo> <Br ...
- 分布式存储ceph——(4)ceph 添加/删除osd
一.添加osd: 当前ceph集群中有如下osd,现在准备新添加osd:
- Ceph添加、删除osd及故障硬盘更换
添加或删除osd均在ceph部署节点的cent用户下的ceph目录进行. 1. 添加osd 当前ceph集群中有如下osd,现在准备新添加osd: (1)选择一个osd节点,添加好新的硬盘: (2)显 ...
- ceph添加/删除OSD
一.添加osd: 当前ceph集群中有如下osd,现在准备新添加osd: (1)选择一个osd节点,添加好新的硬盘: (2)显示osd节点中的硬盘,并重置新的osd硬盘: 列出节点磁盘:ceph-de ...
- 007 Ceph手动部署单节点
前面已经介绍了Ceph的自动部署,本次介绍一下关于手动部署Ceph节点操作 一.环境准备 一台虚拟机部署单节点Ceph集群 IP:172.25.250.14 内核: Red Hat Enterpris ...
- Query节点操作,jQuery插入节点,jQuery删除节点,jQuery Dom操作
一.创建节点 var box = $('<div>节点</div>'); //创建一个节点,或者var box = "<div>节点</div> ...
随机推荐
- POJ-2230-Watchcow-欧拉回路的路径输出+结构体
Watchcow 这道题的题意好理解,就是要从1出发,每条边都走两遍,最后再回到1: 但是,我一开始没有想到和欧拉回路有什么关系: 学了求欧拉的dfs()后,试了一下发现和样例差不多: 感觉求回路,什 ...
- HDU 6634 网络流最小割模型 启发式合并
如果我们先手拿完所有苹果再去考虑花费的话. S -> 摄像头 -> 苹果 -> T 就相当于找到一个最小割使得S和T分开. ans = sum - flow. 然后对于这一个模型, ...
- Mac 不显示未知来源选项的解决办法/连接不上网络
原文来自百度经验: http://jingyan.baidu.com/article/eae078278b37d41fec5485b2.html 灰常感谢原作 关于mac无法连接wifi,我的解决办法 ...
- PythonI/O进阶学习笔记_3.2面向对象编程_python的封装
前言: 本篇相关内容分为3篇多态.继承.封装,这篇为第三篇 封装. 本篇内容围绕 python基础教程这段: 在面向对象编程中,术语对象大致意味着一系列数据(属性)以及一套访问和操作这些数据的方法.使 ...
- c语言实现双色球和大乐透
头文件: #include<stdio.h> #include <stdlib.h> #include<string.h> #include <time.h& ...
- Spring Cloud(三):声明式调用
声明式服务调用 前面在使用spring cloud时,通常都会利用它对RestTemplate的请求拦截来实现对依赖服务的接口调用,RestTemplate实现了对http的请求封装处理,形成了一套模 ...
- SpringDataJpa——JpaRepository查询功能(转)
1.JpaRepository支持接口规范方法名查询.意思是如果在接口中定义的查询方法符合它的命名规则,就可以不用写实现,目前支持的关键字如下. Keyword Sample JPQL snippet ...
- Kubernetes pod 状态
CrashLoopBackOff: 容器退出,kubelet正在将它重启 InvalidImageName: 无法解析镜像名称 ImageInspectError: 无法校验镜像 ErrImageNe ...
- Container容器crontab错误问题
问题描述 容器中的cron定时计划任务不执行 问题分析 排查一:检查Container容器是否安装cron # rpm -qa | grep cron # ls /etc/init.d/ 若没有安装, ...
- 致初学者(四):HDU 2044~2050 递推专项习题解
所谓递推,是指从已知的初始条件出发,依据某种递推关系,逐次推出所要求的各中间结果及最后结果.其中初始条件或是问题本身已经给定,或是通过对问题的分析与化简后确定.关于递推的知识可以参阅本博客中随笔“递推 ...