Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解
1.NN和2NN工作机制
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
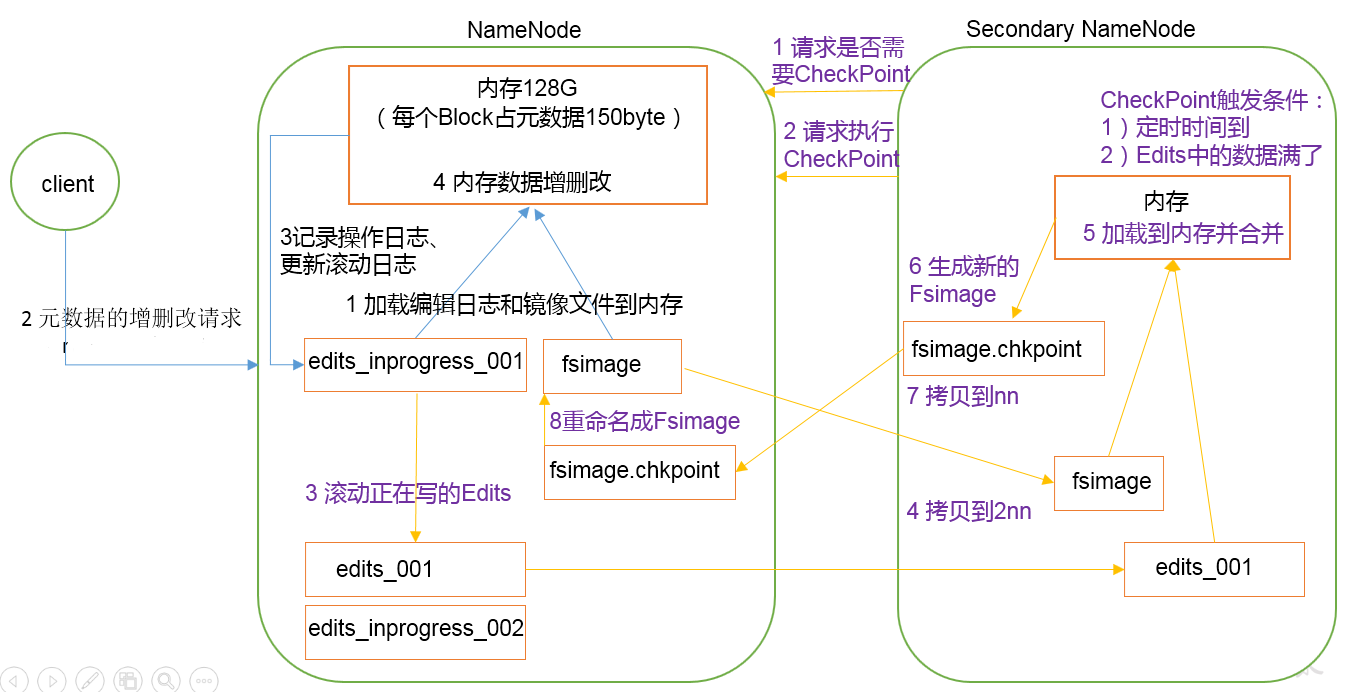
NN工作机制
1.第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存
2.接收客户端的写操作,先记录在日志中,再对元数据进行操作
2NN工作机制
通常情况下
[hdfs-default.xml] <property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property> <property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property> <property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
通常情况下,2NN每隔一分钟检查一次,当edits日志操作次数达到1百万时或距离上次生成Fsimage一小时时,会执行一次CheckPoint.NN接收到执行CheckPonit请求时,会生成一个edits.inprogress日志文件,将后续的操作记录在这个日志里,并且将正在使用的日志重命名为edits.之后NN将未被合并的edits和FsImage拷贝到2NN.2NN将edits和Fsimage拷贝到内存中,生成新的Fsimage.checkpoint,并且拷贝到NN,NN接收到新的Fsimage.checkpoint后,重命名为Fsimage并且替换到之前的Fsimage
可以将Fsimage理解为游戏存档,游戏崩溃后,只能从存档位置再继续玩.有时候如果忘了存档,那么后果将会很凉凉.2NN就好像一个辅助软件,定时为我们存档.
但是一旦游戏崩溃,只是会进入最后的存档处,始终缺少一些~
NN和2NN工作机制详解:
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中
2.Edits.log和Fsimage

Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解的更多相关文章
- HDFS体系结构(NameNode、DataNode详解)
hadoop项目地址:http://hadoop.apache.org/ NameNode.DataNode详解 (一)分布式文件系统概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配 ...
- hadoop中HDFS的NameNode原理
1. hadoop中HDFS的NameNode原理 1.1. 组成 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 1.2. HDFS架构 ...
- Namenode HA原理详解(脑裂)
转自:http://blog.csdn.net/tantexian/article/details/40109331 Namenode HA原理详解 社区hadoop2.2.0 release版本开始 ...
- Hadoop框架:NameNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.存储机制 1.基础描述 NameNode运行时元数据需要存放在内存中,同时在磁盘中备份元数据的fsImage,当元数据有更新或者添加元数据 ...
- Hadoop之HDFS及NameNode单点故障解决方案
Hadoop之HDFS 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/QQ技术交流群:299142667 H ...
- Hadoop框架:HDFS读写机制与API详解
本文源码:GitHub·点这里 || GitEE·点这里 一.读写机制 1.数据写入 客户端访问NameNode请求上传文件: NameNode检查目标文件和目录是否已经存在: NameNode响应客 ...
- HDFS【Namenode、SecondaryNamenode、Datanode】
目录 一. NameNode和SecondaryNameNode 1.NN和2NN 工作机制 2. NN和2NN中的fsimage.edits分析 3.checkpoint设置 4.namenode故 ...
- hadoop 0.20.2伪分布式安装详解
adoop 0.20.2伪分布式安装详解 hadoop有三种运行模式: 伪分布式不需要安装虚拟机,在同一台机器上同时启动5个进程,模拟分布式. 完全分布式至少有3个节点,其中一个做master,运行名 ...
- hadoop2—namenode—HA原理详解
在hadoop1中NameNode存在一个单点故障问题,也就是说如果NameNode所在的机器发生故障,那么整个集群就将不可用(hadoop1中有个SecorndaryNameNode,但是它并不是N ...
随机推荐
- SSM整合的简单实现
整合需要的jar包和源码将在文末给出 本文参考黑马程序员视频,由于视频用的环境和我使用的环境不同,建议使用我的环境及jar包(比较新) 一 整合思路 第一步 整合dao层 mybatis和spring ...
- 一个sql server 实施工程师的反思
自14年开始从事数据库实施,至今(2018-02-16)晃眼间已经四个年头过去了,工作上的能力要求多数能自己解决,可这不应该成为我学习路上的终点.加之总觉得自己对sql 的理解有些浮于表面,所以借着春 ...
- elasticsearch 概念
elasticsearch 来源:https://baike.baidu.com/item/elasticsearch/3411206?fr=aladdin ElasticSearch是一个基于Luc ...
- 【Unity3D】【NGUI】UIRect的Anchor的使用
NGUI版本号:3.6.5 以以下的图,解释下主要的Anchors的使用(能够通过官方的Anchor和Chat样例进行深入学习) Target不是一定要是Sprite.能够是随意的UIRect(UIS ...
- ACM-ICPC(10 / 9)
ACM-ICPC(10.9) 树形DP 树形DP考点很多,状态转移有时会很复杂,但是也有规律可寻,最重要的是抓住父子关系之间的状态转移. 树的最大独立集:尽量选择多的点,使得任何两个结点均不相邻. ...
- Gym 101334C 无向仙人掌
给出图,求他的“仙人掌度”,即求包括他自身的生成子图有多少? 只能删去仙人掌上的叶子的一条边,然后根据乘法原理相乘: 1.怎么求一个仙人掌叶子上有多少边? 可以利用点,边双连通的时间戳这个概念,但是绝 ...
- 【[SDOi2012]Longge的问题】
求\(\sum_{i=1}^ngcd(i,n)\) 考虑枚举\(gcd\),现在答案变成这样 \(\sum_{d|n}d*f(d)\) \(f(d)=\sum_{i=1}^n [gcd(i,n)==d ...
- 使用ToDateTime方法转换日期显示格式
实现效果: 知识运用: Convert类的ToDateTime方法:(将字符串转化为DateTime对象) public static DateTime ToDateTime(string value ...
- 八、IntelliJ IDEA 缓存和索引的介绍及清理方法
这样一句话“ 对于首次创建或打开的新项目,IntelliJ IDEA 都会创建项目索引,大型项目在创建索引的过程中可能会出现卡顿的现象,因此强烈建议在 IntelliJ IDEA 创建索引的过程中不要 ...
- 【洛谷P1726】上白泽慧音
上白泽慧音 题目链接 强联通分量模板题,Tarjan求强联通分量,记录大小即可 #include<iostream> #include<cstring> #include< ...