关于SIFT,GIFT在旋转不变性上的对比实验
关于SIFT,GIFT在旋转不变性上的对比实验
这篇文章不讨论SIFT,GIFT的实现原理,只从最终匹配结果的准确度上来进行对比。
回顾
先简单回顾一下,两种方法略有不同。SIFT是检测出各个特征点,并得到特征点描述子。
GIFT是先使用其它算法(SIFT,SuperPoint,Harris)等方法得到特征点,然后将原图加检测得到的特征点输入网络得到特征点描述子。
用特征点描述子进行匹配,我们可以得到如下的试验结果:
| 原图1 | 原图2 | GIFT | SIFT |
|---|---|---|---|
 |
 |
 |
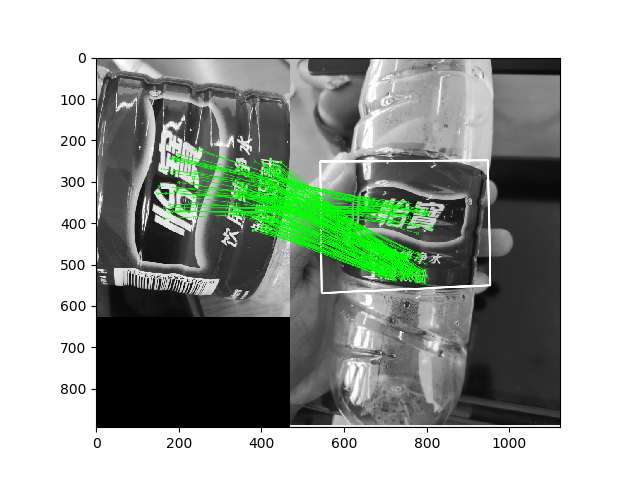 |
 |
 |
 |
 |
准确率测试
但是仔细观察GIFT的匹配结果,肉眼就能看出很多错误的匹配。(SIFT,GIFT都使用的是FLANN)
对此,我设计了一个方法来估算一下二者匹配的准确率,也能侧面反映出描述子的健壮性。
思路:一张图片\(img\),将其旋转90°,得到\(img_{}'\),然后分别使用SIFT,GIFT进行特征点匹配,由于\(ima\)与\(ima_{}'\)的像素点存在一个旋转矩阵的对应关系,我们可以据此来大体估算两种方法的准确率。
实验环境:pycharm, cpu, opencv
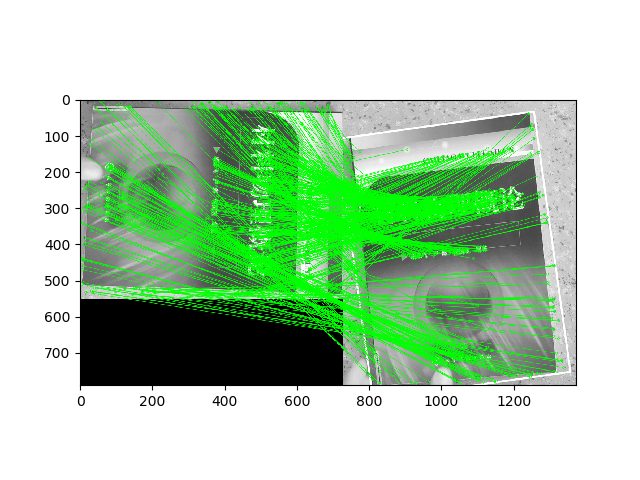
- Test1
 |
 |
 |
|---|
我们看一下在这两张图片上的匹配结果:
| SIFT | SIFT points+GIFT | SuperPoint points+GIFT | |
|---|---|---|---|
| 特征点匹配数目 | 5184 | 1506 | 630 |
| 正确匹配数目 | 5038 | 876 | 358 |
| 准确率 | 0.9718 | 0.5817 | 0.5682 |
特征点匹配对应的就是附录代码里的good_mathes,正确匹配数目是使用两张图片的旋转矩阵计算而来,也就是,\(img\)里的一个特征点坐标\(p\),对应\(img_{}'\)里的\(p_{}'\), 有$p_{}' = Mp $。详情请查看附录代码。
Test2



| SIFT | SIFT points+GIFT | SuperPoint points+GIFT | |
|---|---|---|---|
| 特征点匹配数目 | 594 | 256 | 216 |
| 正确匹配数目 | 587 | 155 | 127 |
| 准确率 | 0.9882 | 0.6055 | 0.5880 |
总结
虽然GIFT具有一定的旋转不变性,但是效果不是很好,使用特征描述子匹配出的错点比较多,特征描述子的健壮性也不如SIFT通用。
最后要说的是,受限于笔者目前的知识水平和技术水平,不排除在复现GIFT原代码时出现概念性错误,或者是由于粗心导致的细节疏忽。所以此篇文章仅供参考,如果您有新的想法或者建议,欢迎在评论区指出或者发送邮件(lightwxz@foxmail.com)讨论。实验代码请看附录。
核心代码
GIFT_Test.py 代码修改自GIFT论文作者在GitHub发布的demo.ipynb
备注:
- 复现此代码时需要修改test_acc下的M矩阵,因为实验所用的旋转变更了坐标系,因此每张图片的旋转矩阵都是不同的
GIFT_Test.py
import numpy as np
import torch
from skimage.io import imread
from network.wrapper import GIFTDescriptor
from train.evaluation import EvaluationWrapper, Matcher
from utils.superpoint_utils import SuperPointWrapper, SuperPointDescriptor
import matplotlib.pyplot as plt
import cv2
MIN_MATCH_COUNT = 10
def test_acc(good, kps0, kps1):
# 给特征点末尾添加一列变为其次坐标
points1 = np.insert(kps0, 2, values=np.ones(kps0.shape[0]), axis=1)
points2 = np.insert(kps1, 2, values=np.ones(kps1.shape[0]), axis=1)
# 旋转矩阵
M = np.array([[0, -1, 528],
[1, 0, 0],
[0, 0, 1]], dtype=np.float32)
# 图一是图二旋转 90°得到,因此像素坐标乘以一个旋转矩阵即可
count = 0
for i in good:
pts_after_rotate = M.dot(points1[i.queryIdx].T)
if (pts_after_rotate - points2[i.trainIdx]).sum() < 3:
count += 1
print(len(good))
print(count)
if __name__ == '__main__':
detector = SuperPointWrapper(EvaluationWrapper.load_cfg('configs/eval/superpoint_det.yaml'))
gift_desc = GIFTDescriptor(EvaluationWrapper.load_cfg('configs/eval/gift_pretrain_desc.yaml'))
superpoint_desc = SuperPointDescriptor(EvaluationWrapper.load_cfg('configs/eval/superpoint_desc.yaml'))
# matcher = Matcher(EvaluationWrapper.load_cfg('configs/eval/match_v0.yaml'))
img0 = imread("demo/woman.jpg")
img1 = imread("demo/woman_ro.jpg")
# 此处可以通过修改注释来切换检测器
# to use superpoint detector
# kps0, _ = detector(img0)
# kps1, _ = detector(img1)
# to use SIFT detector
sift = cv2.SIFT_create()
kps0, _ = sift.detectAndCompute(img0, None)
kps1, _ = sift.detectAndCompute(img1, None)
kps0 = np.array([[i.pt[0], i.pt[1]] for i in kps0])
kps1 = np.array([[i.pt[0], i.pt[1]] for i in kps1])
# -----------------------
# 得到GIFT特征描述子
des1 = gift_desc(img0, kps0)
des2 = gift_desc(img1, kps1)
#描述子匹配
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches1 = flann.knnMatch(des1, des2, k=2)
# matches2 = flann.knnMatch(des2, des1, k=1)
ratio_thresh = 0.98 # 此处设置为0.7,0.8时就一个都匹配不上了。
good_matches = []
for m, n in matches1:
if m.distance < ratio_thresh * n.distance:
good_matches.append(m)
test_acc(good_matches, kps0, kps1)
kps0 = [cv2.KeyPoint(kps0[i][0], kps0[i][1], 1)
for i in range(kps0.shape[0])]
kps1 = [cv2.KeyPoint(kps1[i][0], kps1[i][1], 1)
for i in range(kps1.shape[0])]
img_matches = np.empty(
(max(img0.shape[0], img1.shape[0]), img0.shape[1] + img1.shape[1], 3),
dtype=np.uint8)
cv2.drawMatches(img0, kps0, img1, kps1, good_matches, img_matches,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv2.namedWindow("Good Matches of GIFT", 0)
cv2.resizeWindow("Good Matches of GIFT", 1024, 1024)
cv2.imshow('Good Matches of GIFT', img_matches)
cv2.waitKey()
SIFT_Test.py
from __future__ import print_function
import cv2 as cv
import numpy as np
pic1 = "data/woman.jpg"
pic2 = "data/woman_ro.jpg"
def test_acc(good, kps0, kps1):
count = 0
# 给特征点末尾添加一列变为其次坐标
points1 = np.insert(kps0, 2, values=np.ones(kps0.shape[0]), axis=1)
points2 = np.insert(kps1, 2, values=np.ones(kps1.shape[0]), axis=1)
# 旋转矩阵
M = np.array([[0, -1, 528],
[1, 0, 0],
[0, 0, 1]], dtype=np.float32)
# 图一是图二旋转 90°得到,因此像素坐标乘以一个旋转矩阵即可
count = 0
for i in good:
pts_after_rotate = M.dot(points1[i.queryIdx].T)
if (pts_after_rotate-points2[i.trainIdx]).sum() < 3:
count += 1
print(len(good))
print(count)
img_object = cv.imread(pic1)
img_scene = cv.imread(pic2)
if img_object is None or img_scene is None:
print('Could not open or find the images!')
exit(0)
#-- Step 1: Detect the keypoints using SURF Detector, compute the descriptors
sift = cv.SIFT_create()
keypoints_obj, descriptors_obj = sift.detectAndCompute(img_object,None)
keypoints_scene, descriptors_scene = sift.detectAndCompute(img_scene,None)
#-- Step 2: Matching descriptor vectors with a FLANN based matcher
# Since SURF is a floating-point descriptor NORM_L2 is used
matcher = cv.DescriptorMatcher_create(cv.DescriptorMatcher_FLANNBASED)
knn_matches = matcher.knnMatch(descriptors_obj, descriptors_scene, 2)
#-- Filter matches using the Lowe's ratio test
ratio_thresh = 0.75
good_matches = []
for m,n in knn_matches:
if m.distance < ratio_thresh * n.distance:
good_matches.append(m)
print("The number of keypoints in image1 is", len(keypoints_obj))
print("The number of keypoints in image2 is", len(keypoints_scene))
#
kp1 = np.array([[i.pt[0], i.pt[1]] for i in keypoints_obj], dtype=np.int32)
kp2 = np.array([[i.pt[0], i.pt[1]] for i in keypoints_scene], dtype=np.int32)
test_acc(good_matches, kp1, kp2)
#-- Draw matches
img_matches = np.empty((max(img_object.shape[0], img_scene.shape[0]), img_object.shape[1]+img_scene.shape[1], 3), dtype=np.uint8)
cv.drawMatches(img_object, keypoints_obj, img_scene, keypoints_scene, good_matches, img_matches, flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv.namedWindow("Good Matches of SIFT", 0)
cv.resizeWindow("Good Matches of SIFT", 1024, 1024)
cv.imshow('Good Matches of SIFT', img_matches)
cv.waitKey()
关于SIFT,GIFT在旋转不变性上的对比实验的更多相关文章
- SIFT,SuperPoint在图像特征提取上的对比实验
SIFT,SuperPoint都具有提取图片特征点,并且输出特征描述子的特性,本篇文章从特征点的提取数量,特征点的正确匹配数量来探索一下二者的优劣. 视角变化较大的情况下 原图1 原图2 SuperP ...
- 局部二值模式(Local Binary Patterns)纹理灰度与旋转不变性
Multiresolution Gray Scale and Rotation Invariant Texture Classification with Local Binary Patterns, ...
- CNN对位移、尺度和旋转不变性的讨论
CNN得益于全局共享权值和pool操作,具有平移不变性. 对于尺度不变性,是没有或者说具有一定的不变性(尺度变化不大),实验中小目标的检测是难点,需要采用FPN或者其他的方式单独处理. 对于旋转不变性 ...
- 在阿里云上搭建 Spark 实验平台
在阿里云上搭建 Spark 实验平台 Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程 [传统文化热爱者] 阿里云服务器搭建spark特别坑的地方 阿里云实现Hadoop+Sp ...
- 记一次burp suite文件上传漏洞实验
一·文件上传漏洞概念 文件上传漏洞是指 Web 服务器允许用户在没有充分验证文件名称.类型.内容或大小等内容的情况下将文件上传到其文件系统.未能正确执行这些限制可能意味着 即使是基本的图像上传功能也可 ...
- LCD驱动移植在在mini2440(linux2.6.29)和FS4412(linux3.14.78)上实现对比(deep dive)
1.Linux帧缓冲子系统 帧缓冲(FrameBuffer)是Linux为显示设备提供的一个接口,用户可以将帧缓冲看成是显示内存的一种映像,将其映射到进程地址空间之后,就可以直接进行读写操作,而写操作 ...
- IIC驱动移植在linux3.14.78上的实现和在linux2.6.29上实现对比(deep dive)
首先说明下为什么写这篇文章,网上有许多博客也是介绍I2C驱动在linux上移植的实现,但是笔者认为他们相当一部分没有分清所写的驱动时的驱动模型,是基于device tree, 还是基于传统的Platf ...
- Suspend to RAM和Suspend to Idle分析,以及在HiKey上性能对比
Linux内核suspend状态 Linux内核支持多种类型的睡眠状态,通过设置不同的模块进入低功耗模式来达到省电功能.目前存在四种模式:suspend to idle.power-on standb ...
- 中英文维基百科语料上的Word2Vec实验
最近试了一下Word2Vec, GloVe 以及对应的python版本 gensim word2vec 和 python-glove,就有心在一个更大规模的语料上测试一下,自然而然维基百科的语料进入了 ...
- 在Spark上用Scala实验梯度下降算法
首先参考的是这篇文章:http://blog.csdn.net/sadfasdgaaaasdfa/article/details/45970185 但是其中的函数太老了.所以要改.另外出发点是我自己的 ...
随机推荐
- 展锐Android平台增加gadget 虚拟usb串口
方案一:需要修改展锐现有Windows端驱动,增加一组MI接口.由于无法推动展锐修改Windows驱动,该方案不推荐. SL8541E/device/sprd/sharkle/common/rootd ...
- 直播预览层(AVCaptureVideoPreviewLayer)底层实现
分析sampleBuffer(帧数据) 通过设置AVCaptureVideoDataOutput的代理,就能获取捕获到一帧一帧数据 [videoOutput setSampleBufferDelega ...
- Linux操作系统基础知识
一.输入法的切换Application ----> System Tools ----> Settings ----> Rejino&language ----> In ...
- Redis持久化(RDB、AOF)
为什么要持久化 Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘中,那么一旦服务器进程退出,服务器的数据库状态就会消失(即断电即失).为了保证数据不丢失,我们需要将内存中的数据存储到磁盘, ...
- redux初探
action是一个普通对象 里面必须有一个type字段,代表将要执行的行为,其他字段自己规划. action只是描述了将要发生的事情并不能直接修改状态 action创建函数 尽量是一个纯函数,他返回的 ...
- Docker问题日志--工作中遇到的问题及解决
启动Docker容器时遇到错误 标签: docker, docker run, docker start, 环境: Docker version 1.12.6, build 1398f24/1.12. ...
- 使用Python的一维卷积
学习&转载文章:使用Python的一维卷积 背景 在开发机器学习算法时,最重要的事情之一(如果不是最重要的话)是提取最相关的特征,这是在项目的特征工程部分中完成的. 在CNNs中,此过程由网络 ...
- 分圆多项式(cyclotomic polynomial)
最近论文中经常遇到分圆多项式,现在系统的学习一下! 本原单位根 之前介绍n次单位根,现在详细学习一下n次本原单位根(n-th primitive unit root) 一个复数是n次单位根,当且仅当具 ...
- Bottleup pg walkthrough Intermediate
一开始看到page=view/.html的时候就想到目录穿越了尝试../../../../../../../../../../../etc/passwd 发现不行 找半天其他可能存在漏洞的地方又找不到 ...
- Flink白话解析Watermark
一.摘要 如果想使用Flink,Flink的Watermark是很难绕过去的概念.本文帮大家梳理Watermark概念 二.Watermark疑问 1.Flink应用的常见需求是什么 如公司运营一个官 ...