袋鼠云批流一体分布式同步引擎ChunJun(原FlinkX)的前世今生
一、前言
ChunJun(原FlinkX)是一个基于Flink提供易用、稳定、高效的批流统一的数据集成工具,是袋鼠云一站式大数据开发平台-数栈DTinsight的核心计算引擎,其技术架构基于实时计算框架Flink,打造出“具有袋鼠特色”的实时计算引擎。
开源项目地址:
https://github.com/DTStack/chunjun
https://gitee.com/dtstack_dev_0/chunjun
开源技术交流群:
钉钉群:30537511
二、从FlinkX到ChunJun
ChunJun脱胎于袋鼠云数栈自主研发的批流统一的数据同步工具FlinkX。
2016年,数栈技术团队初步研发完成了一款基于Flink的分布式离线/实时数据同步插件——FlinkX,它可实现多种异构数据源高效的数据同步,支持双向读写和多种异构数据源。有它助力,袋鼠云在批流一体的研究实践以更迅猛的势头往前挺进。
2018年4月,秉承着开源共享理念的数栈技术团队在github上开源了FlinkX,历经4年多的发展,FlinkX从当初的一个小项目,成长为拥有2900+star,1300+fork的开源项目。
从开源的第一天,数栈技术团队从未停下技术探索和社区回馈的脚步,在4年多的时间里先后开源了flinkx、flinkStreamSQL、jlogstash、easyagent、doraemon、molecule、Taier,袋鼠云数栈开源家族愈发壮大,开源项目系列得到了广泛的发展,相继在各类企业中落地应用。
今年,数栈技术团队决定对开源项目进行整体升级,并推出自主开源计划——DTstackCon,其中大数据开源项目系列以“十大名剑”作为概念来源,承载着数栈技术团队对它们能如利剑,为社区数字化进程的发展之路披荆斩棘的向往。
正是怀揣着这样殷切的期望,我们决定正式将FlinkX更名为ChunJun!
ChunJun命名取自于中国古代十大名剑之一的纯钧


(ChunJun logo)
纯钧是春秋战国时期铸剑名师欧冶子为越王勾践所铸,其剑身取材珍贵,锋利无比,剑刃就象壁立千丈的断崖崇高而巍峨,剑身更是历经千年而不蚀,代表稳定而强大坚定的意志,正如ChunJun作为袋鼠云数栈的核心计算引擎,承载着实时平台、离线平台、数据资产等多个应用的底层数据同步及计算,其强大的功能保障着客户业务数据的一致性。

ChunJun的logo主体的字母C是由许多平行四边形组成的,这个组合有递进、有组合,正是ChunJun的稳定、聚合体、分布式、集成的开发理念的具象体现。
同时也传达出ChunJun核心观念:提供一个易用、稳定、高效的数据同步和集成工具。
底层采用六边形蜂巢结构,因为六边形的蜂巢是“最省劳动力、也最省材料的选择”。多个六边形排列在一起之间没有空隙,这种排列也被称为是最稳定的排列方式。稳定,从来是我们开发的第一考虑。
三、什么是ChunJun
ChunJun是一个基于Flink 提供易用、稳定、高效的批流统一的数据集成工具,既可以采集静态的数据,比如MySQL,HDFS等,也可以采集实时变化的数据,比如binlog,Kafka等。同时ChunJun也是一个支持原生FlinkSql所有语法和特性的计算框架。目前ChunJun在实际应用过程中已服务了上百家客户,经过多次迭代与沉淀,积累了大量的客户案例。
ChunJun主要应用于大数据开发平台的数据同步/数据集成模块,通常采用将底层高效的同步插件和界面化的配置方式相结合的方式,使大数据开发人员可简洁、快速的完成数据同步任务开发,实现将业务数据库的数据同步至大数据存储平台,从而进行数据建模开发,以及数据开发完成后,将大数据处理好的结果数据同步至业务的应用数据库,供企业数据业务使用。
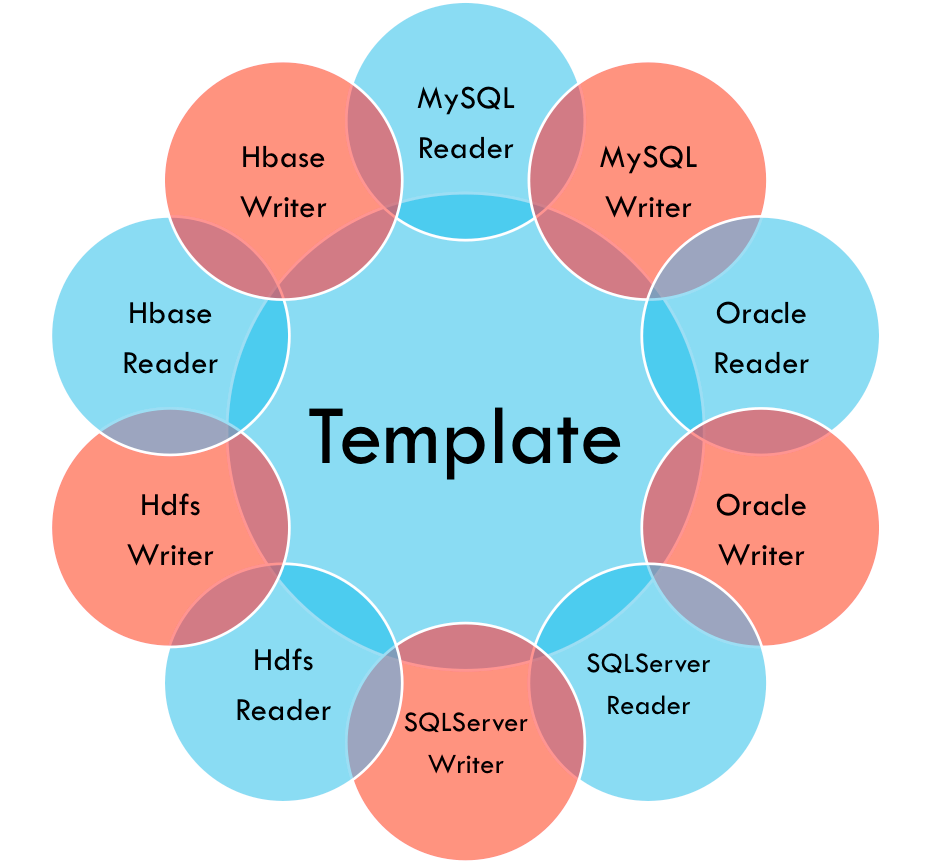
四、ChunJun功能特点
ChunJun具有以下几大特色功能点:
1、超丰富
* 丰富的插件种类:ChunJun上下游插件多达40种,如常见的mysql、binlog、logminer等,大部分插件都支持source/reader、sink/writer及维表功能。
* 丰富的任务执行模式:支持本地拆箱即用式-local 模式,Flink 自带 standalone 模式,常用调度 yarn session 和 yarn pre-job 模式,以及与k8s 结合部署的 k8s 模式。
* 丰富的任务类型:ChunJun支持json 同步任务,以及sql 计算任务,用户可以根据自己的需要,考虑是使用配置更加灵活的json同步任务,还是计算更加强大的sql计算任务。
2、超灵活
* 脏数据收集系统插件化:面对不同的业务场景,可以配置不同的脏数据配置,灵活处理,例如:
是否将脏数据落盘处理;
是否在日志中打印脏数据信息;
脏数据最大条数限制;
脏数据存储到不同类型的数据源等。
* 指标系统插件化:与脏数据插件化类似,指标系统在设计上也采用了插件化设计,用户根据自己的业务场景,灵活配置指标系统。
3、超强大
* 支持增量同步: 对于某些业务库的表,表中的数据基本只有插入操作,随着业务的运行,表中的数据会越来越大。如果每次都整表同步的话,消耗的时间及资源也会越来越多,因此需要一个增量同步的功能,每次只同步增加部分的数据,对于已经同步过的数据则不再进行重复的同步工作。
增量同步是针对于两个及以上数量的同步任务来说的,对于初次执行增量同步的某张表而言,该次同步实质上是整表同步,不同的是在任务执行结束后会记录增量字段的结束值(endLocation)并将其上传至prometheus供后续使用。
在构建下次增量任务时获取该endLocation并作为上述过滤条件的参数值(startLocation)。在任务解析到增量任务配置时,会根据startLocation的有无自动构建过滤条件,并将其拼接至where条件中,最终构建出一条如:select id, name, age from test where id > 100的SQL,从而达到增量读取的目的。
* 支持断点续传:对于某些业务库的表,其数据量可能非常大,同步可能耗时非常久。如果在同步过程中由于某些原因导致任务失败,从头再来的话成本非常大,因此需要一个断点续传的功能从任务失败的地方继续。
断点续传的本质是通过Flink的checkpoint机制实现的,在每次checkpoint时,reader插件会保存当前读取到的字段的值,writer插件则会在保存writer中的指标及其他信息,然后将writer中的事务提交。
* 支持同步DDL数据:在客户真实场景中,对于DDL数据目前无法处理。在袋鼠内部,ChunJun借助外部数据源,支持监听DDL语句,并对DDL手动执行。
五、ChunJun未来规划
ChunJun能从一个小项目发展到今天离不开社区开发者们的支持,我们将以此为基,秉承初心,继续大力发展ChunJun开源框架。
1、技术发展
* 支持数据湖:ChunJun团队正在探索湖仓一体的建设
* 数据还原的完善:支持对DDL自动解析并交由下游数据源自动执行
* 更丰富的插件:不仅仅是丰富同步插件,也还要丰富脏数据插件,指标插件等
* 更完善的调度:完善k8s调度,给予用户更完整的k8s方案
* 性能与稳定性:ChunJun团队持续优化代码结构,提高ChunJun性能与稳定性
2、社区发展
* ChunJun技术融合方案
* ChunJun系列直播公开课
* ChunJun Meetup技术沙龙会
袋鼠云批流一体分布式同步引擎ChunJun(原FlinkX)的前世今生的更多相关文章
- 带你玩转Flink流批一体分布式实时处理引擎
摘要:Apache Flink是为分布式.高性能的流处理应用程序打造的开源流处理框架. 本文分享自华为云社区<[云驻共创]手把手教你玩转Flink流批一体分布式实时处理引擎>,作者: 萌兔 ...
- DataPipeline CTO陈肃:构建批流一体数据融合平台的一致性语义保证
文 | 陈肃 DataPipelineCTO 交流微信 | datapipeline2018 本文完整PPT获取 | 关注公众号后,后台回复“陈肃” 首先,本文将从数据融合角度,谈一下DataPipe ...
- 阿里重磅开源全球首个批流一体机器学习平台Alink,Blink功能已全部贡献至Flink
11月28日,Flink Forward Asia 2019 在北京国家会议中心召开,阿里在会上发布Flink 1.10版本功能前瞻,同时宣布基于Flink的机器学习算法平台Alink正式开源,这也是 ...
- 统一批处理流处理——Flink批流一体实现原理
实现批处理的技术许许多多,从各种关系型数据库的sql处理,到大数据领域的MapReduce,Hive,Spark等等.这些都是处理有限数据流的经典方式.而Flink专注的是无限流处理,那么他是怎么做到 ...
- Flink 是如何统一批流引擎的
关注公众号:大数据技术派,回复"资料",领取1000G资料. 本文首发于我的个人博客:Flink 是如何统一批流引擎的 2015 年,Flink 的作者就写了 Apache Fli ...
- 袋鼠云研发手记 | 数栈·开源:Github上400+Star的硬核分布式同步工具FlinkX
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 袋鼠云研发手记 | 开源·数栈-扩展FlinkSQL实现流与维表的join
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 最佳实践:Pulsar 为批流处理提供融合存储
非常荣幸有机会和大家分享一下 Apache Pulsar 怎样为批流处理提供融合的存储.希望今天的分享对做大数据处理的同学能有帮助和启发. 这次分享,主要分为四个部分: 介绍与其他消息系统相比, Ap ...
- 华夏基金X袋鼠云:基金业数字化转型,为什么说用户才是解题答案?
"精准营销是以客户为中心,运用各种可利用的方式,在恰当的时间,以恰当的价格,通过恰当的渠道,向恰当的顾客提供恰当的产品." 这是学者许瑾在科特勒精准营销理论的基础上,从实践的角度对 ...
- DRDS分布式SQL引擎—执行计划介绍
摘要: 本文着重介绍 DRDS 执行计划中各个操作符的含义,以便用户通过查询计划了解 SQL 执行流程,从而有针对性的调优 SQL. DRDS分布式SQL引擎 — 执行计划介绍 前言 数据库系统中,执 ...
随机推荐
- 寻找可靠的长久的存储介质之旅,以及背后制作的三个网页“图片粘贴转base64”、“生成L纠错级别的QR码”、“上传文件转 base64以及粘贴 base64 转可下载文件”
其实对于目前的形式来说,虽然像 U 盘.固态硬盘.甚至光盘这些信息储存介质(设备)的容量越来越高,但是不得不说这些设备的可靠性依然像悬着的一块石头,虽然这块石头确实牢牢的粘在天花板上,但是毕竟是粘上去 ...
- Docker,vs2019下 使用.net core创建docker镜像 遇到的一些问题
步骤主要分为以下几步: 1.创建docker for linux 的.netcore 项目(vs 自动创建了dockerfile 如果没有需要自己创建在根目录下) 2.编译项目到指定目录下 3.b ...
- nginx集群同步方案
之前公司同事写过rsync加触发nginx reload脚本,适合nginx配置内容完全一致的情况. 今天写一个同步指定文件的脚本,修改完主服务器.使用scp传输到其他nginx服务器上重启NGINX ...
- 【Web】前端框架对微软老旧浏览器的支持
零.原因 最近要做一个项目,要能在学校机房运行的,也要在手机上运行.电脑和手机,一次性开发,那最好的就是响应式前端框架了.手机和正常的电脑兼容性问题应该都不大,但是学校机房都是Win7的系统,自带的都 ...
- study Python3【3】的函数
Python的函数定义简单,但灵活度非常大.功能强大意味复杂.为了复习,把廖雪峰老师的该课程做个回顾. 参数有:必选参数.默认参数.可变参数.关键字参数.命名关键字参数. 计算x的n次方函数: def ...
- [T.2] 团队项目:选题和需求分析
项目 内容 这个作业属于哪个课程 2025年春季软件工程(罗杰.任健) 这个作业的要求在哪里 T.2团队项目:选题和需求分析 团队在这个课程的目标是 学习软件工程相关知识,培养编程和团队协作能力,做出 ...
- BeanCreationException: Error creating bean with name 'dataSource' defined in class path resource
在练习中遇到的,我的情况是: 打算在common中建立student实体类,想到可能其他模块也会用到这个类,但是一些注解比如,@TableId等等需要用到mybatis-plus的依赖,所以我就把依赖 ...
- 修显示器led屏幕能亮但是显示异常
用电吹风热风大风 对着显示器的 ' led 区域 ' 吹十分钟 吹显示器线插口 电源线 插口 机箱 断电吹 // 温度挺高 还得吹显卡接口 线也要换新的 插口需要用线的接口 打磨金属 ...
- UGUI 事件穿透使Scrollrect 滚动
public class TouchPenetrate : MonoBehaviour, IPointerClickHandler,IBeginDragHandler,IDragHandler,IPo ...
- 1.4K star!几分钟搞定AI视频创作,这个开源神器让故事可视化如此简单!
嗨,大家好,我是小华同学,关注我们获得"最新.最全.最优质"开源项目和高效工作学习方法 story-flicks 是一个基于AI技术的自动化视频生成工具,能够将文字剧本快速转化为高 ...