OpenCV-Python:K值聚类
关于K聚类,我曾经在一篇博客中提到过,这里简单的做个回顾。
KMeans的步骤以及其他的聚类算法
K-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算
其他聚类算法:二分K-均值
讲解一下步骤,其实就是说明一下伪代码
随机选择k个点作为起始质心
当任意一个点的簇分配结果发生改变时
对数据集中的每个数据点
对每个质心
计算质心与数据点之间的距离
将数据分配到距其最近的簇
对每一个簇,计算簇中所有点的均值并将均值作为质心
OpenCV中使用cv2.kmeans()对数据进行分类
理解函数的参数
输入参数:cv2.kmeans(data,K, bestLabels,criteria,attempt,flags)
1. data:应该是np.float32类型的数据,每个特征应该放在一列。
2. K:聚类的最终数目
3. criteria:终止迭代的条件。当条件满足,算法的迭代终止。它应该是一个含有3个成员的元组,它们是(type,max_iter, epsilon):
type终止的类型:有如下三种选择:
- cv2.TERM_CRITERIA_EPS 只有精确度epslion满足时停止迭代
- cv2.TERM_CRITERIA_MAX_ITER 当迭代次数超过阈值时停止迭代
– cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER 上面的任何一个条件满足时停止迭代
max_iter:最大迭代次数
epsilon:精确度阈值
4. attempts:使用不同的起始标记来执行算法的次数。算法会返回紧密度最好的标记。紧密度也会作为输出被返回
5. flags:用来设置如何选择起始中心。通常我们有两个选择:cv2.KMEANS_PP_CENTERS和 cv2.KMEANS_RANDOM_CENTERS。
输出参数:
1. compactness:紧密度返回每个点到相应中心的距离的平方和
2. labels:标志数组,每个成员被标记为0,1等
3. centers:有聚类的中心组成的数组
仅有一个特征的数据
假设我们有一组数据,每个数据只有一个特征。例如前面的T恤问题,我们只用身高来决定T恤的大小。我们来产生一些随机数据,并使用Matplotlib
# 随机在25~100之间产生25个值
x = np.random.randint(25,100,25)
y = np.random.randint(175,255,25)
z = np.hstack((x,y))
z = z.reshape((50,1))
z = np.float32(z)
plt.hist(z,256,[0,256]),plt.show()
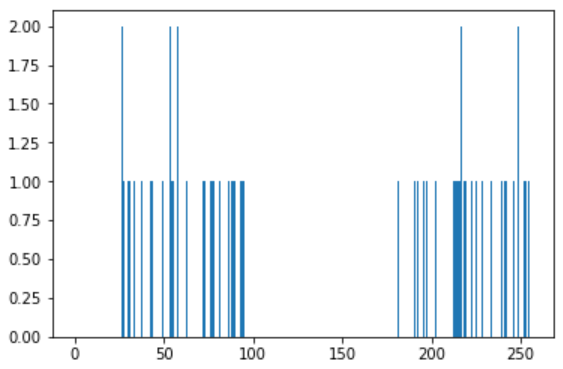
我们使用KMeans函数。先设置好终止条件。10次迭代或者精确度epsilon=1.0
# Define criteria = ( type, max_iter = , epsilon = 1.0 )
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, , 1.0) # Set flags (Just to avoid line break in the code)
flags = cv2.KMEANS_RANDOM_CENTERS # Apply KMeans
compactness,labels,centers = cv2.kmeans(z,,None,criteria,,flags)
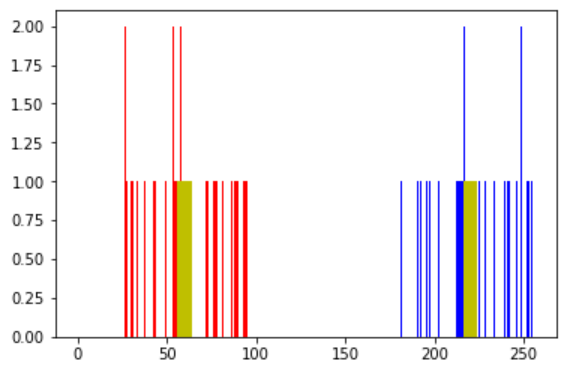
把数据分成两组
A = z[labels==]
B = z[labels==]
现在将 A 组数用红色表示,将 B 组数据用蓝色表示,重心用黄色表示。
# Now plot 'A' in red, 'B' in blue, 'centers' in yellow
plt.hist(A,,[,],color = 'r')
plt.hist(B,,[,],color = 'b')
plt.hist(centers,,[,],color = 'y')
plt.show()
含有多个特征的数据
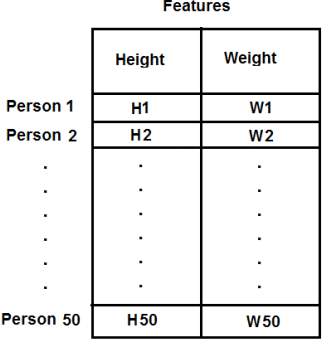
T恤我们只考虑了身高,现在将体重也考虑进去,也就是两个特征。在本例中我们的测试数据是50x2的向量,其中包含50个人的身高和体重。第一列对应身高,第二列对应体重。如下图所示:
import numpy as np
import cv2
from matplotlib import pyplot as plt X = np.random.randint(,,(,))
Y = np.random.randint(,,(,))
Z = np.vstack((X,Y)) # convert to np.float32
Z = np.float32(Z) # define criteria and apply kmeans()
# 迭代次数为10次,精确度为1.
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, , 1.0)
ret,label,center=cv2.kmeans(Z,,None,criteria,,cv2.KMEANS_RANDOM_CENTERS) # Now separate the data, Note the flatten()
A = Z[label.ravel()==]
B = Z[label.ravel()==] # Plot the data
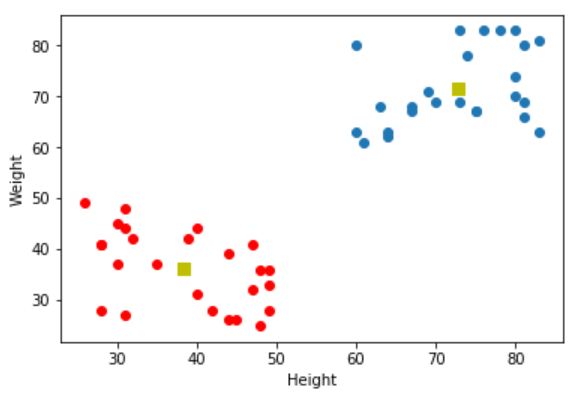
plt.scatter(A[:,],A[:,])
plt.scatter(B[:,],B[:,],c = 'r')
plt.scatter(center[:,],center[:,],s = ,c = 'y', marker = 's')
plt.xlabel('Height'),plt.ylabel('Weight')
plt.show()
颜色量化
颜色量化就是减少图片中颜色数目的一个过程,其原因是为了减少内存消耗。现在有3个特征:R,G,B,所以我们需要把图片数据变形成Mx3(M是图片中像素点的数目)的向量。聚类完成后,我们用聚类中心值替换与其同簇的像素值,这样结果图片就只含指定数目的颜色了。
分别取K=2、4、8
import numpy as np
import cv2 img = cv2.imread('home.jpg')
Z = img.reshape((-,)) # convert to np.float32
Z = np.float32(Z) # define criteria, number of clusters(K) and apply kmeans()
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, , 1.0)
K =
ret,label,center=cv2.kmeans(Z,K,None,criteria,,cv2.KMEANS_RANDOM_CENTERS) # Now convert back into uint8, and make original image
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((img.shape)) cv2.imshow('K=2',res2)
cv2.imwrite('K=2.png', res2)
cv2.waitKey()
cv2.destroyAllWindows()

OpenCV-Python:K值聚类的更多相关文章
- 机器学习之路:python k均值聚类 KMeans 手写数字
python3 学习使用api 使用了网上的数据集,我把他下载到了本地 可以到我的git中下载数据集: https://github.com/linyi0604/MachineLearning 代码: ...
- 数学建模及机器学习算法(一):聚类-kmeans(Python及MATLAB实现,包括k值选取与聚类效果评估)
一.聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好.我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结 ...
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- Kmeans算法的K值和聚类中心的确定
0 K-means算法简介 K-means是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一. K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的 ...
- Python实现kMeans(k均值聚类)
Python实现kMeans(k均值聚类) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=> ...
- KMeans聚类 K值以及初始类簇中心点的选取 转
本文主要基于Anand Rajaraman和Jeffrey David Ullman合著,王斌翻译的<大数据-互联网大规模数据挖掘与分布式处理>一书. KMeans算法是最常用的聚类算法, ...
- R语言中聚类确定最佳K值之Calinsky criterion
Calinski-Harabasz准则有时称为方差比准则 (VRC),它可以用来确定聚类的最佳K值.Calinski Harabasz 指数定义为: 其中,K是聚类数,N是样本数,SSB是组与组之间的 ...
- 机器学习方法(七):Kmeans聚类K值如何选,以及数据重抽样方法Bootstrapping
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入.我的博客写一些自己用得到东西,并分享给 ...
随机推荐
- Matlab 中S-函数的使用 sfuntmpl
function [sys,x0,str,ts,simStateCompliance] = sfuntmpl(t,x,u,flag) %SFUNTMPL General MATLAB S-Functi ...
- Docke--基础篇
什么是Docker? Docker 最初是dotCloud公司创始人Solomon Hykes在法国期间发起的一个公司内部项目,它是基于dotCloud公司多年云服务技术的一次革新,并与2013年3月 ...
- 使用Excel VBA编程将网点的百度坐标转换后标注到高德地图上
公司网点表存储的坐标是百度坐标,现需要将网点位置标注到高德地图上,研究了一下高德地图的云图数据模版 http://lbs.amap.com/yuntu/reference/cloudstorage和坐 ...
- 解决php -v查看到版本与phpinfo()版本不一致问题
安装p7后发现phpinfo的版本是7.2.12,而php -v查看的却是5.4.16 应该是php.ini的配置文件有问题. 查看文件,有两个 查看cli执行的文件是哪一个? 再查看phpinfo用 ...
- Python菜鸟快乐游戏编程_pygame(3)
Python菜鸟快乐游戏编程_pygame(博主录制,2K分辨率,超高清) https://study.163.com/course/courseMain.htm?courseId=100618802 ...
- 异常详细信息: System.IO.FileLoadException: 未能加载文件或程序集“Office, Version=7.0.3300.0,
导出Excel程序调试起来很正常,发布到服务器上却出错. 错误:未能加载文件或程序集“Office, Version=2.2.0.0, Culture=neutral, PublicKeyToken= ...
- 使用百度云 BOS 和 C# SDK 开发数据存储
Ø 简介 本文主要介绍如何使用百度云的 C# SDK 操作 BOS(Baidu Object Storage/百度对象存储),以及常见问题和解决办法.本文将以以下几点展开学习: 1. 基本介绍 ...
- Technocup 2019 - Elimination Round 1
http://codeforces.com/contest/1030 B. Vasya and Cornfield 判断点是否在矩形内(包括边界) 把每条边转化为一个不等式 public static ...
- 【OpenGL】代码记录01创建窗口
创建空窗口: #include<iostream> // GLEW #define GLEW_STATIC #include <GL/glew.h> // GLFW #incl ...
- Element-UI标签页el-tabs组件的拖动排序实现
ElementUI的标签页组件支持动态添加删除,如下图: 但是这个组件不支持标签之间的拖动排序.那么我们自己怎样实现这个功能呢? 有一个叫vuedraggable的组件(https://github. ...