[转]利用Jenkins的Pipeline实现集群自动化部署SpringBoot项目
环境准备
- Git: 安装部署使用略。
- Jenkins: 2.46.2版本安装部署略(修改jenkins执行用户为root,省得配置权限)
- JDK: 安装部署略。
- Maven: 安装部署略。
- 服务器免密登陆
Jenkinsfile文件编写
node {
def mvnHome
def workspace = pwd()
stage('Preparation') { // for display purposes
// Get some code from a GitHub repository
git 'http://192.168.161.118:8080/git/demo.git'
// Get the Maven tool.
// ** NOTE: This 'M3' Maven tool must be configured
// ** in the global configuration.
mvnHome = tool 'M3'
}
stage('Build') {
// Run the maven build
if (isUnix()) {
sh "'${mvnHome}/bin/mvn' -Dmaven.test.failure.ignore clean package"
} else {
bat(/"${mvnHome}\bin\mvn" -Dmaven.test.failure.ignore clean package/)
}
}
stage('Deploy') {
sh "'/scripts/deploy.sh' ${workspace} deploy"
}
}
Jenkinsfile文件就放在你自己的Git仓库的更目录! 如图: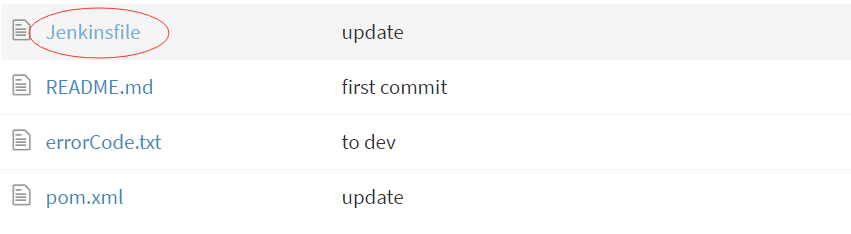
在Jenkins中创建Pipeline项目
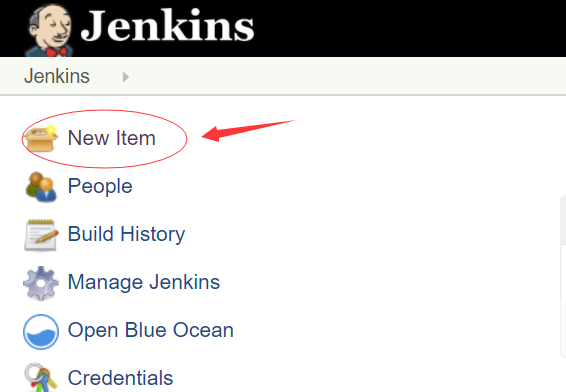
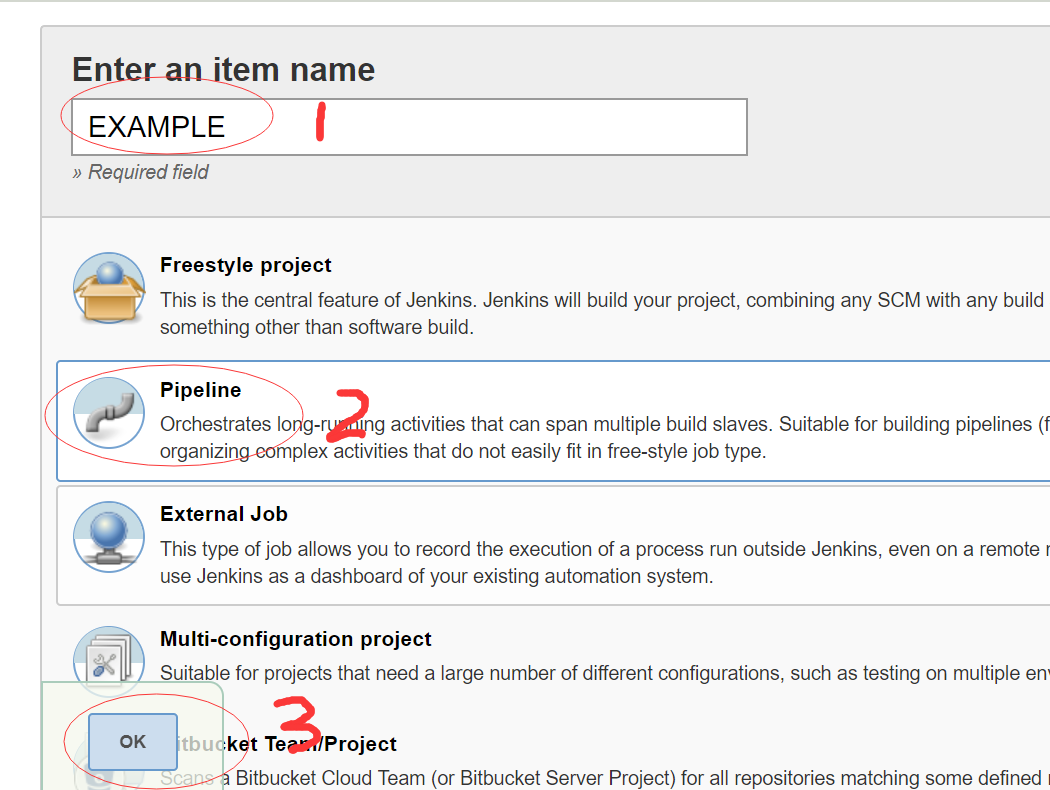
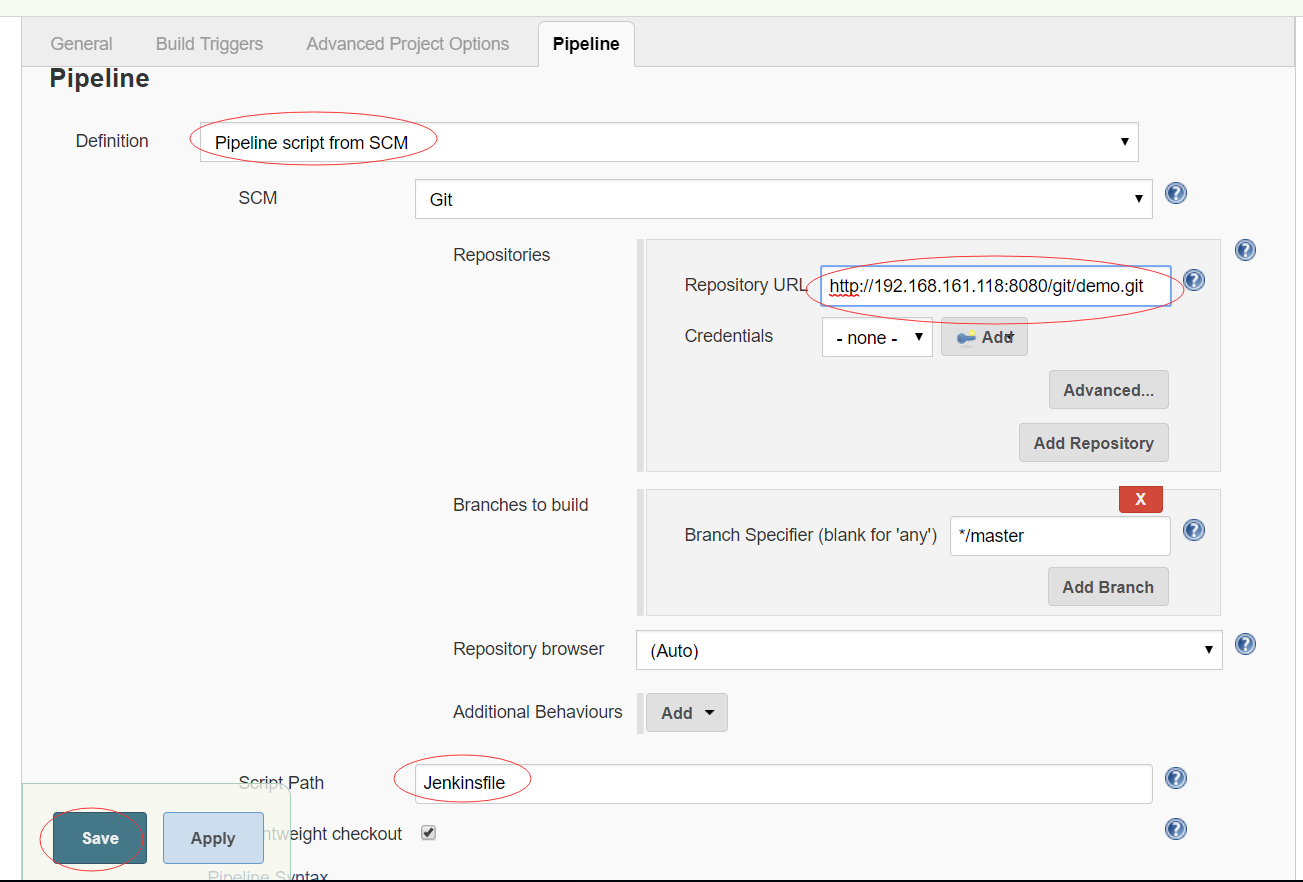 如上3图,3步,jenkins的pipeline项目创建完成。
如上3图,3步,jenkins的pipeline项目创建完成。
编写部署Shell脚本
#!/bin/bash
#集群IP列表,多个用空格分开
#NODE_LIST="192.168.161.118 192.168.161.117"
NODE_LIST="192.168.161.245"
#应用部署到的远程服务器目录
REMOTE_DIR="/home/project"
#需要部署的项目名称(需和maven的project名一样,多个用空格分开)
#NEED_DEPLOY_PROJECT="user-server user-mgr info-mgr"
NEED_DEPLOY_PROJECT="user-mgr"
# Date/Time Veriables
LOG_DATE='date "+%Y-%m-%d"'
LOG_TIME='date "+%H:%M:%S"'
CDATE=$(date "+%Y%m%d")
CTIME=$(date "+%H%M%S")
#Shell Env
SHELL_NAME="deploy.sh"
SHELL_DIR="/deploy/log"
SHELL_LOG="${SHELL_DIR}/${SHELL_NAME}.log"
#Code Env
JAR_DIR="/deploy/jar"
CONFIG_DIR="/deploy/config"
LOCK_FILE="/tmp/deploy.lock"
usage(){
echo $"Usage: $0 [projectJarPath] [ deploy | rollback ]"
}
init() {
create_dir $SHELL_DIR;
create_dir $JAR_DIR;
create_dir $CONFIG_DIR;
}
create_dir() {
if [ ! -d $1 ]; then
mkdir -p $1
fi
}
shell_lock(){
touch ${LOCK_FILE}
}
shell_unlock(){
rm -f ${LOCK_FILE}
}
write_log(){
LOGINFO=$1
echo "`eval ${LOG_DATE}` `eval ${LOG_TIME}` : ${SHELL_NAME} : ${LOGINFO}"|tee -a ${SHELL_LOG}
}
#拷贝jenkins的工作空间构建的jar包到特定目录,备份,为以后回滚等等操作
copy_jar() {
TARGET_DIR=${JAR_DIR}/${CDATE}${CTIME}
write_log "Copy jenkins workspace jar file to ${TARGET_DIR}"
mkdir -p $TARGET_DIR
for project in $NEED_DEPLOY_PROJECT;do
mkdir -p $TARGET_DIR/${project}
find $1 -name ${project}*.jar -exec cp {} $TARGET_DIR/${project}/ \;
done
}
#拷贝应用的jar包到远程服务器
scp_jar(){
SOURCE_DIR=${JAR_DIR}/${CDATE}${CTIME}
write_log "Scp jar file to remote machine..."
for node in $NODE_LIST;do
scp -r ${SOURCE_DIR}/* $node:${REMOTE_DIR}
write_log "Scp to ${node} complete."
done
}
# 杀掉远程服务器上正在运行的项目
cluster_node_remove(){
write_log "Kill all runing project on the cluster..."
for project in $NEED_DEPLOY_PROJECT;do
for node in $NODE_LIST;do
pid=$(ssh $node "ps aux|grep ${project}|grep -v grep|awk '{print $2}'"|awk '{print $2}')
if [ ! -n "$pid" ]; then
write_log "${project} is not runing..."
else
ssh $node "kill -9 $pid"
write_log "Killed ${project} at ${node}..."
fi
done
done
}
#在远程服务器上启动项目
cluster_deploy(){
write_log "Up all project on the cluster..."
for project in $NEED_DEPLOY_PROJECT;do
for node in $NODE_LIST;do
ssh $node "cd ${REMOTE_DIR}/${project};nohup java -jar ${project}*.jar >/dev/null 2>&1 &"
write_log "Up ${project} on $node complete..."
done
done
}
#回滚(暂未实现)
rollback(){
echo rollback
}
#入口
main(){
if [ -f ${LOCK_FILE} ];then
write_log "Deploy is running" && exit;
fi
WORKSPACE=$1
DEPLOY_METHOD=$2
init;
case $DEPLOY_METHOD in
deploy)
shell_lock;
copy_jar $WORKSPACE;
scp_jar;
cluster_node_remove;
cluster_deploy;
shell_unlock;
;;
rollback)
shell_lock;
rollback;
shell_unlock;
;;
*)
usage;
esac
}
main $1 $2
PS: deploy.sh放在/scripts目录,和JenkinsFile中写的路径一致就好
运行看效果
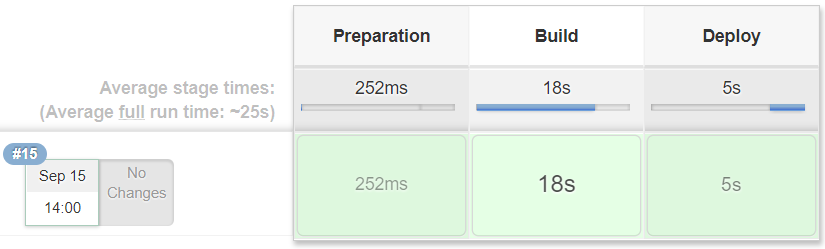 部署成功。。。
部署成功。。。 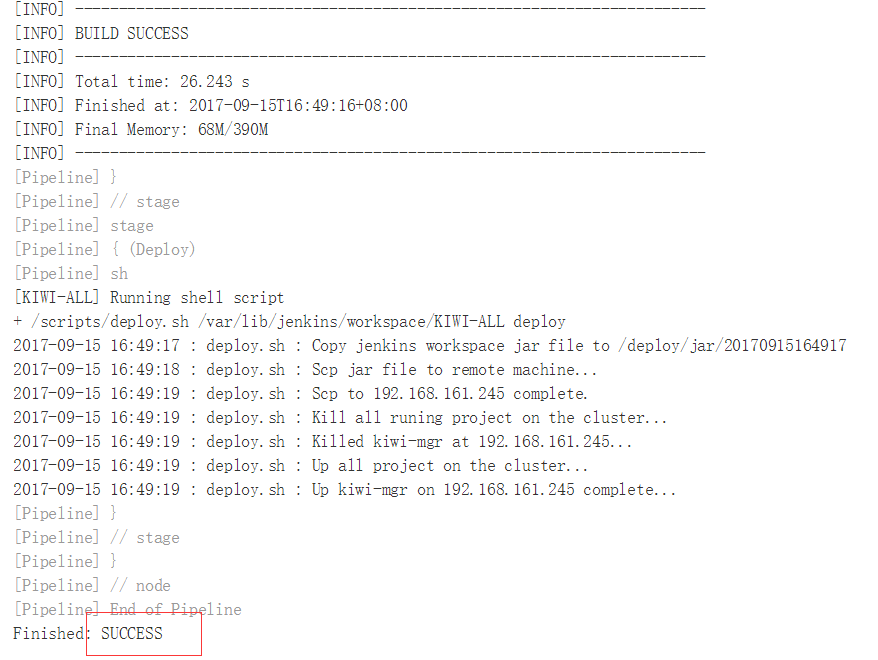 Jenkins的Console Output也都打印成功。
Jenkins的Console Output也都打印成功。  浏览器访问部署的应用也一切正常。完事!
浏览器访问部署的应用也一切正常。完事!
PS:本实践适合小型集群部署。(经验有限,欢迎大神指导)
[转]利用Jenkins的Pipeline实现集群自动化部署SpringBoot项目的更多相关文章
- MySQL主从复制原理及配置详细过程以及主从复制集群自动化部署的实现
一.复制概述 Mysql内建的复制功能是构建大型,高性能应用程序的基础.将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台主机的数据复制到其它主机(slaves)上,并重 ...
- Asp.net Core 使用Jenkins + Dockor 实现持续集成、自动化部署(三):搭建jenkins集群环境
写在前面 大家可以看到本文的配图,左边是jenkins单机环境,右边是jenkins集群.个中区别,不言而喻,形象生动. 前面我分别介绍了.net core 程序的多种部署方式(无绝对孰优孰劣): 1 ...
- linux集群自动化搭建(生成密钥对+分发公钥+远程批量执行脚本)
之前介绍过ansible的使用,通过ssh授权批量控制服务器集群 但是生成密钥和分发公钥的时候都是需要确认密码的,这一步也是可以自动化的,利用ssh + expect + scp就可以实现,其实只用这 ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- ProxySQL Cluster 高可用集群环境部署记录
ProxySQL在早期版本若需要做高可用,需要搭建两个实例,进行冗余.但两个ProxySQL实例之间的数据并不能共通,在主实例上配置后,仍需要在备用节点上进行配置,对管理来说非常不方便.但是Proxy ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- vivo大规模 Kubernetes 集群自动化运维实践
作者:vivo 互联网服务器团队-Zhang Rong 一.背景 随着vivo业务迁移到K8s的增长,我们需要将K8s部署到多个数据中心.如何高效.可靠的在数据中心管理多个大规模的K8s集群是我们面临 ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
随机推荐
- 问题 1923: [蓝桥杯][算法提高VIP]学霸的迷宫 (BFS)
题目链接:https://www.dotcpp.com/oj/problem1923.html 题目描述 学霸抢走了大家的作业,班长为了帮同学们找回作业,决定去找学霸决斗.但学霸为了不要别人打扰,住在 ...
- css3 box-flex
应用地址:http://www.jb51.net/css/467291.html box-flex是css3新添加的盒子模型属性,它的出现打破了我们经常使用的浮动布局,实现垂直等高.水平均分.按比例划 ...
- parse
import Parse from 'parse'; import { AsyncStorage } from 'react-native'; // 创建新的子类 var GameScore = Pa ...
- 51nod1268 和为K的组合(DFS)
1268 和为K的组合 基准时间限制:1 秒 空间限制:131072 KB 分值: 20 难度:3级算法题 收藏 关注 给出N个正整数组成的数组A,求能否从中选出若干个,使他们的和为K.如果可以 ...
- Linux 下的分屏利器-tmux安装、原理及使用
>> 原文地址
- nodejs基础快速上手
node 快速了解 hello node.js console.log("hello Node.js"); let http = require("http") ...
- [十二省联考2019]骗分过样例 luoguP5285 loj#3050
不解释(因为蒟蒻太弱了,肝了一晚受不了了...现在省选退役,这有可能就是我做的最后一题了... #include<bits/stdc++.h> using namespace std; # ...
- JavaScript 中的 FileReader
在不经过服务器的时候,本地预览照片,当确定以后再上传 它是H5提供的构造函数 用法: <input type='file'> <img src='' alt=''> <s ...
- 记python使用grpc
using grpc in Python gRPC是基于http/2的RPC框架,使用ProtoBuf作为底层数据序列化.Nginx服务器2018年3月17日引入gRPC支持. gRPC 是用来实现跨 ...
- spring boot 2使用Mybatis多表关联查询
模拟业务关系:一个用户user有对应的一个公司company,每个用户有多个账户account. spring boot 2的环境搭建见上文:spring boot 2整合mybatis 一.mysq ...