jieba库初级应用
1、jieba库基本介绍
(1)、jieba库概述
jieba是优秀的中文分词第三方库
- 中文文本需要通过分词获得单个的词语
- jieba是优秀的中文分词第三方库,需要额外安装
- jieba库提供三种分词模式,最简单只需掌握一个函数
(2)、jieba分词的原理
Jieba分词依靠中文词库
- 利用一个中文词库,确定汉字之间的关联概率
- 汉字间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
2、jieba库使用说明
(1)、jieba分词的三种模式
精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
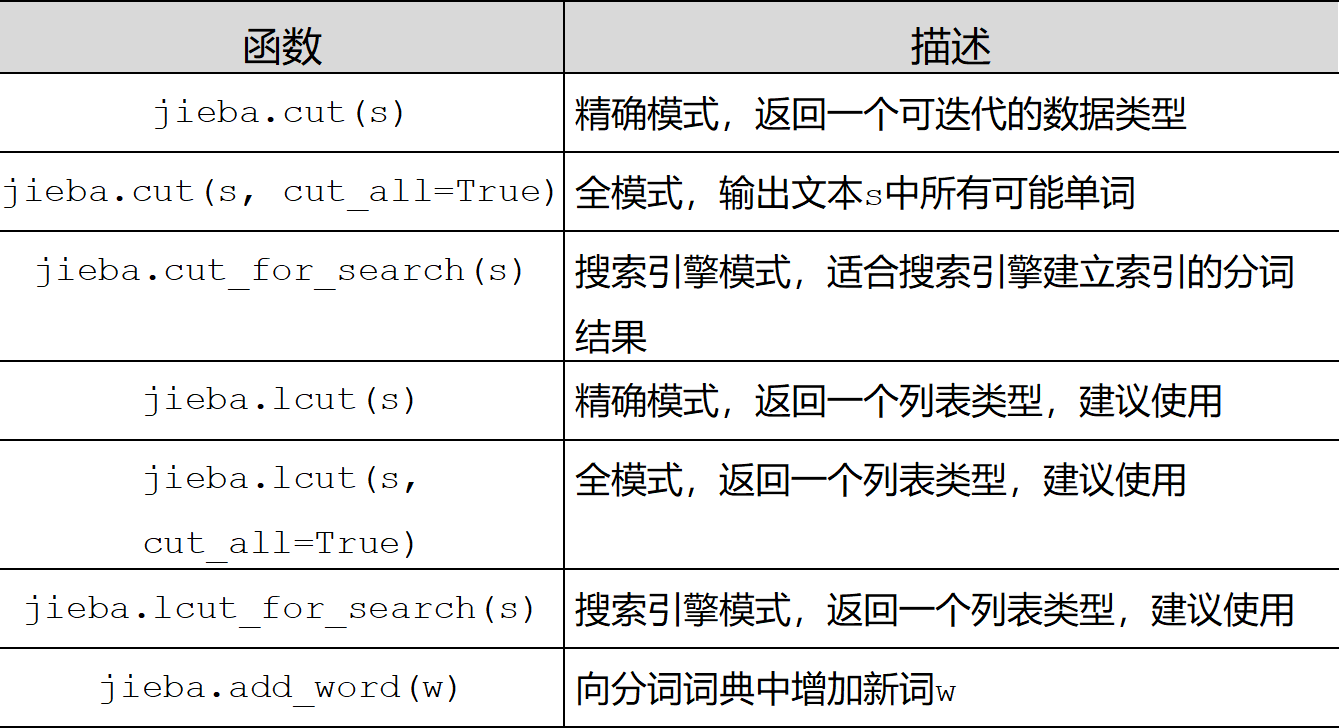
(2)、jieba库常用函数
3.利用jieba库统计挪威的森林词频统计
1、首先下载挪威的森林.txt才能在python中打开
import jieba
txt=open("D:\\123.txt","r").read()
2、运用jieba库得到分词,且加入一个计数数组
words=jieba.lcut(txt)
counts={}
3、历遍全文计数词语出现次数
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
4、将键值对转换成链表,且将词语出现的次数由大到小排序
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
5、输出链表
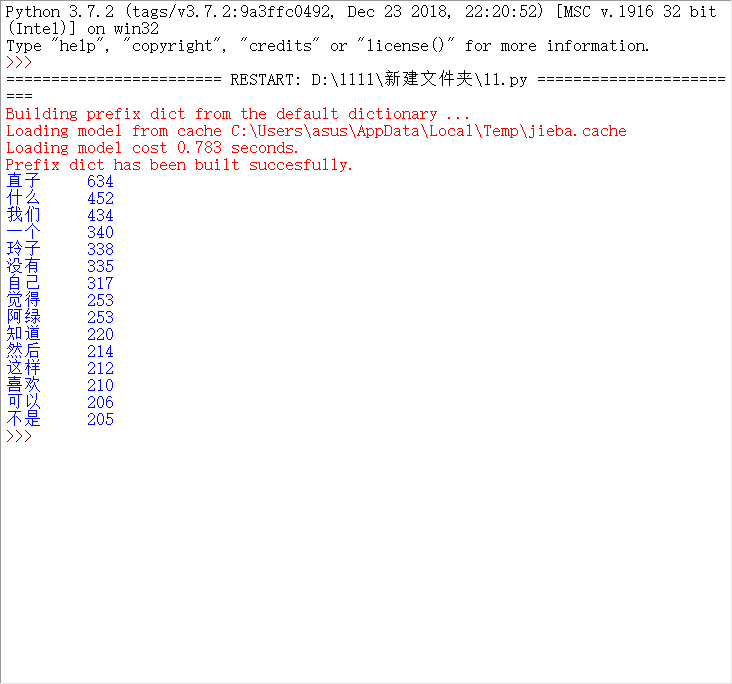
for i in range(15):
word,count=items[i]
print("{0:<5}{1:>5}".format(word,count))
总代码
import jieba
txt=open("D:\\123.txt","r").read()
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(15):
word,count=items[i]
print("{0:<5}{1:>5}".format(word,count))
结果:
jieba库初级应用的更多相关文章
- jieba库词频统计练习
在sypder上运行jieba库的代码: import matplotlib.pyplot as pltfracs = [2,2,1,1,1]labels = 'houqin', 'jiemian', ...
- 如何运用jieba库分词
使用jieba库分词 一.什么是jieba库 1.jieba库概述 jieba是优秀的中文分词第三方库,中文文本需要通过分词获得单个词语. 2.jieba库的使用:(jieba库支持3种分词模式) 通 ...
- jieba库
Note of Jieba ( 词云图实例 ) Note of Jieba jieba库是python 一个重要的第三方中文分词函数库,但需要用户自行安装. 一.jieba 库简介 (1) jieba ...
- jieba库与好玩的词云的学习与应用实现
经过了一些学习与一些十分有意义的锻(zhe)炼(mo),我决定尝试一手新接触的python第三方库 ——jieba库! 这是一个极其优秀且强大的第三方库,可以对一个文本文件的所有内容进行识别,分词,甚 ...
- jieba库的使用与词频统计
1.词频统计 (1)词频分析是对文章中重要词汇出现的次数进行统计与分析,是文本 挖掘的重要手段.它是文献计量学中传统的和具有代表性的一种内容分析方法,基本原理是通过词出现频次多少的变化,来确定热点及其 ...
- 广师大学习笔记之文本统计(jieba库好玩的词云)
1.jieba库,介绍如下: (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定 ...
- jieba 库的使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- 用jieba库统计文本词频及云词图的生成
一.安装jieba库 :\>pip install jieba #或者 pip3 install jieba 二.jieba库解析 jieba库主要提供提供分词功能,可以辅助自定义分词词典. j ...
- jieba库和好玩的词云
首先,通过pip3 install jieba安装jieba库,随后在网上下载<斗破>. 代码如下: import jieba.analyse path = '小说路径' fp = ope ...
随机推荐
- HDFS组件性能调优:数据平衡
生产系统中什么情况下会添加一个节点呢? 1 增加存储能力 disk 2 增加计算能力 cpu mem 如果增加是的是存储能力,说明存储已接近饱和或者说过段时间就会没有剩余的空间给作业来用.新加的节点存 ...
- 利用Oracle Database Resource Manager实现UNDO表空间的quota
1.查出当前使用的是哪个resource plan select * from GV$RSRC_PLAN 2.创建pending area begin dbms_resource_manager.c ...
- sql 生成随机字符串
生成三位随机字母+12位数字 ),), @c int; select @CardCode=abs(CHECKSUM(NEWID())) -LEN(@CardCode); ,@c)) set @Card ...
- cygwin vim can't write .viminfo
问题 每次退出vim时,都提示 vim can't wirte .viminfo 运行环境 以管理员身份登录win7,并运行cygwin 排查过程 切换到家目录,查看发现.viminfo文件存在. 查 ...
- pytorch使用不完全文档
1. 利用tensorboard看loss: tensorflow和pytorch环境是好的的话,链接中的logger.py拉到自己的工程里,train.py里添加相应代码,直接能用. 关于环境,小小 ...
- IP通信基础学习第九周
H3C单臂路由: 交换机的所有接口是在同一个广播域 用vlan进行隔离广播域 创建vlan,display可查看是否创建成功 进入接口是Interface,配置接口Port 先测试相同的vlan ,可 ...
- 微信小程序数组对象
xml:<block wx:for="{{post_key}}" wx:for-item="{{item}}"></block> dat ...
- Flutter数据库Sqflite之增删改查
Flutter数据库Sqflite之增删改查 简介 sqflite是Flutter的SQLite插件,支持iOS和Android,目前官方版本是sqflite1.1.3 sqflite插件地址:h ...
- mybatis的collection查询问题以及使用原生解决方案的结果
之前在springboot+mybatis环境的坑和sql语句简化技巧的第2点提到,数据库的一对多查询可以一次查询多级数据,并且把拿到的数据按id聚合,使父级表和子级表都有数据. 但是这种查询,必然要 ...
- opencv学习之路(34)、SIFT特征匹配(二)
一.特征匹配简介 二.暴力匹配 1.nth_element筛选 #include "opencv2/opencv.hpp" #include <opencv2/nonfree ...