pandas导入导出数据-【老鱼学pandas】
pandas可以读写如下格式的数据类型:
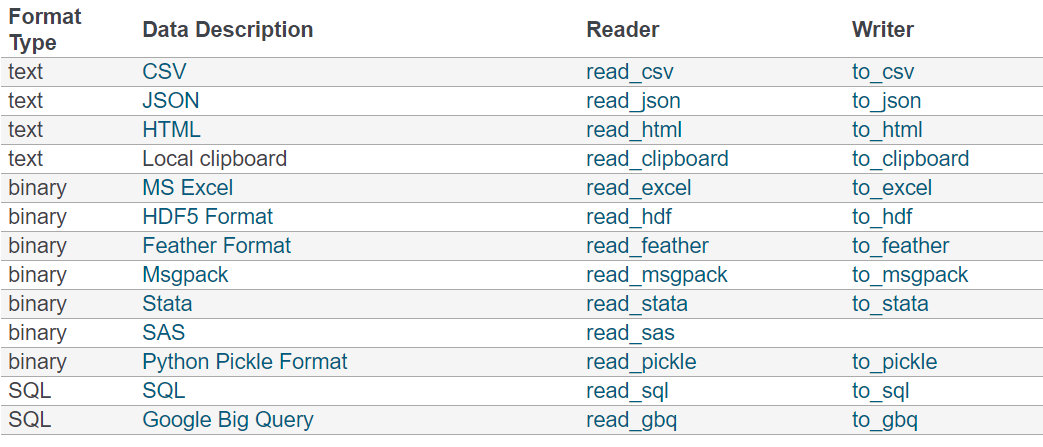
具体详见:http://pandas.pydata.org/pandas-docs/version/0.20/io.html
读取csv文件
我们准备了一个csv文件,格式类似为:

要读取此csv文件,方法为:
import pandas as pd
import numpy as np
data = pd.read_csv("D:\\data\\location.csv", encoding="GB2312")
print("data:")
print(data)
输出为:
data:
城市 小区数量 行政区 道路 门牌号 建筑年代 经度坐标 纬度坐标 开发商 平均单价 平均租金
0 包头市 1388 100 99.27 20.68 11.16 99.85 99.85 26.15 95.89 80.40
1 北京市 16194 100 99.97 50.58 67.96 99.79 99.79 57.66 98.16 94.94
2 滨州市 1765 100 99.37 28.90 0.00 76.65 76.65 7.42 95.86 50.59
3 亳州市 249 100 99.59 5.62 0.00 90.36 90.36 29.31 96.38 53.41
4 常州市 2405 100 100.00 46.90 46.32 99.41 99.41 62.82 95.01 88.93
5 成都市 12660 100 99.92 85.49 60.39 99.88 99.88 50.34 98.94 94.32
6 东莞市 2493 100 100.00 20.78 62.49 98.43 98.43 71.11 98.75 89.81
7 东营市 709 100 98.16 9.87 2.25 93.08 93.08 15.09 94.64 65.16
8 佛山市 4945 100 99.81 54.18 19.81 99.53 99.53 30.05 93.73 88.55
9 福州市 3622 100 99.94 79.65 75.06 99.86 99.86 65.18 98.28 94.97
这里我第一次尝试运行时,由于没有设置正确的encoding导致出错,大家如果发生出错可以看下csv的编码格式,到底是UTF-8的还是GB2312的。
存储
存储的方法也比较简单,用to_xxx的函数,其中xxx用相应的格式代替就可以。
比如,我们调用to_pickle函数来存储成pickle格式的数据,其中pickle格式有点类似JAVA中序列化后的文件,也就是python内部定义的格式文件。
代码很简单:
data.to_pickle("d:\\data\\location.pickle")
这样在对应的磁盘上就生成了location.pickle文件,我们用编辑器打开看一下:

一堆看不懂的乱码:)。
下次如果想要读取这个pickle文件,也很简单,方法如下:
import pandas as pd
import numpy as np
data = pd.read_pickle("D:\\data\\location.pickle")
print("data:")
print(data)
输出为:
data:
城市 小区数量 行政区 道路 门牌号 建筑年代 经度坐标 纬度坐标 开发商 平均单价 平均租金
0 包头市 1388 100 99.27 20.68 11.16 99.85 99.85 26.15 95.89 80.40
1 北京市 16194 100 99.97 50.58 67.96 99.79 99.79 57.66 98.16 94.94
2 滨州市 1765 100 99.37 28.90 0.00 76.65 76.65 7.42 95.86 50.59
3 亳州市 249 100 99.59 5.62 0.00 90.36 90.36 29.31 96.38 53.41
4 常州市 2405 100 100.00 46.90 46.32 99.41 99.41 62.82 95.01 88.93
5 成都市 12660 100 99.92 85.49 60.39 99.88 99.88 50.34 98.94 94.32
6 东莞市 2493 100 100.00 20.78 62.49 98.43 98.43 71.11 98.75 89.81
7 东营市 709 100 98.16 9.87 2.25 93.08 93.08 15.09 94.64 65.16
8 佛山市 4945 100 99.81 54.18 19.81 99.53 99.53 30.05 93.73 88.55
9 福州市 3622 100 99.94 79.65 75.06 99.86 99.86 65.18 98.28 94.97
pandas导入导出数据-【老鱼学pandas】的更多相关文章
- pandas基本介绍-【老鱼学pandas】
前面我们学习了numpy,现在我们来学习一下pandas. Python Data Analysis Library 或 pandas 主要用于处理类似excel一样的数据格式,其中有表头.数据序列号 ...
- pandas设置值-【老鱼学pandas】
本节主要讲述如何根据上篇博客中选择出相应的数据之后,对其中的数据进行修改. 对某个值进行修改 例如,我们想对数据集中第2行第2列的数据进行修改: import pandas as pd import ...
- pandas合并数据集-【老鱼学pandas】
有两个数据集,我们想把他们的结果根据相同的列名或索引号之类的进行合并,有点类似SQL中的从两个表中选择出不同的记录并进行合并返回. 合并 首先准备数据: import pandas as pd imp ...
- pandas画图-【老鱼学pandas】
本节主要讲述如何把pandas中的数据用图表的方式显示在屏幕上,有点类似在excel中显示图表. 安装matplotlib 为了能够显示图表,首先需要安装matplotlib库,安装方法如下: pip ...
- pandas选择数据-【老鱼学pandas】
选择列 根据列名来选择某列的数据 import pandas as pd import numpy as np dates = pd.date_range("2017-01-08" ...
- pandas处理丢失数据-【老鱼学pandas】
假设我们的数据集中有缺失值,该如何进行处理呢? 丢弃缺失值的行或列 首先我们定义了数据集的缺失值: import pandas as pd import numpy as np dates = pd. ...
- pandas合并merge-【老鱼学pandas】
本节讲述对于两个数据集按照相同列的值进行合并. 首先定义原始数据: import pandas as pd import numpy as np data0 = pd.DataFrame({'key' ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- 二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案. 这里对前面的这个方案进行一些改进. 分批训练 model.fit(x_train, y_train, epochs=20, batch_size=51 ...
随机推荐
- js 实现的页面图片放大器以及 event中的诸多 x
背景: 淘宝.天猫等电商网站浏览图片时可以查看大图的功能: 思路: 思路很简单,两张图片,一张较小渲染在页面上,一张较大是细节图,随鼠标事件调整它的 left & top; 需要的知识点: o ...
- 平衡树splay学习笔记#1
这一篇博客只讲splay的前一部分的操作(rotate和splay),后面的一段博客咕咕一段时间 后一半的博客地址:[传送门] 前言骚话 为了学lct我也是拼了,看了十几篇博客,学了将近有一周,才A掉 ...
- Java大小写转化
java大写转小写 public String toLowerCase(String str){ char[] chars = str.toCharArray(); for (int i = 0; i ...
- python学习 day13 装饰器(一)&推导式
装饰器&推导式 传参位置参数在前,关键词参数在后 函数不被调用内部代码不被执行 函数在被调用的时候,每次都会开辟一个新的内存地址,互不干扰 #经典案例 def func(num): def i ...
- 使用Webstorm建立vue.js工程并添加vuetify组件
.. .. .. ..等待安装完 ..生成的目录结构 ..打开Webstorm的终端 ..最后出现 ..回到工程目录,右键 ..显示npm面板,点击serve运行 .. ..打开[貌似跟以前不一样了. ...
- 2018-2019-2 20175209 实验一《Java开发环境的熟悉》实验报告
2018-2019-2 20175209 实验一<Java开发环境的熟悉>实验报告 一.实验内容及步骤 1.使用JDK编译.运行简单的Java程序 cd 20175209进入2017520 ...
- python dic字典使用
#!/usr/bin/env python -*-''' 字典的基本组成及用法: dict={key:value} dict[key]=value 字典是无序的. key值是唯一属性,一对一,几个ke ...
- Ajax与JSON共同使用的小实例
实现的效果: 点击“点击”按钮,可以通过Ajax从服务器调过来相应的文档文件,而不需重新加载页面. 通过json可以将调过来的文档(String)转换为相应的json对象,从而对文档中数据进行操作. ...
- Go语言系列(七)- 读写操作
终端读写 1. 终端读写 操作终端相关文件句柄常量 os.Stdin:标准输入 os.Stdout:标准输出 os.Stderr:标准错误输出 2. 终端读写示例 package main impor ...
- Python 各种进制转换
#coding=gbk var=input("请输入十六进制数:") b=bin(int(var,16)) print(b[2:]) 详细请参考python自带int函数.bin函 ...