python:selenium爬取boss网站被关小黑屋
问题描述:使用selenium访问次数过多,被boss反爬封掉IP,这种方式有什么好一点的解决方法,首次可以用图形验证解封,今天访问次数过多,被关进了小黑屋
首次让我用图形界面解封
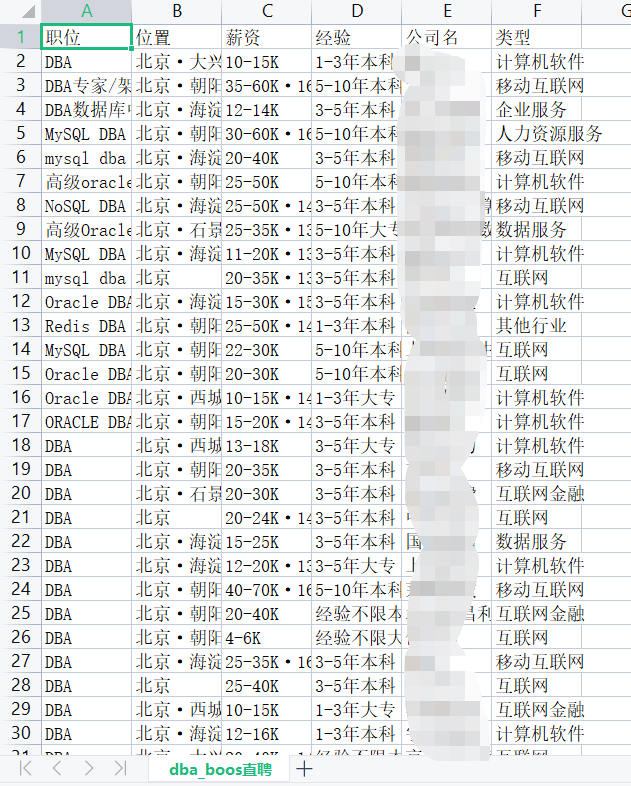
不过还好,手动解封,第一次只是个警告,后边还是顺利爬到了数据。获取北京地区有关DBA的招聘信息,使用的是selenium库来解析网页,也使用了request的方式来解析网页,但是得不到网页的真实源代码。
python:selenium爬取boss网站被关小黑屋的更多相关文章
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- Python+selenium爬取智联招聘的职位信息
整个爬虫是基于selenium和Python来运行的,运行需要的包 mysql,matplotlib,selenium 需要安装selenium火狐浏览器驱动,百度的搜寻. 整个爬虫是模块化组织的,不 ...
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- [原创]python+beautifulsoup爬取整个网站的仓库列表与仓库详情
from bs4 import BeautifulSoup import requests import os def getdepotdetailcontent(title,url):#爬取每个仓库 ...
- Python多线程爬取某网站表情包
# 爬取网络图片import requestsfrom lxml import etreefrom urllib import requestfrom queue import Queue # 导入队 ...
- python selenium 爬取淘宝
# -*- coding:utf-8 -*- # author : yesehngbao # time:2018/3/29 import re import pymongo from lxml imp ...
- python selenium爬取QQ空间方法
from selenium import webdriver import time # 打开浏览器 dr = webdriver.Chrome() # 打开某个网址 dr.get('https:// ...
随机推荐
- 解决VSCode无法显示Unity代码提示和源代码
1,先删除项目目录下的配置文件,也可以理解为除文件夹外的其他文件 2,先把vscode选中,下拉框中没有vscode的找到文件就可以导进来再选中.然后红框里的不要勾选,因为我是这么做的,你也可以试着勾 ...
- 04 Hadoop思想与原理
Hadoop最早起源于Nutch.Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取.索引.查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题--如何解决数十亿网页的存储和索引 ...
- jsp第5个作业
login.jsp <%@ page language="java" import="java.util.*" pageEncoding="ut ...
- Selenium显式、隐式等待
显式等待: 显式等待是你在代码中定义等待一定条件发生后再进一步执行你的代码.简单的说就是在指定时间内,一直等待某个条件成立,条件成立后立即执行定位元素的操作:如果超过这个时间条件仍然没有成立,则会抛出 ...
- 10.14 2020 实验 7:OpenDaylight 实验——Python 中的 REST API 调用
一.实验目的 对 Python 调用 OpenDaylight 的 REST API 方法有初步了解. 二.实验任务 本实验需要用另一种方法完成上一个实验相同的功能,即通过 Python 程序 ...
- Matlab %补充---用的多的函数
Input promat = 'This is a sentence.' x = input(prompt) %显示prompt中的文本并等待用户输入数值或者表达式后按Return %如果用户什么都 ...
- C#清空控件的值
/// 清除容器里面某些控件的值 /// </summary> /// <param name="parContainer">容器类控件</param ...
- pandas加速读取数据记录csv大文件处理
def readf(file): t0 = time.time() data=pd.read_csv(file,low_memory=False,encoding='gbk' #,nrows=100 ...
- Linux部分文件管理类命令
1.创建空文件和刷新时间 touch命令可以用来创建空文件或刷新文件的时间 touch [OPTION]... FILE... 选项: -a 仅改变atime和ctime -m 仅改变mtime和ct ...
- 使用ipmitool配置ipmi(远程控制卡)
使用ipmitool配置ipmi(远程控制卡) 在centos安装OpenIPMI: yum install OpenIPMI OpenIPMI-tools 设置开机启动 chkconfig ipmi ...